 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuideline for Trustworthy Artificial Intelligence -- AI Assessment Catalog
Jun 20, 2023Artificial Intelligence (AI) has made impressive progress in recent years and represents a key technology that has a crucial impact on the economy and society. However, it is clear that AI and business models based on it can only reach their full potential if AI applications are developed according to high quality standards and are effectively protected against new AI risks. For instance, AI bears the risk of unfair treatment of individuals when processing personal data e.g., to support credit lending or staff recruitment decisions. The emergence of these new risks is closely linked to the fact that the behavior of AI applications, particularly those based on Machine Learning (ML), is essentially learned from large volumes of data and is not predetermined by fixed programmed rules. Thus, the issue of the trustworthiness of AI applications is crucial and is the subject of numerous major publications by stakeholders in politics, business and society. In addition, there is mutual agreement that the requirements for trustworthy AI, which are often described in an abstract way, must now be made clear and tangible. One challenge to overcome here relates to the fact that the specific quality criteria for an AI application depend heavily on the application context and possible measures to fulfill them in turn depend heavily on the AI technology used. Lastly, practical assessment procedures are needed to evaluate whether specific AI applications have been developed according to adequate quality standards. This AI assessment catalog addresses exactly this point and is intended for two target groups: Firstly, it provides developers with a guideline for systematically making their AI applications trustworthy. Secondly, it guides assessors and auditors on how to examine AI applications for trustworthiness in a structured way.
Validation of Simulation-Based Testing: Bypassing Domain Shift with Label-to-Image Synthesis
Jun 10, 2021
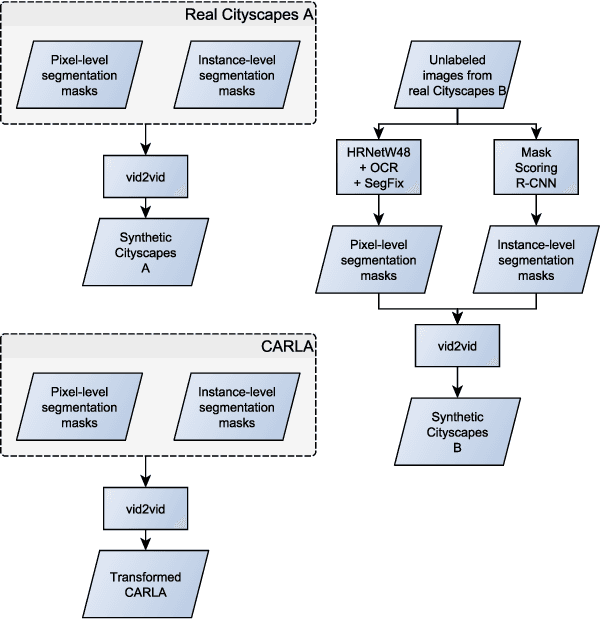


Many machine learning applications can benefit from simulated data for systematic validation - in particular if real-life data is difficult to obtain or annotate. However, since simulations are prone to domain shift w.r.t. real-life data, it is crucial to verify the transferability of the obtained results. We propose a novel framework consisting of a generative label-to-image synthesis model together with different transferability measures to inspect to what extent we can transfer testing results of semantic segmentation models from synthetic data to equivalent real-life data. With slight modifications, our approach is extendable to, e.g., general multi-class classification tasks. Grounded on the transferability analysis, our approach additionally allows for extensive testing by incorporating controlled simulations. We validate our approach empirically on a semantic segmentation task on driving scenes. Transferability is tested using correlation analysis of IoU and a learned discriminator. Although the latter can distinguish between real-life and synthetic tests, in the former we observe surprisingly strong correlations of 0.7 for both cars and pedestrians.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.
Patch Shortcuts: Interpretable Proxy Models Efficiently Find Black-Box Vulnerabilities
Apr 22, 2021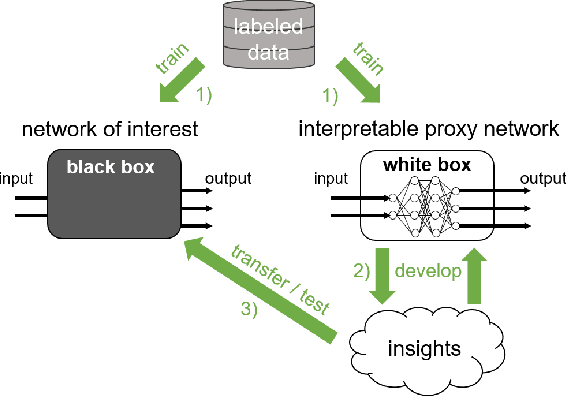
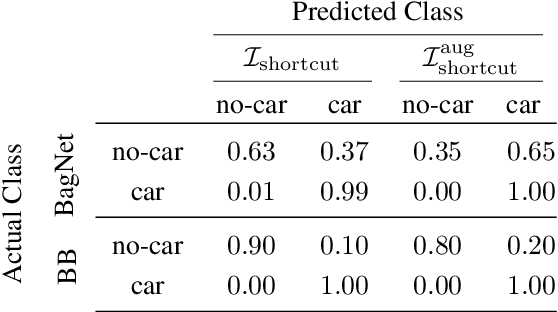

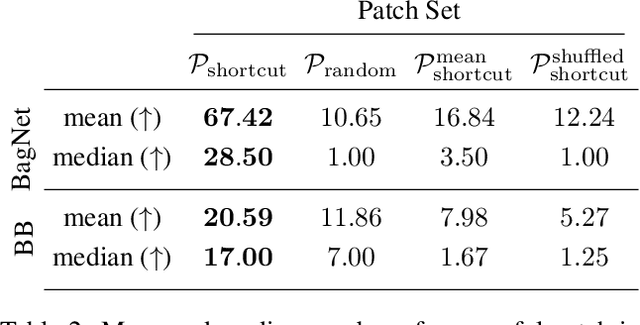
An important pillar for safe machine learning (ML) is the systematic mitigation of weaknesses in neural networks to afford their deployment in critical applications. An ubiquitous class of safety risks are learned shortcuts, i.e. spurious correlations a network exploits for its decisions that have no semantic connection to the actual task. Networks relying on such shortcuts bear the risk of not generalizing well to unseen inputs. Explainability methods help to uncover such network vulnerabilities. However, many of these techniques are not directly applicable if access to the network is constrained, in so-called black-box setups. These setups are prevalent when using third-party ML components. To address this constraint, we present an approach to detect learned shortcuts using an interpretable-by-design network as a proxy to the black-box model of interest. Leveraging the proxy's guarantees on introspection we automatically extract candidates for learned shortcuts. Their transferability to the black box is validated in a systematic fashion. Concretely, as proxy model we choose a BagNet, which bases its decisions purely on local image patches. We demonstrate on the autonomous driving dataset A2D2 that extracted patch shortcuts significantly influence the black box model. By efficiently identifying such patch-based vulnerabilities, we contribute to safer ML models.
Information-Theoretic Perspective of Federated Learning
Nov 15, 2019



An approach to distributed machine learning is to train models on local datasets and aggregate these models into a single, stronger model. A popular instance of this form of parallelization is federated learning, where the nodes periodically send their local models to a coordinator that aggregates them and redistributes the aggregation back to continue training with it. The most frequently used form of aggregation is averaging the model parameters, e.g., the weights of a neural network. However, due to the non-convexity of the loss surface of neural networks, averaging can lead to detrimental effects and it remains an open question under which conditions averaging is beneficial. In this paper, we study this problem from the perspective of information theory: We measure the mutual information between representation and inputs as well as representation and labels in local models and compare it to the respective information contained in the representation of the averaged model. Our empirical results confirm previous observations about the practical usefulness of averaging for neural networks, even if local dataset distributions vary strongly. Furthermore, we obtain more insights about the impact of the aggregation frequency on the information flow and thus on the success of distributed learning. These insights will be helpful both in improving the current synchronization process and in further understanding the effects of model aggregation.