 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Robust AV-ASR Using Visual Features Both in the Whisper Encoder and Decoder
Jan 26, 2026In audiovisual automatic speech recognition (AV-ASR) systems, information fusion of visual features in a pre-trained ASR has been proven as a promising method to improve noise robustness. In this work, based on the prominent Whisper ASR, first, we propose a simple and effective visual fusion method -- use of visual features both in encoder and decoder (dual-use) -- to learn the audiovisual interactions in the encoder and to weigh modalities in the decoder. Second, we compare visual fusion methods in Whisper models of various sizes. Our proposed dual-use method shows consistent noise robustness improvement, e.g., a 35% relative improvement (WER: 4.41% vs. 6.83%) based on Whisper small, and a 57% relative improvement (WER: 4.07% vs. 9.53%) based on Whisper medium, compared to typical reference middle fusion in babble noise with a signal-to-noise ratio (SNR) of 0dB. Third, we conduct ablation studies examining the impact of various module designs and fusion options. Fine-tuned on 1929 hours of audiovisual data, our dual-use method using Whisper medium achieves 4.08% (MUSAN babble noise) and 4.43% (NoiseX babble noise) average WER across various SNRs, thereby establishing a new state-of-the-art in noisy conditions on the LRS3 AV-ASR benchmark. Our code is at https://github.com/ifnspaml/Dual-Use-AVASR
Engineering of Hallucination in Generative AI: It's not a Bug, it's a Feature
Jan 11, 2026Generative artificial intelligence (AI) is conquering our lives at lightning speed. Large language models such as ChatGPT answer our questions or write texts for us, large computer vision models such as GAIA-1 generate videos on the basis of text descriptions or continue prompted videos. These neural network models are trained using large amounts of text or video data, strictly according to the real data employed in training. However, there is a surprising observation: When we use these models, they only function satisfactorily when they are allowed a certain degree of fantasy (hallucination). While hallucination usually has a negative connotation in generative AI - after all, ChatGPT is expected to give a fact-based answer! - this article recapitulates some simple means of probability engineering that can be used to encourage generative AI to hallucinate to a limited extent and thus lead to the desired results. We have to ask ourselves: Is hallucination in gen-erative AI probably not a bug, but rather a feature?
OpenViGA: Video Generation for Automotive Driving Scenes by Streamlining and Fine-Tuning Open Source Models with Public Data
Sep 18, 2025

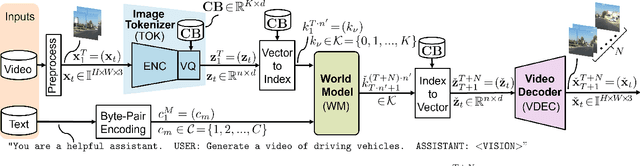

Recent successful video generation systems that predict and create realistic automotive driving scenes from short video inputs assign tokenization, future state prediction (world model), and video decoding to dedicated models. These approaches often utilize large models that require significant training resources, offer limited insight into design choices, and lack publicly available code and datasets. In this work, we address these deficiencies and present OpenViGA, an open video generation system for automotive driving scenes. Our contributions are: Unlike several earlier works for video generation, such as GAIA-1, we provide a deep analysis of the three components of our system by separate quantitative and qualitative evaluation: Image tokenizer, world model, video decoder. Second, we purely build upon powerful pre-trained open source models from various domains, which we fine-tune by publicly available automotive data (BDD100K) on GPU hardware at academic scale. Third, we build a coherent video generation system by streamlining interfaces of our components. Fourth, due to public availability of the underlying models and data, we allow full reproducibility. Finally, we also publish our code and models on Github. For an image size of 256x256 at 4 fps we are able to predict realistic driving scene videos frame-by-frame with only one frame of algorithmic latency.
A Lightweight Image Super-Resolution Transformer Trained on Low-Resolution Images Only
Mar 30, 2025Transformer architectures prominently lead single-image super-resolution (SISR) benchmarks, reconstructing high-resolution (HR) images from their low-resolution (LR) counterparts. Their strong representative power, however, comes with a higher demand for training data compared to convolutional neural networks (CNNs). For many real-world SR applications, the availability of high-quality HR training images is not given, sparking interest in LR-only training methods. The LR-only SISR benchmark mimics this condition by allowing only low-resolution (LR) images for model training. For a 4x super-resolution, this effectively reduces the amount of available training data to 6.25% of the HR image pixels, which puts the employment of a data-hungry transformer model into question. In this work, we are the first to utilize a lightweight vision transformer model with LR-only training methods addressing the unsupervised SISR LR-only benchmark. We adopt and configure a recent LR-only training method from microscopy image super-resolution to macroscopic real-world data, resulting in our multi-scale training method for bicubic degradation (MSTbic). Furthermore, we compare it with reference methods and prove its effectiveness both for a transformer and a CNN model. We evaluate on the classic SR benchmark datasets Set5, Set14, BSD100, Urban100, and Manga109, and show superior performance over state-of-the-art (so far: CNN-based) LR-only SISR methods. The code is available on GitHub: https://github.com/ifnspaml/SuperResolutionMultiscaleTraining.
Relaxed Attention for Transformer Models
Sep 20, 2022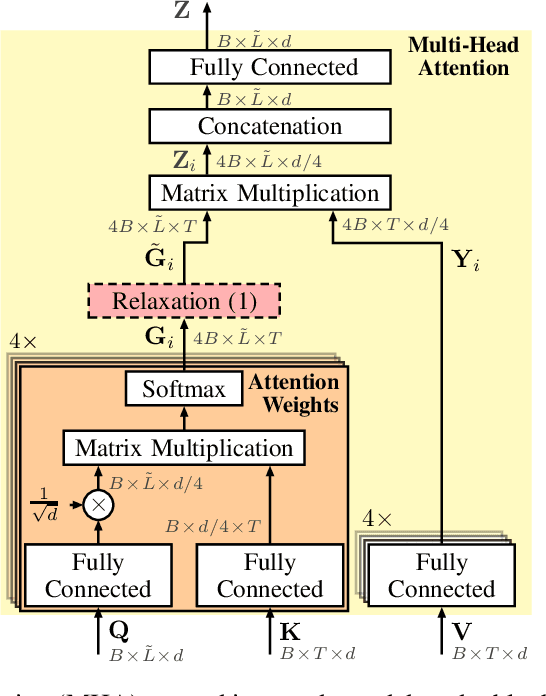
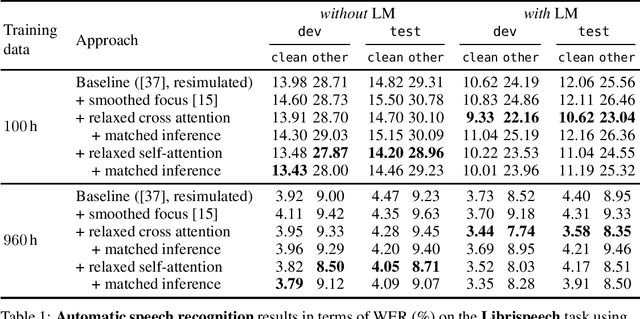


The powerful modeling capabilities of all-attention-based transformer architectures often cause overfitting and - for natural language processing tasks - lead to an implicitly learned internal language model in the autoregressive transformer decoder complicating the integration of external language models. In this paper, we explore relaxed attention, a simple and easy-to-implement smoothing of the attention weights, yielding a two-fold improvement to the general transformer architecture: First, relaxed attention provides regularization when applied to the self-attention layers in the encoder. Second, we show that it naturally supports the integration of an external language model as it suppresses the implicitly learned internal language model by relaxing the cross attention in the decoder. We demonstrate the benefit of relaxed attention across several tasks with clear improvement in combination with recent benchmark approaches. Specifically, we exceed the former state-of-the-art performance of 26.90% word error rate on the largest public lip-reading LRS3 benchmark with a word error rate of 26.31%, as well as we achieve a top-performing BLEU score of 37.67 on the IWSLT14 (DE$\rightarrow$EN) machine translation task without external language models and virtually no additional model parameters. Code and models will be made publicly available.