 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDytanVO: Joint Refinement of Visual Odometry and Motion Segmentation in Dynamic Environments
Paper and Code
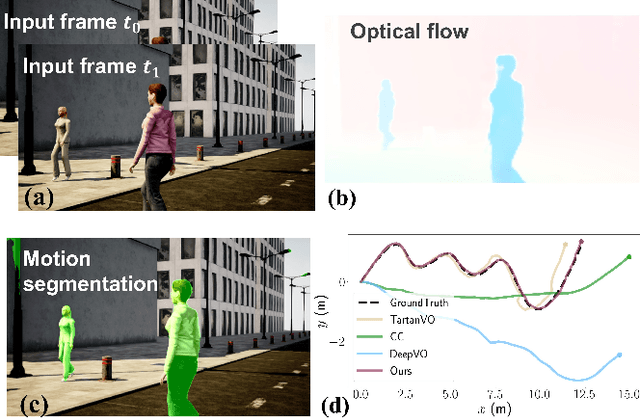
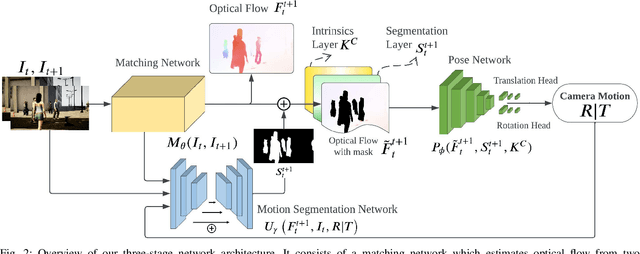
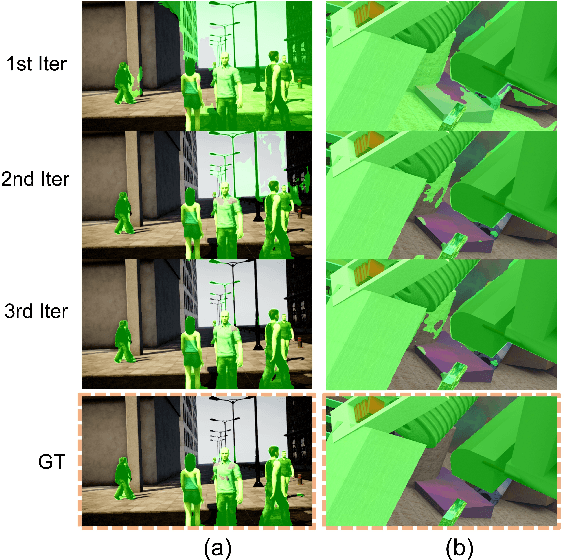
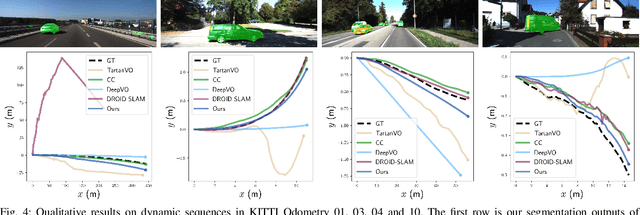
Learning-based visual odometry (VO) algorithms achieve remarkable performance on common static scenes, benefiting from high-capacity models and massive annotated data, but tend to fail in dynamic, populated environments. Semantic segmentation is largely used to discard dynamic associations before estimating camera motions but at the cost of discarding static features and is hard to scale up to unseen categories. In this paper, we leverage the mutual dependence between camera ego-motion and motion segmentation and show that both can be jointly refined in a single learning-based framework. In particular, we present DytanVO, the first supervised learning-based VO method that deals with dynamic environments. It takes two consecutive monocular frames in real-time and predicts camera ego-motion in an iterative fashion. Our method achieves an average improvement of 27.7% in ATE over state-of-the-art VO solutions in real-world dynamic environments, and even performs competitively among dynamic visual SLAM systems which optimize the trajectory on the backend. Experiments on plentiful unseen environments also demonstrate our method's generalizability.