 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Panoptic Segmentation from Instance Contours
Oct 16, 2020
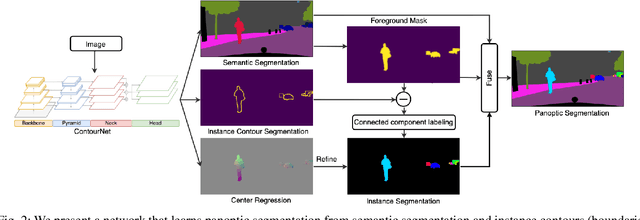
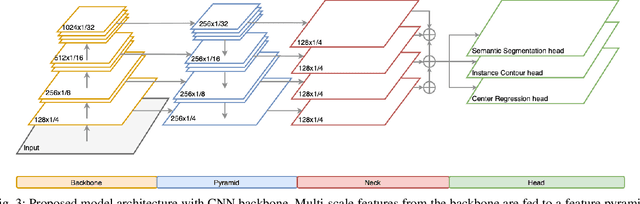
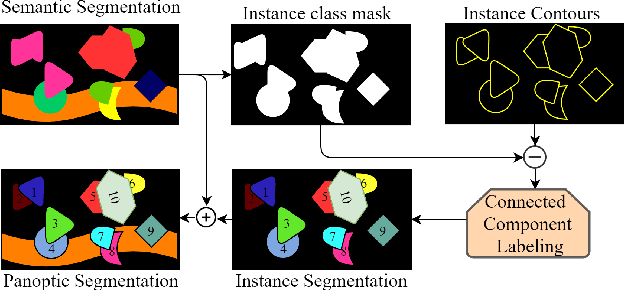
Panoptic Segmentation aims to provide an understanding of background (stuff) and instances of objects (things) at a pixel level. It combines the separate tasks of semantic segmentation (pixel-level classification) and instance segmentation to build a single unified scene understanding task. Typically, panoptic segmentation is derived by combining semantic and instance segmentation tasks that are learned separately or jointly (multi-task networks). In general, instance segmentation networks are built by adding a foreground mask estimation layer on top of object detectors or using instance clustering methods that assign a pixel to an instance center. In this work, we present a fully convolution neural network that learns instance segmentation from semantic segmentation and instance contours (boundaries of things). Instance contours along with semantic segmentation yield a boundary-aware semantic segmentation of things. Connected component labeling on these results produces instance segmentation. We merge semantic and instance segmentation results to output panoptic segmentation. We evaluate our proposed method on the CityScapes dataset to demonstrate qualitative and quantitative performances along with several ablation studies.
MultiNet++: Multi-Stream Feature Aggregation and Geometric Loss Strategy for Multi-Task Learning
Apr 22, 2019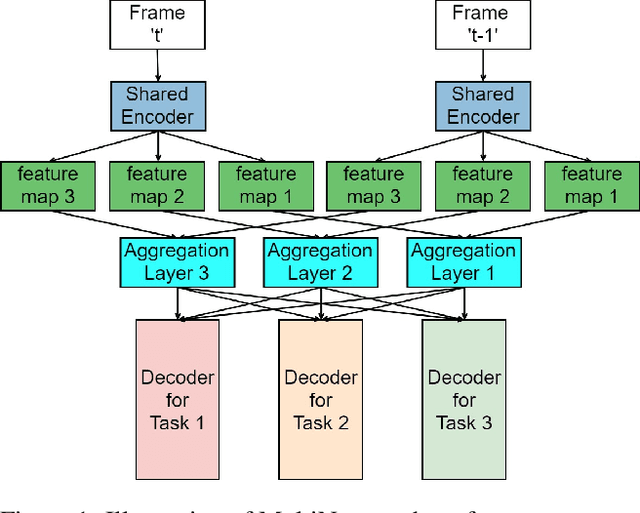

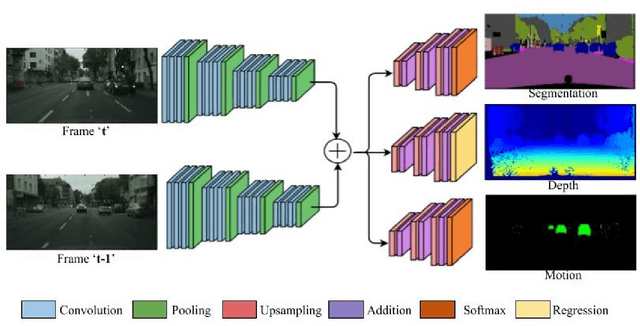
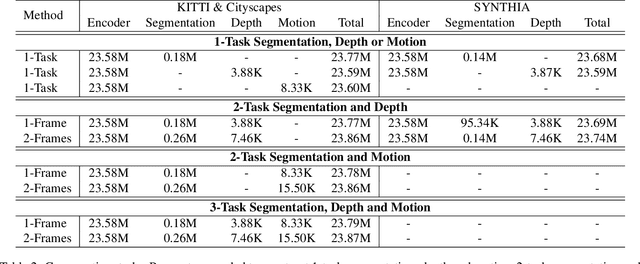
Multi-task learning is commonly used in autonomous driving for solving various visual perception tasks. It offers significant benefits in terms of both performance and computational complexity. Current work on multi-task learning networks focus on processing a single input image and there is no known implementation of multi-task learning handling a sequence of images. In this work, we propose a multi-stream multi-task network to take advantage of using feature representations from preceding frames in a video sequence for joint learning of segmentation, depth, and motion. The weights of the current and previous encoder are shared so that features computed in the previous frame can be leveraged without additional computation. In addition, we propose to use the geometric mean of task losses as a better alternative to the weighted average of task losses. The proposed loss function facilitates better handling of the difference in convergence rates of different tasks. Experimental results on KITTI, Cityscapes and SYNTHIA datasets demonstrate that the proposed strategies outperform various existing multi-task learning solutions.