 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Spatially Varying Pixel Exposures for Motion Deblurring
Apr 14, 2022

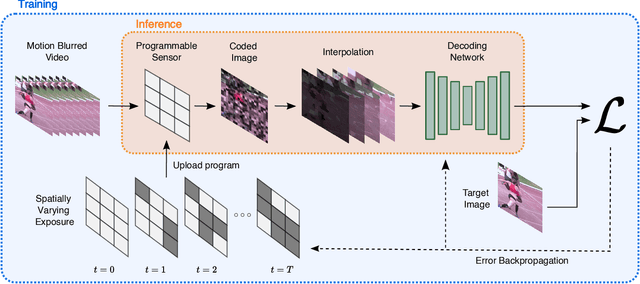

Computationally removing the motion blur introduced by camera shake or object motion in a captured image remains a challenging task in computational photography. Deblurring methods are often limited by the fixed global exposure time of the image capture process. The post-processing algorithm either must deblur a longer exposure that contains relatively little noise or denoise a short exposure that intentionally removes the opportunity for blur at the cost of increased noise. We present a novel approach of leveraging spatially varying pixel exposures for motion deblurring using next-generation focal-plane sensor--processors along with an end-to-end design of these exposures and a machine learning--based motion-deblurring framework. We demonstrate in simulation and a physical prototype that learned spatially varying pixel exposures (L-SVPE) can successfully deblur scenes while recovering high frequency detail. Our work illustrates the promising role that focal-plane sensor--processors can play in the future of computational imaging.
MantissaCam: Learning Snapshot High-dynamic-range Imaging with Perceptually-based In-pixel Irradiance Encoding
Dec 09, 2021
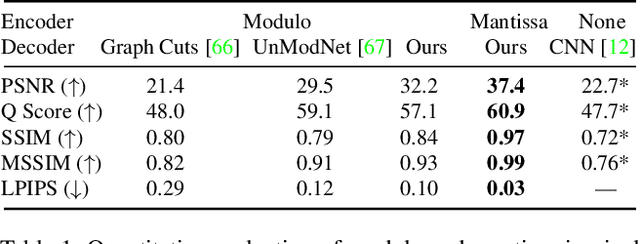
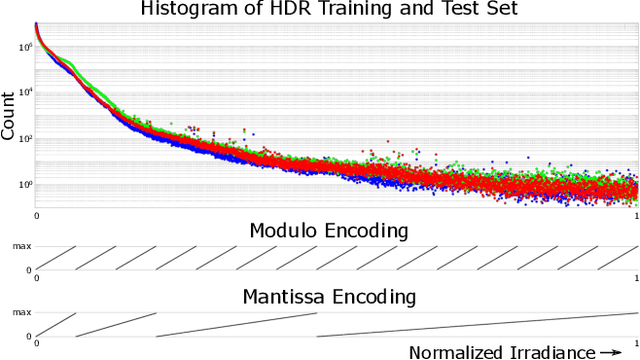

The ability to image high-dynamic-range (HDR) scenes is crucial in many computer vision applications. The dynamic range of conventional sensors, however, is fundamentally limited by their well capacity, resulting in saturation of bright scene parts. To overcome this limitation, emerging sensors offer in-pixel processing capabilities to encode the incident irradiance. Among the most promising encoding schemes is modulo wrapping, which results in a computational photography problem where the HDR scene is computed by an irradiance unwrapping algorithm from the wrapped low-dynamic-range (LDR) sensor image. Here, we design a neural network--based algorithm that outperforms previous irradiance unwrapping methods and, more importantly, we design a perceptually inspired "mantissa" encoding scheme that more efficiently wraps an HDR scene into an LDR sensor. Combined with our reconstruction framework, MantissaCam achieves state-of-the-art results among modulo-type snapshot HDR imaging approaches. We demonstrate the efficacy of our method in simulation and show preliminary results of a prototype MantissaCam implemented with a programmable sensor.
ACORN: Adaptive Coordinate Networks for Neural Scene Representation
May 06, 2021
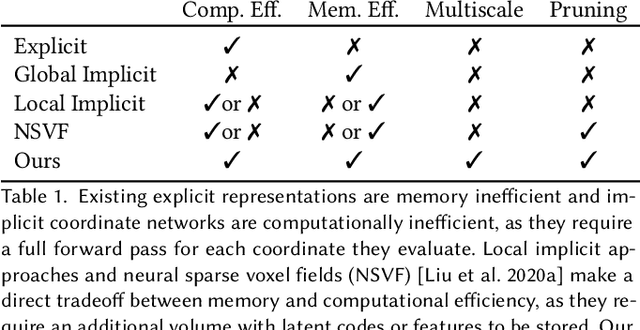
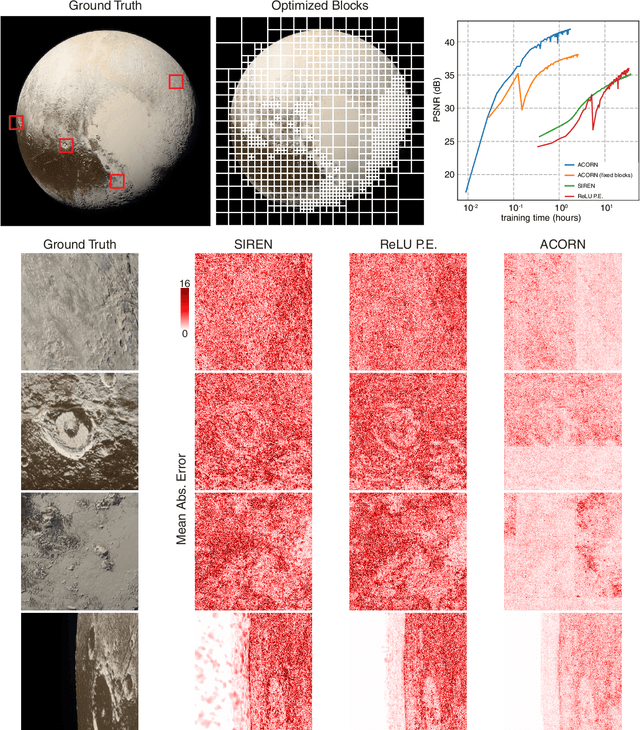
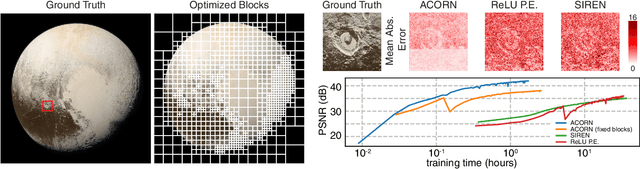
Neural representations have emerged as a new paradigm for applications in rendering, imaging, geometric modeling, and simulation. Compared to traditional representations such as meshes, point clouds, or volumes they can be flexibly incorporated into differentiable learning-based pipelines. While recent improvements to neural representations now make it possible to represent signals with fine details at moderate resolutions (e.g., for images and 3D shapes), adequately representing large-scale or complex scenes has proven a challenge. Current neural representations fail to accurately represent images at resolutions greater than a megapixel or 3D scenes with more than a few hundred thousand polygons. Here, we introduce a new hybrid implicit-explicit network architecture and training strategy that adaptively allocates resources during training and inference based on the local complexity of a signal of interest. Our approach uses a multiscale block-coordinate decomposition, similar to a quadtree or octree, that is optimized during training. The network architecture operates in two stages: using the bulk of the network parameters, a coordinate encoder generates a feature grid in a single forward pass. Then, hundreds or thousands of samples within each block can be efficiently evaluated using a lightweight feature decoder. With this hybrid implicit-explicit network architecture, we demonstrate the first experiments that fit gigapixel images to nearly 40 dB peak signal-to-noise ratio. Notably this represents an increase in scale of over 1000x compared to the resolution of previously demonstrated image-fitting experiments. Moreover, our approach is able to represent 3D shapes significantly faster and better than previous techniques; it reduces training times from days to hours or minutes and memory requirements by over an order of magnitude.
Time-Multiplexed Coded Aperture Imaging: Learned Coded Aperture and Pixel Exposures for Compressive Imaging Systems
Apr 06, 2021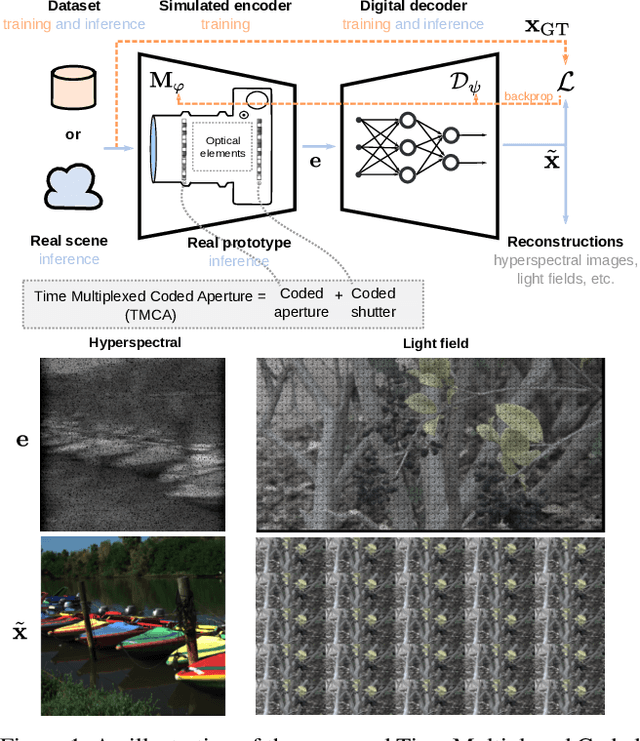
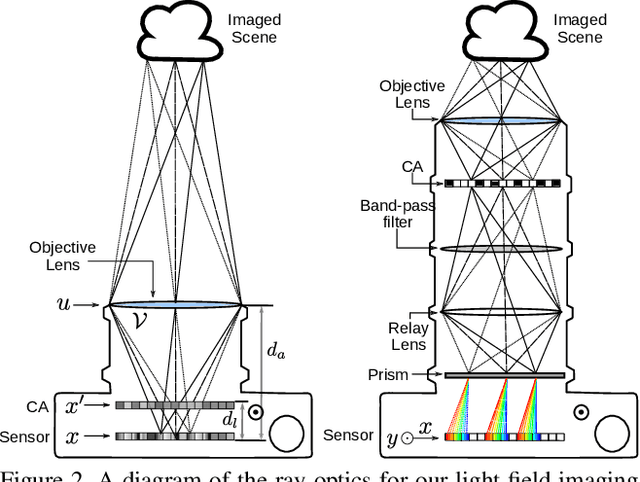
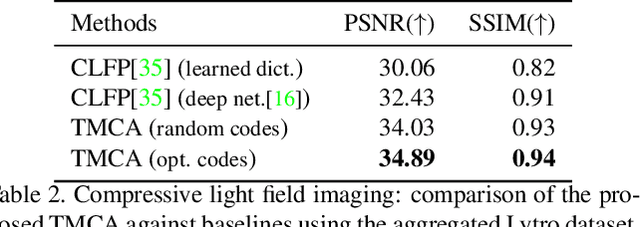

Compressive imaging using coded apertures (CA) is a powerful technique that can be used to recover depth, light fields, hyperspectral images and other quantities from a single snapshot. The performance of compressive imaging systems based on CAs mostly depends on two factors: the properties of the mask's attenuation pattern, that we refer to as "codification" and the computational techniques used to recover the quantity of interest from the coded snapshot. In this work, we introduce the idea of using time-varying CAs synchronized with spatially varying pixel shutters. We divide the exposure of a sensor into sub-exposures at the beginning of which the CA mask changes and at which the sensor's pixels are simultaneously and individually switched "on" or "off". This is a practically appealing codification as it does not introduce additional optical components other than the already present CA but uses a change in the pixel shutter that can be easily realized electronically. We show that our proposed time multiplexed coded aperture (TMCA) can be optimized end-to-end and induces better coded snapshots enabling superior reconstructions in two different applications: compressive light field imaging and hyperspectral imaging. We demonstrate both in simulation and on real captures (taken with prototypes we built) that this codification outperforms the state-of-the-art compressive imaging systems by more than 4dB in those applications.
AutoInt: Automatic Integration for Fast Neural Volume Rendering
Dec 03, 2020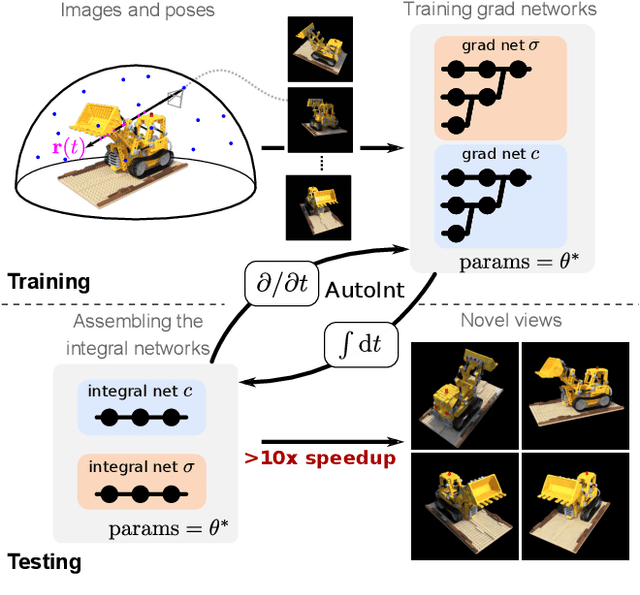
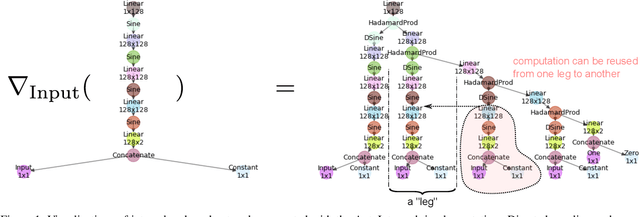
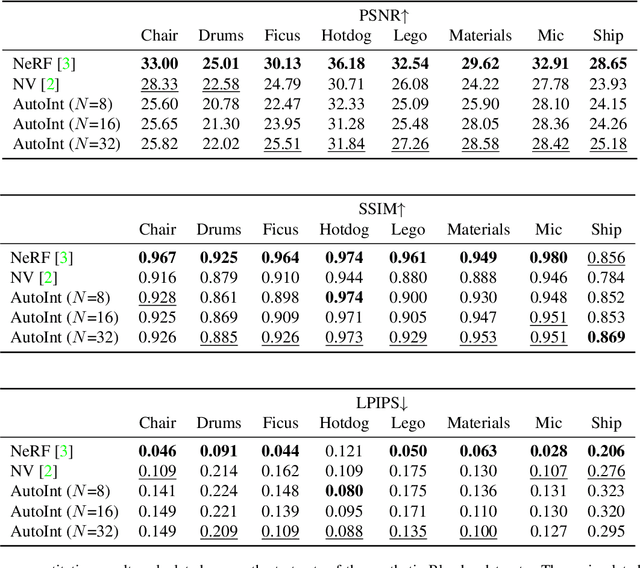
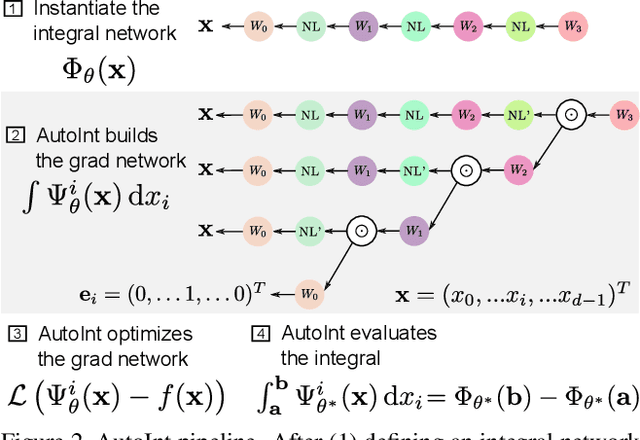
Numerical integration is a foundational technique in scientific computing and is at the core of many computer vision applications. Among these applications, implicit neural volume rendering has recently been proposed as a new paradigm for view synthesis, achieving photorealistic image quality. However, a fundamental obstacle to making these methods practical is the extreme computational and memory requirements caused by the required volume integrations along the rendered rays during training and inference. Millions of rays, each requiring hundreds of forward passes through a neural network are needed to approximate those integrations with Monte Carlo sampling. Here, we propose automatic integration, a new framework for learning efficient, closed-form solutions to integrals using implicit neural representation networks. For training, we instantiate the computational graph corresponding to the derivative of the implicit neural representation. The graph is fitted to the signal to integrate. After optimization, we reassemble the graph to obtain a network that represents the antiderivative. By the fundamental theorem of calculus, this enables the calculation of any definite integral in two evaluations of the network. Using this approach, we demonstrate a greater than 10x improvement in computation requirements, enabling fast neural volume rendering.
Implicit Neural Representations with Periodic Activation Functions
Jun 17, 2020
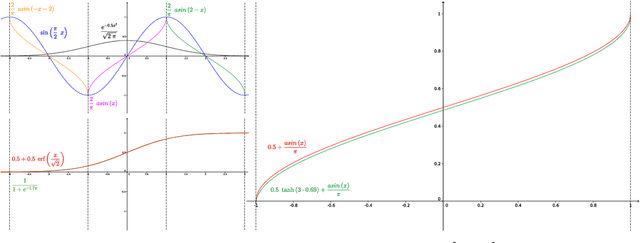

Implicitly defined, continuous, differentiable signal representations parameterized by neural networks have emerged as a powerful paradigm, offering many possible benefits over conventional representations. However, current network architectures for such implicit neural representations are incapable of modeling signals with fine detail, and fail to represent a signal's spatial and temporal derivatives, despite the fact that these are essential to many physical signals defined implicitly as the solution to partial differential equations. We propose to leverage periodic activation functions for implicit neural representations and demonstrate that these networks, dubbed sinusoidal representation networks or Sirens, are ideally suited for representing complex natural signals and their derivatives. We analyze Siren activation statistics to propose a principled initialization scheme and demonstrate the representation of images, wavefields, video, sound, and their derivatives. Further, we show how Sirens can be leveraged to solve challenging boundary value problems, such as particular Eikonal equations (yielding signed distance functions), the Poisson equation, and the Helmholtz and wave equations. Lastly, we combine Sirens with hypernetworks to learn priors over the space of Siren functions.
Event Based, Near Eye Gaze Tracking Beyond 10,000Hz
Apr 07, 2020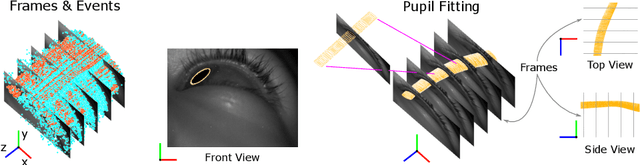
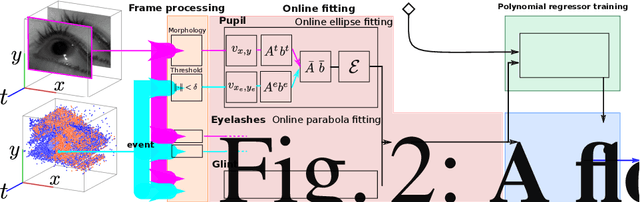
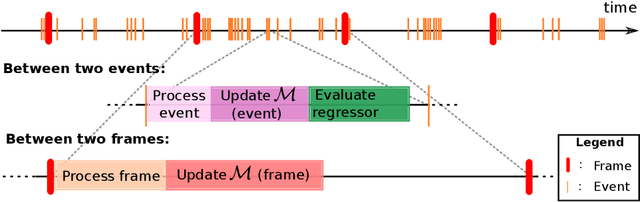

Fast and accurate eye tracking is crucial for many applications. Current camera-based eye tracking systems, however, are fundamentally limited by their bandwidth, forcing a tradeoff between image resolution and framerate, i.e. between latency and update rate. Here, we propose a hybrid frame-event-based near-eye gaze tracking system offering update rates beyond 10,000 Hz with an accuracy that matches that of high-end desktop-mounted commercial eye trackers when evaluated in the same conditions. Our system builds on emerging event cameras that simultaneously acquire regularly sampled frames and adaptively sampled events. We develop an online 2D pupil fitting method that updates a parametric model every one or few events. Moreover, we propose a polynomial regressor for estimating the gaze vector from the parametric pupil model in real time. Using the first hybrid frame-event gaze dataset, which will be made public, we demonstrate that our system achieves accuracies of 0.45 degrees -- 1.75 degrees for fields of view ranging from 45 degrees to 98 degrees.
Estimation of Z-Thickness and XY-Anisotropy of Electron Microscopy Images using Gaussian Processes
Feb 04, 2020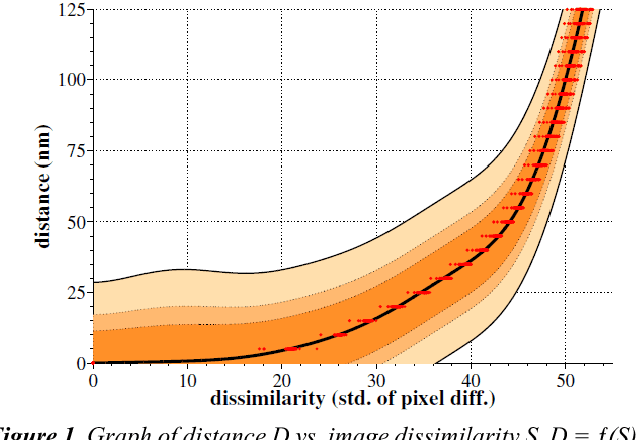

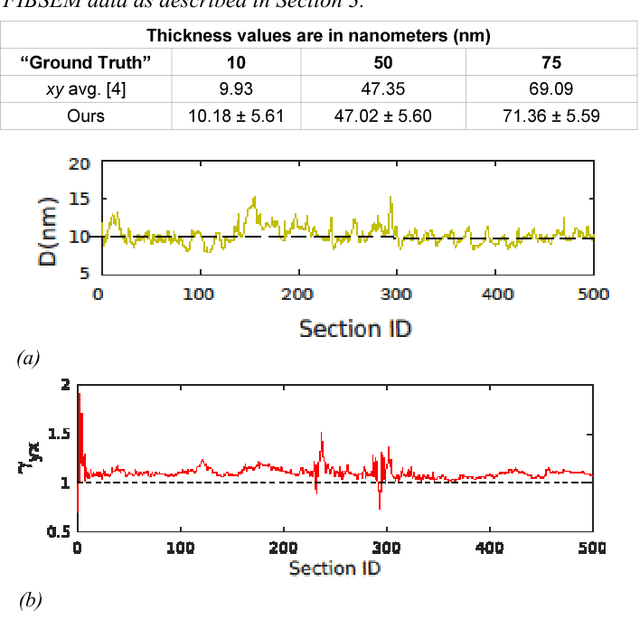
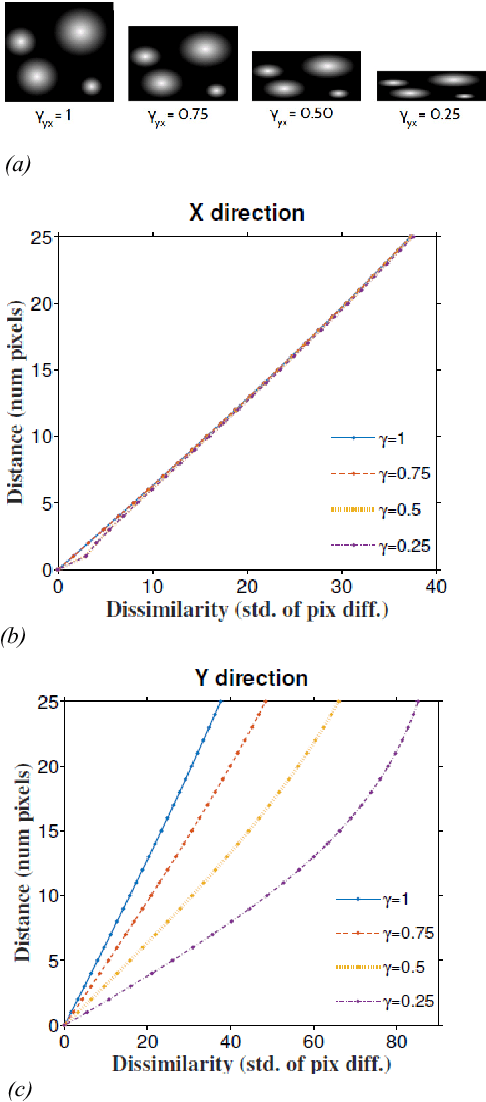
Serial section electron microscopy (ssEM) is a widely used technique for obtaining volumetric information of biological tissues at nanometer scale. However, accurate 3D reconstructions of identified cellular structures and volumetric quantifications require precise estimates of section thickness and anisotropy (or stretching) along the XY imaging plane. In fact, many image processing algorithms simply assume isotropy within the imaging plane. To ameliorate this problem, we present a method for estimating thickness and stretching of electron microscopy sections using non-parametric Bayesian regression of image statistics. We verify our thickness and stretching estimates using direct measurements obtained by atomic force microscopy (AFM) and show that our method has a lower estimation error compared to a recent indirect thickness estimation method as well as a relative Z coordinate estimation method. Furthermore, we have made the first dataset of ssSEM images with directly measured section thickness values publicly available for the evaluation of indirect thickness estimation methods.
Adaptive motor control and learning in a spiking neural network realised on a mixed-signal neuromorphic processor
Oct 25, 2018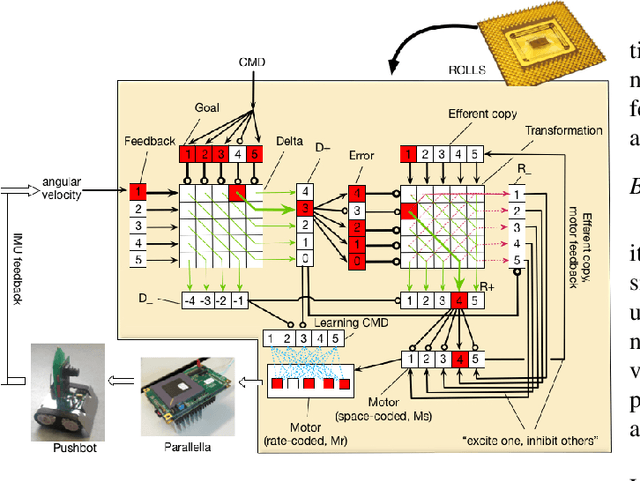

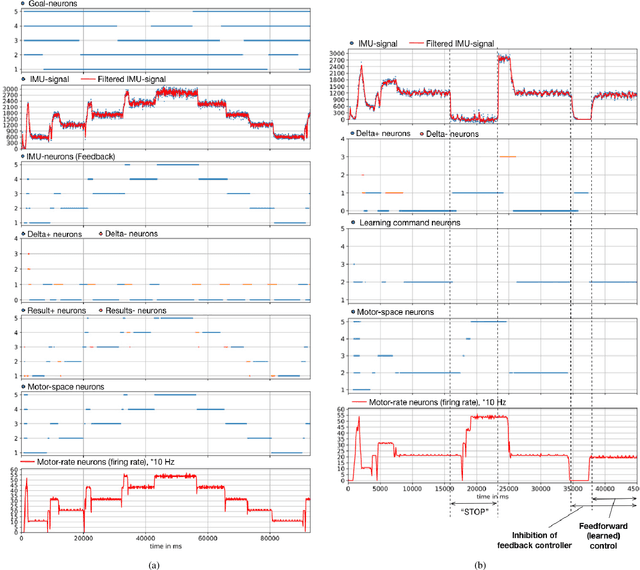
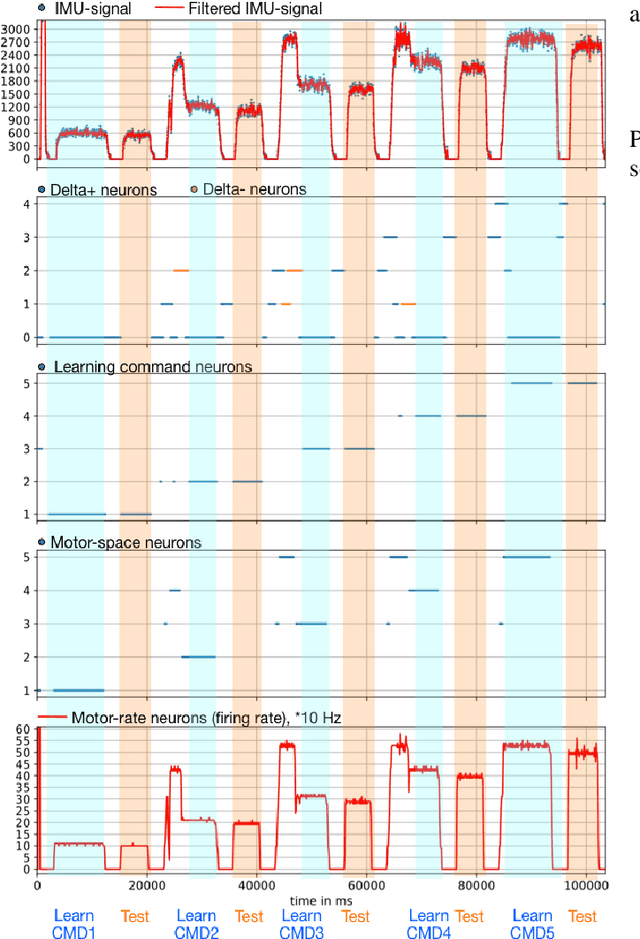
Neuromorphic computing is a new paradigm for design of both the computing hardware and algorithms inspired by biological neural networks. The event-based nature and the inherent parallelism make neuromorphic computing a promising paradigm for building efficient neural network based architectures for control of fast and agile robots. In this paper, we present a spiking neural network architecture that uses sensory feedback to control rotational velocity of a robotic vehicle. When the velocity reaches the target value, the mapping from the target velocity of the vehicle to the correct motor command, both represented in the spiking neural network on the neuromorphic device, is autonomously stored on the device using on-chip plastic synaptic weights. We validate the controller using a wheel motor of a miniature mobile vehicle and inertia measurement unit as the sensory feedback and demonstrate online learning of a simple 'inverse model' in a two-layer spiking neural network on the neuromorphic chip. The prototype neuromorphic device that features 256 spiking neurons allows us to realise a simple proof of concept architecture for the purely neuromorphic motor control and learning. The architecture can be easily scaled-up if a larger neuromorphic device is available.