 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Rendering based Urban Scene Reconstruction for Autonomous Driving
Feb 09, 2024Dense 3D reconstruction has many applications in automated driving including automated annotation validation, multimodal data augmentation, providing ground truth annotations for systems lacking LiDAR, as well as enhancing auto-labeling accuracy. LiDAR provides highly accurate but sparse depth, whereas camera images enable estimation of dense depth but noisy particularly at long ranges. In this paper, we harness the strengths of both sensors and propose a multimodal 3D scene reconstruction using a framework combining neural implicit surfaces and radiance fields. In particular, our method estimates dense and accurate 3D structures and creates an implicit map representation based on signed distance fields, which can be further rendered into RGB images, and depth maps. A mesh can be extracted from the learned signed distance field and culled based on occlusion. Dynamic objects are efficiently filtered on the fly during sampling using 3D object detection models. We demonstrate qualitative and quantitative results on challenging automotive scenes.
Optical Flow for Autonomous Driving: Applications, Challenges and Improvements
Jan 11, 2023
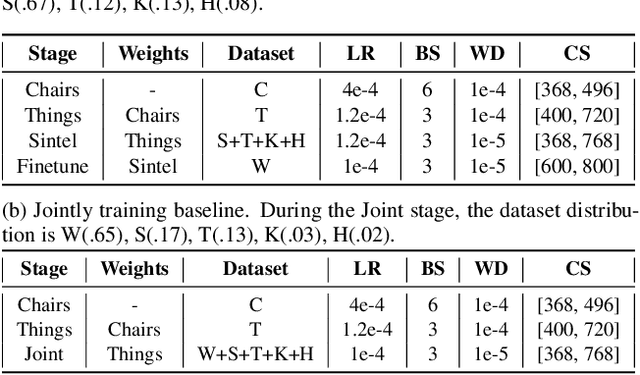

Optical flow estimation is a well-studied topic for automated driving applications. Many outstanding optical flow estimation methods have been proposed, but they become erroneous when tested in challenging scenarios that are commonly encountered. Despite the increasing use of fisheye cameras for near-field sensing in automated driving, there is very limited literature on optical flow estimation with strong lens distortion. Thus we propose and evaluate training strategies to improve a learning-based optical flow algorithm by leveraging the only existing fisheye dataset with optical flow ground truth. While trained with synthetic data, the model demonstrates strong capabilities to generalize to real world fisheye data. The other challenge neglected by existing state-of-the-art algorithms is low light. We propose a novel, generic semi-supervised framework that significantly boosts performances of existing methods in such conditions. To the best of our knowledge, this is the first approach that explicitly handles optical flow estimation in low light.
DytanVO: Joint Refinement of Visual Odometry and Motion Segmentation in Dynamic Environments
Sep 24, 2022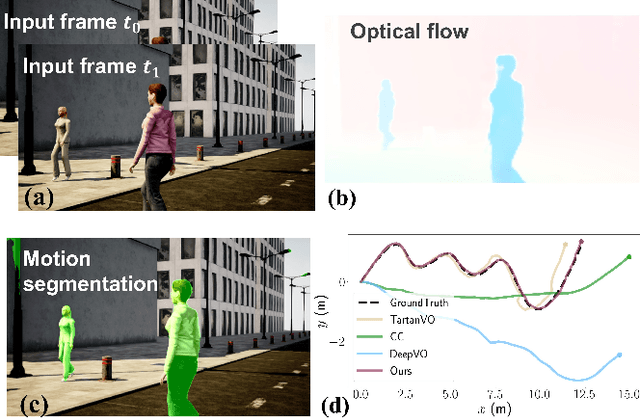
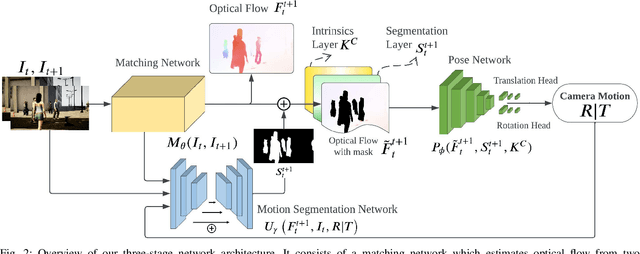
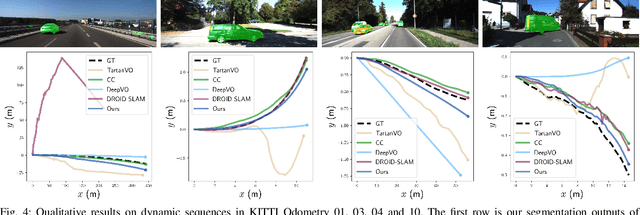
Learning-based visual odometry (VO) algorithms achieve remarkable performance on common static scenes, benefiting from high-capacity models and massive annotated data, but tend to fail in dynamic, populated environments. Semantic segmentation is largely used to discard dynamic associations before estimating camera motions but at the cost of discarding static features and is hard to scale up to unseen categories. In this paper, we leverage the mutual dependence between camera ego-motion and motion segmentation and show that both can be jointly refined in a single learning-based framework. In particular, we present DytanVO, the first supervised learning-based VO method that deals with dynamic environments. It takes two consecutive monocular frames in real-time and predicts camera ego-motion in an iterative fashion. Our method achieves an average improvement of 27.7% in ATE over state-of-the-art VO solutions in real-world dynamic environments, and even performs competitively among dynamic visual SLAM systems which optimize the trajectory on the backend. Experiments on plentiful unseen environments also demonstrate our method's generalizability.
Dynamic Dense RGB-D SLAM using Learning-based Visual Odometry
May 12, 2022
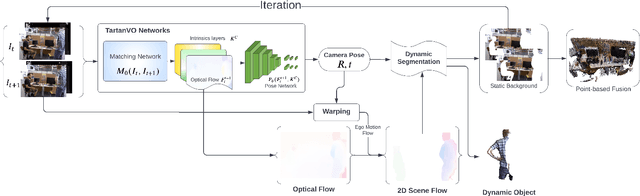
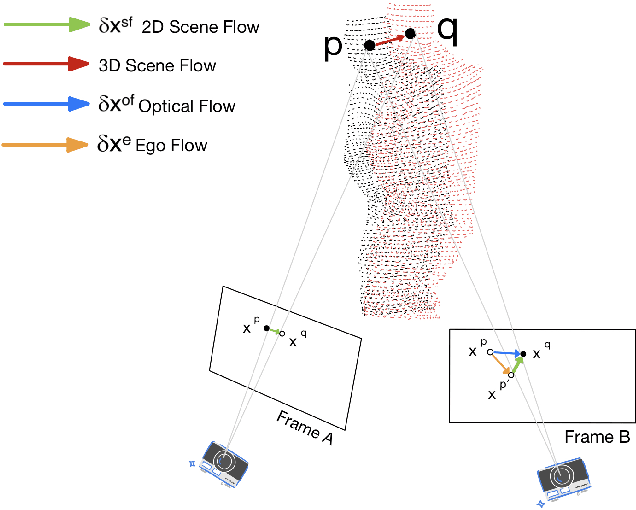

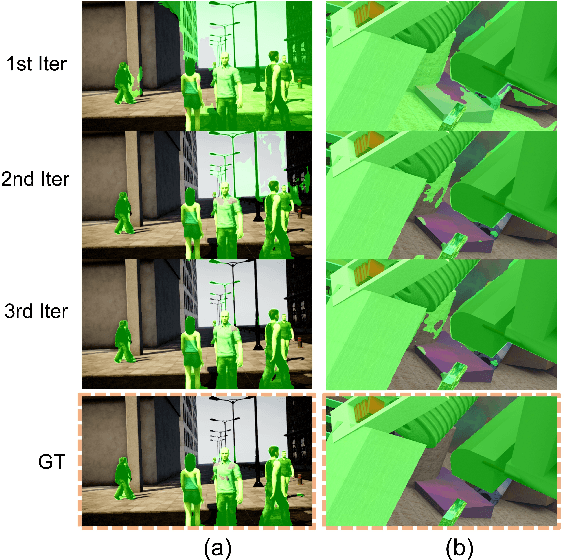
We propose a dense dynamic RGB-D SLAM pipeline based on a learning-based visual odometry, TartanVO. TartanVO, like other direct methods rather than feature-based, estimates camera pose through dense optical flow, which only applies to static scenes and disregards dynamic objects. Due to the color constancy assumption, optical flow is not able to differentiate between dynamic and static pixels. Therefore, to reconstruct a static map through such direct methods, our pipeline resolves dynamic/static segmentation by leveraging the optical flow output, and only fuse static points into the map. Moreover, we rerender the input frames such that the dynamic pixels are removed and iteratively pass them back into the visual odometry to refine the pose estimate.
Tailored Learning-Based Scheduling for Kubernetes-Oriented Edge-Cloud System
Jan 17, 2021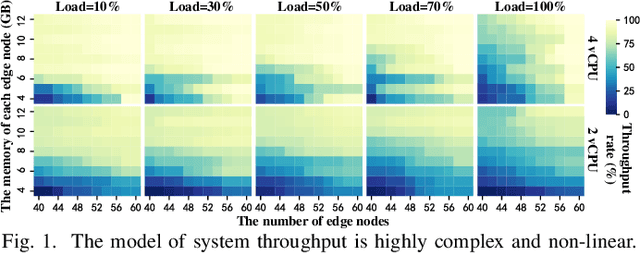
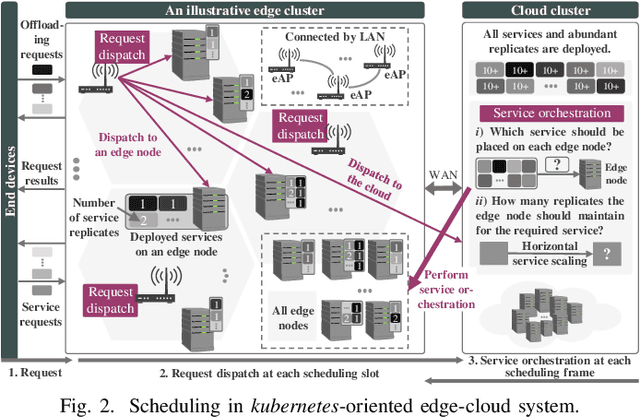
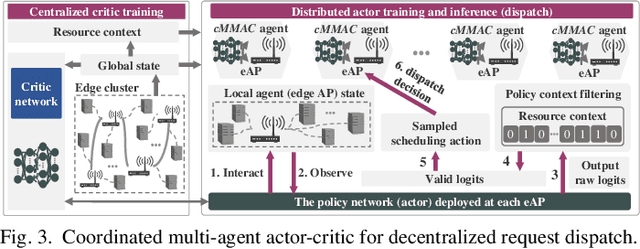
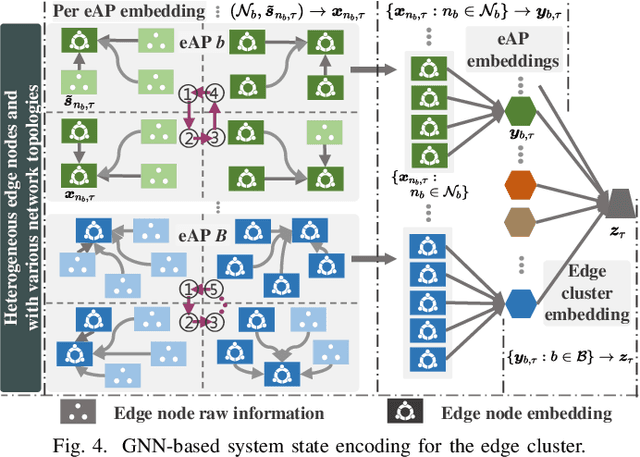
Kubernetes (k8s) has the potential to merge the distributed edge and the cloud but lacks a scheduling framework specifically for edge-cloud systems. Besides, the hierarchical distribution of heterogeneous resources and the complex dependencies among requests and resources make the modeling and scheduling of k8s-oriented edge-cloud systems particularly sophisticated. In this paper, we introduce KaiS, a learning-based scheduling framework for such edge-cloud systems to improve the long-term throughput rate of request processing. First, we design a coordinated multi-agent actor-critic algorithm to cater to decentralized request dispatch and dynamic dispatch spaces within the edge cluster. Second, for diverse system scales and structures, we use graph neural networks to embed system state information, and combine the embedding results with multiple policy networks to reduce the orchestration dimensionality by stepwise scheduling. Finally, we adopt a two-time-scale scheduling mechanism to harmonize request dispatch and service orchestration, and present the implementation design of deploying the above algorithms compatible with native k8s components. Experiments using real workload traces show that KaiS can successfully learn appropriate scheduling policies, irrespective of request arrival patterns and system scales. Moreover, KaiS can enhance the average system throughput rate by 14.3% while reducing scheduling cost by 34.7% compared to baselines.
Autonomous Robotic Suction to Clear the Surgical Field for Hemostasis using Image-based Blood Flow Detection
Oct 16, 2020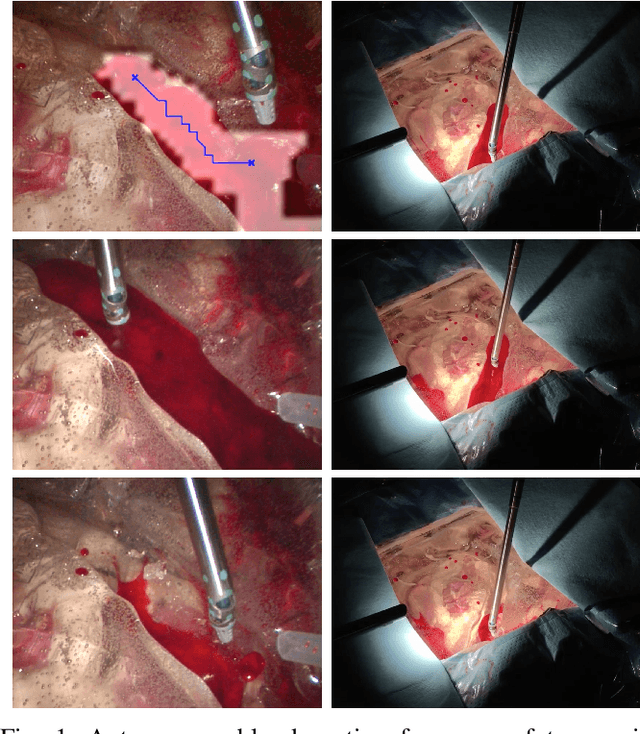
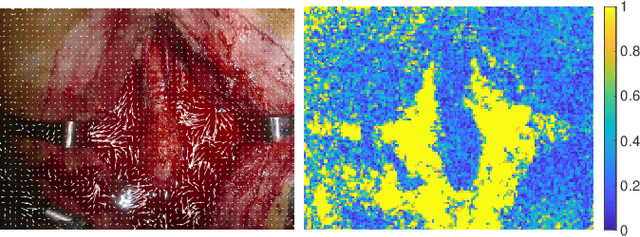
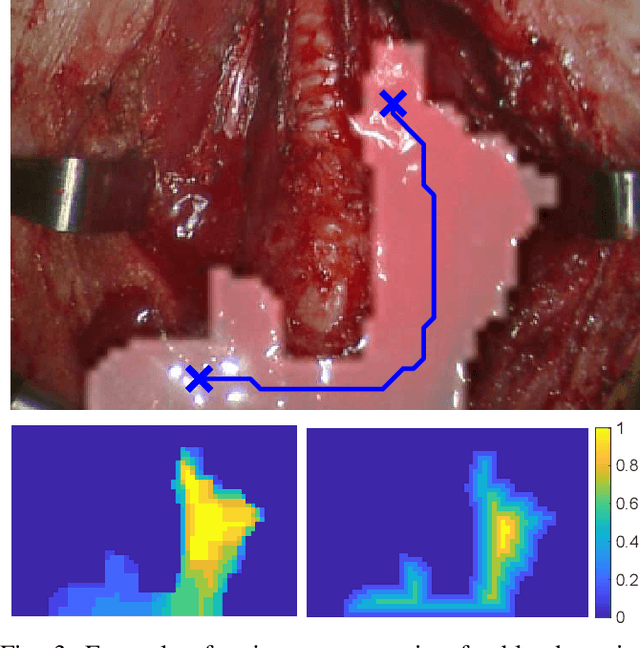

Autonomous robotic surgery has seen significant progression over the last decade with the aims of reducing surgeon fatigue, improving procedural consistency, and perhaps one day take over surgery itself. However, automation has not been applied to the critical surgical task of controlling tissue and blood vessel bleeding--known as hemostasis. The task of hemostasis covers a spectrum of bleeding sources and a range of blood velocity, trajectory, and volume. In an extreme case, an un-controlled blood vessel fills the surgical field with flowing blood. In this work, we present the first, automated solution for hemostasis through development of a novel probabilistic blood flow detection algorithm and a trajectory generation technique that guides autonomous suction tools towards pooling blood. The blood flow detection algorithm is tested in both simulated scenes and in a real-life trauma scenario involving a hemorrhage that occurred during thyroidectomy. The complete solution is tested in a physical lab setting with the da Vinci Research Kit (dVRK) and a simulated surgical cavity for blood to flow through. The results show that our automated solution has accurate detection, a fast reaction time, and effective removal of the flowing blood. Therefore, the proposed methods are powerful tools to clearing the surgical field which can be followed by either a surgeon or future robotic automation developments to close the vessel rupture.