 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngineering of Hallucination in Generative AI: It's not a Bug, it's a Feature
Jan 11, 2026Generative artificial intelligence (AI) is conquering our lives at lightning speed. Large language models such as ChatGPT answer our questions or write texts for us, large computer vision models such as GAIA-1 generate videos on the basis of text descriptions or continue prompted videos. These neural network models are trained using large amounts of text or video data, strictly according to the real data employed in training. However, there is a surprising observation: When we use these models, they only function satisfactorily when they are allowed a certain degree of fantasy (hallucination). While hallucination usually has a negative connotation in generative AI - after all, ChatGPT is expected to give a fact-based answer! - this article recapitulates some simple means of probability engineering that can be used to encourage generative AI to hallucinate to a limited extent and thus lead to the desired results. We have to ask ourselves: Is hallucination in gen-erative AI probably not a bug, but rather a feature?
Improving Block-Wise LLM Quantization by 4-bit Block-Wise Optimal Float (BOF4): Analysis and Variations
May 10, 2025



Large language models (LLMs) demand extensive memory capacity during both fine-tuning and inference. To enable memory-efficient fine-tuning, existing methods apply block-wise quantization techniques, such as NF4 and AF4, to the network weights. We show that these quantization techniques incur suboptimal quantization errors. Therefore, as a first novelty, we propose an optimization approach for block-wise quantization. Using this method, we design a family of quantizers named 4-bit block-wise optimal float (BOF4), which consistently reduces the quantization error compared to both baseline methods. We provide both a theoretical and a data-driven solution for the optimization process and prove their practical equivalence. Secondly, we propose a modification to the employed normalization method based on the signed absolute block maximum (BOF4-S), enabling further reduction of the quantization error and empirically achieving less degradation in language modeling performance. Thirdly, we explore additional variations of block-wise quantization methods applied to LLMs through an experimental study on the importance of accurately representing zero and large-amplitude weights on the one hand, and optimization towards various error metrics on the other hand. Lastly, we introduce a mixed-precision quantization strategy dubbed outlier-preserving quantization (OPQ) to address the distributional mismatch induced by outlier weights in block-wise quantization. By storing outlier weights in 16-bit precision (OPQ) while applying BOF4-S, we achieve top performance among 4-bit block-wise quantization techniques w.r.t. perplexity.
Computing Motion Plans for Assembling Particles with Global Control
Jul 06, 2023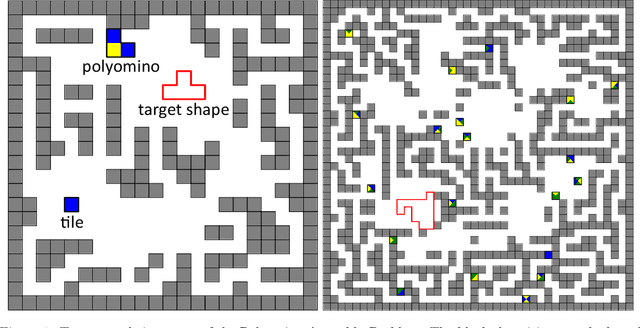
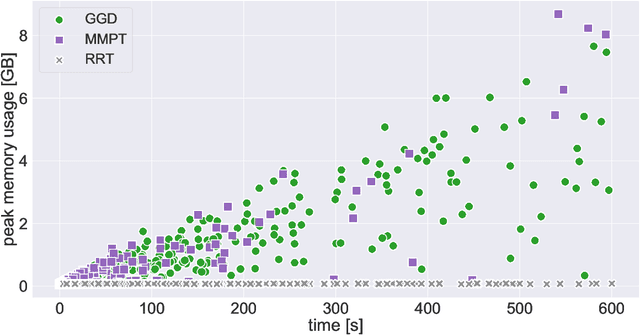
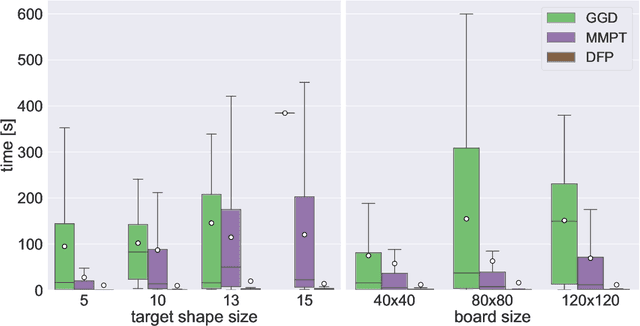
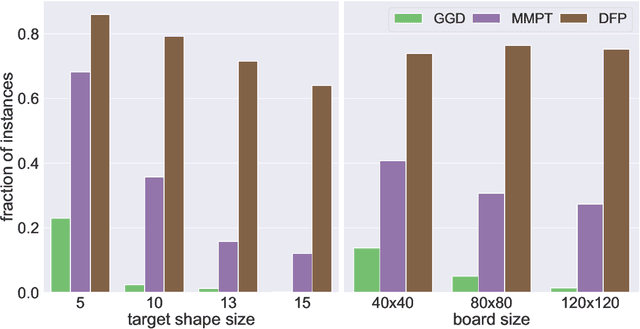
We investigate motion planning algorithms for the assembly of shapes in the \emph{tilt model} in which unit-square tiles move in a grid world under the influence of uniform external forces and self-assemble according to certain rules. We provide several heuristics and experimental evaluation of their success rate, solution length, runtime, and memory consumption.