 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient High-Performance Bark-Scale Neural Network for Residual Echo and Noise Suppression
Apr 08, 2024In recent years, the introduction of neural networks (NNs) into the field of speech enhancement has brought significant improvements. However, many of the proposed methods are quite demanding in terms of computational complexity and memory footprint. For the application in dedicated communication devices, such as speakerphones, hands-free car systems, or smartphones, efficiency plays a major role along with performance. In this context, we present an efficient, high-performance hybrid joint acoustic echo control and noise suppression system, whereby our main contribution is the postfilter NN, performing both noise and residual echo suppression. The preservation of nearend speech is improved by a Bark-scale auditory filterbank for the NN postfilter. The proposed hybrid method is benchmarked with state-of-the-art methods and its effectiveness is demonstrated on the ICASSP 2023 AEC Challenge blind test set. We demonstrate that it offers high-quality nearend speech preservation during both double-talk and nearend speech conditions. At the same time, it is capable of efficient removal of echo leaks, achieving a comparable performance to already small state-of-the-art models such as the end-to-end DeepVQE-S, while requiring only around 10 % of its computational complexity. This makes it easily realtime implementable on a speakerphone device.
Efficient Acoustic Echo Suppression with Condition-Aware Training
Jul 28, 2023The topic of deep acoustic echo control (DAEC) has seen many approaches with various model topologies in recent years. Convolutional recurrent networks (CRNs), consisting of a convolutional encoder and decoder encompassing a recurrent bottleneck, are repeatedly employed due to their ability to preserve nearend speech even in double-talk (DT) condition. However, past architectures are either computationally complex or trade off smaller model sizes with a decrease in performance. We propose an improved CRN topology which, compared to other realizations of this class of architectures, not only saves parameters and computational complexity, but also shows improved performance in DT, outperforming both baseline architectures FCRN and CRUSE. Striving for a condition-aware training, we also demonstrate the importance of a high proportion of double-talk and the missing value of nearend-only speech in DAEC training data. Finally, we show how to control the trade-off between aggressive echo suppression and near-end speech preservation by fine-tuning with condition-aware component loss functions.
Bandwidth-Scalable Fully Mask-Based Deep FCRN Acoustic Echo Cancellation and Postfiltering
May 09, 2022
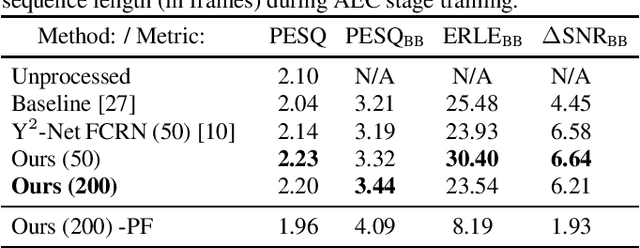

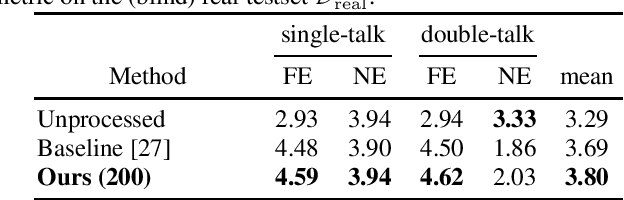
Although today's speech communication systems support various bandwidths from narrowband to super-wideband and beyond, state-of-the art DNN methods for acoustic echo cancellation (AEC) are lacking modularity and bandwidth scalability. Our proposed DNN model builds upon a fully convolutional recurrent network (FCRN) and introduces scalability over various bandwidths up to a fullband (FB) system (48 kHz sampling rate). This modular approach allows joint wideband (WB) pre-training of mask-based AEC and postfilter stages with dedicated losses, followed by a separate training of them on FB data. A third lightweight blind bandwidth extension stage is separately trained on FB data, flexibly allowing to extend the WB postfilter output towards higher bandwidths until reaching FB. Thereby, higher frequency noise and echo are reliably suppressed. On the ICASSP 2022 Acoustic Echo Cancellation Challenge blind test set we report a competitive performance, showing robustness even under highly delayed echo and dynamic echo path changes.