Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Neural Network Parameter Initialization Into an SMT Problem
Paper and Code
Nov 09, 2020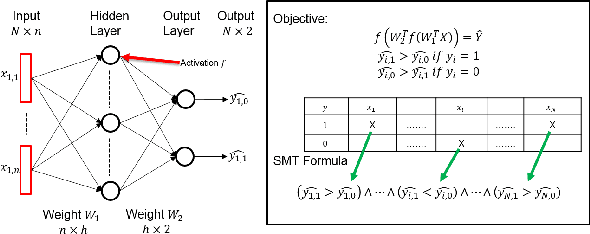
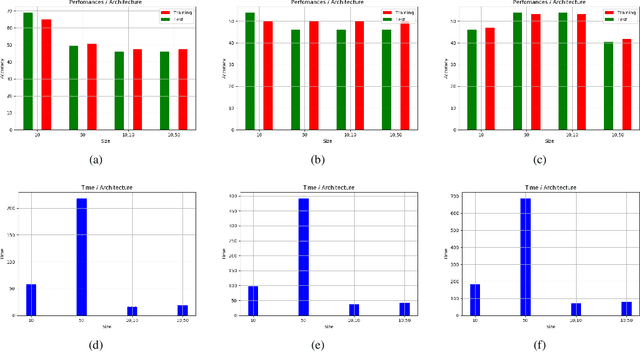
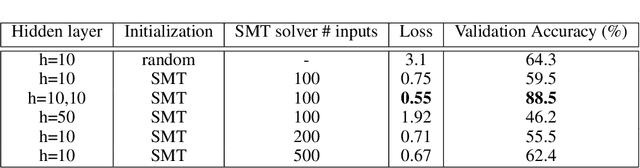
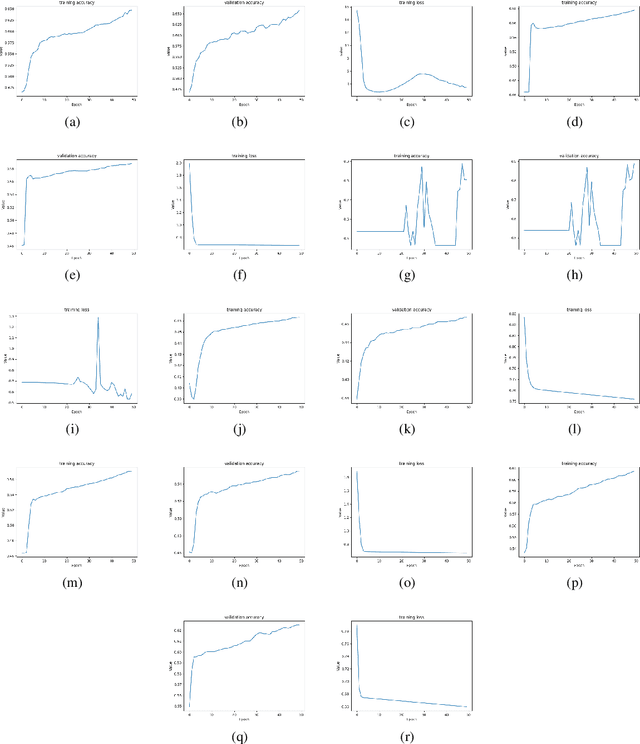
Training a neural network (NN) depends on multiple factors, including but not limited to the initial weights. In this paper, we focus on initializing deep NN parameters such that it performs better, comparing to random or zero initialization. We do this by reducing the process of initialization into an SMT solver. Previous works consider certain activation functions on small NNs, however the studied NN is a deep network with different activation functions. Our experiments show that the proposed approach for parameter initialization achieves better performance comparing to randomly initialized networks.
* AAAI-21 SA Program
View paper on