 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURGENT Challenge: Universality, Robustness, and Generalizability For Speech Enhancement
Jun 07, 2024



The last decade has witnessed significant advancements in deep learning-based speech enhancement (SE). However, most existing SE research has limitations on the coverage of SE sub-tasks, data diversity and amount, and evaluation metrics. To fill this gap and promote research toward universal SE, we establish a new SE challenge, named URGENT, to focus on the universality, robustness, and generalizability of SE. We aim to extend the SE definition to cover different sub-tasks to explore the limits of SE models, starting from denoising, dereverberation, bandwidth extension, and declipping. A novel framework is proposed to unify all these sub-tasks in a single model, allowing the use of all existing SE approaches. We collected public speech and noise data from different domains to construct diverse evaluation data. Finally, we discuss the insights gained from our preliminary baseline experiments based on both generative and discriminative SE methods with 12 curated metrics.
Employing Real Training Data for Deep Noise Suppression
Sep 05, 2023Most deep noise suppression (DNS) models are trained with reference-based losses requiring access to clean speech. However, sometimes an additive microphone model is insufficient for real-world applications. Accordingly, ways to use real training data in supervised learning for DNS models promise to reduce a potential training/inference mismatch. Employing real data for DNS training requires either generative approaches or a reference-free loss without access to the corresponding clean speech. In this work, we propose to employ an end-to-end non-intrusive deep neural network (DNN), named PESQ-DNN, to estimate perceptual evaluation of speech quality (PESQ) scores of enhanced real data. It provides a reference-free perceptual loss for employing real data during DNS training, maximizing the PESQ scores. Furthermore, we use an epoch-wise alternating training protocol, updating the DNS model on real data, followed by PESQ-DNN updating on synthetic data. The DNS model trained with the PESQ-DNN employing real data outperforms all reference methods employing only synthetic training data. On synthetic test data, our proposed method excels the Interspeech 2021 DNS Challenge baseline by a significant 0.32 PESQ points. Both on synthetic and real test data, the proposed method beats the baseline by 0.05 DNSMOS points - although PESQ-DNN optimizes for a different perceptual metric.
A Library Perspective on Nearly-Unsupervised Information Extraction Workflows in Digital Libraries
May 02, 2022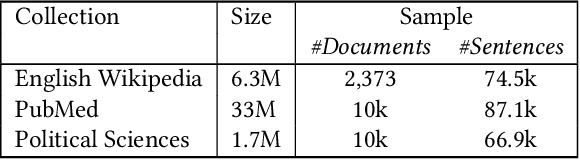



Information extraction can support novel and effective access paths for digital libraries. Nevertheless, designing reliable extraction workflows can be cost-intensive in practice. On the one hand, suitable extraction methods rely on domain-specific training data. On the other hand, unsupervised and open extraction methods usually produce not-canonicalized extraction results. This paper tackles the question how digital libraries can handle such extractions and if their quality is sufficient in practice. We focus on unsupervised extraction workflows by analyzing them in case studies in the domains of encyclopedias (Wikipedia), pharmacy and political sciences. We report on opportunities and limitations. Finally we discuss best practices for unsupervised extraction workflows.