 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL4AD: Vision-Language Models Improve Pixel-wise Anomaly Detection
Sep 25, 2024Semantic segmentation networks have achieved significant success under the assumption of independent and identically distributed data. However, these networks often struggle to detect anomalies from unknown semantic classes due to the limited set of visual concepts they are typically trained on. To address this issue, anomaly segmentation often involves fine-tuning on outlier samples, necessitating additional efforts for data collection, labeling, and model retraining. Seeking to avoid this cumbersome work, we take a different approach and propose to incorporate Vision-Language (VL) encoders into existing anomaly detectors to leverage the semantically broad VL pre-training for improved outlier awareness. Additionally, we propose a new scoring function that enables data- and training-free outlier supervision via textual prompts. The resulting VL4AD model, which includes max-logit prompt ensembling and a class-merging strategy, achieves competitive performance on widely used benchmark datasets, thereby demonstrating the potential of vision-language models for pixel-wise anomaly detection.
Guideline for Trustworthy Artificial Intelligence -- AI Assessment Catalog
Jun 20, 2023Artificial Intelligence (AI) has made impressive progress in recent years and represents a key technology that has a crucial impact on the economy and society. However, it is clear that AI and business models based on it can only reach their full potential if AI applications are developed according to high quality standards and are effectively protected against new AI risks. For instance, AI bears the risk of unfair treatment of individuals when processing personal data e.g., to support credit lending or staff recruitment decisions. The emergence of these new risks is closely linked to the fact that the behavior of AI applications, particularly those based on Machine Learning (ML), is essentially learned from large volumes of data and is not predetermined by fixed programmed rules. Thus, the issue of the trustworthiness of AI applications is crucial and is the subject of numerous major publications by stakeholders in politics, business and society. In addition, there is mutual agreement that the requirements for trustworthy AI, which are often described in an abstract way, must now be made clear and tangible. One challenge to overcome here relates to the fact that the specific quality criteria for an AI application depend heavily on the application context and possible measures to fulfill them in turn depend heavily on the AI technology used. Lastly, practical assessment procedures are needed to evaluate whether specific AI applications have been developed according to adequate quality standards. This AI assessment catalog addresses exactly this point and is intended for two target groups: Firstly, it provides developers with a guideline for systematically making their AI applications trustworthy. Secondly, it guides assessors and auditors on how to examine AI applications for trustworthiness in a structured way.
A Survey on Uncertainty Toolkits for Deep Learning
May 02, 2022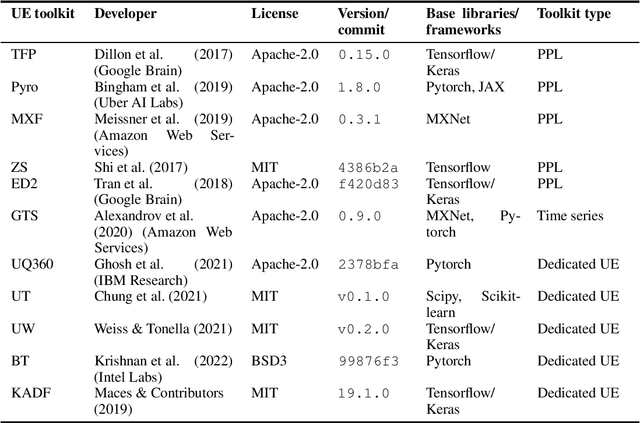
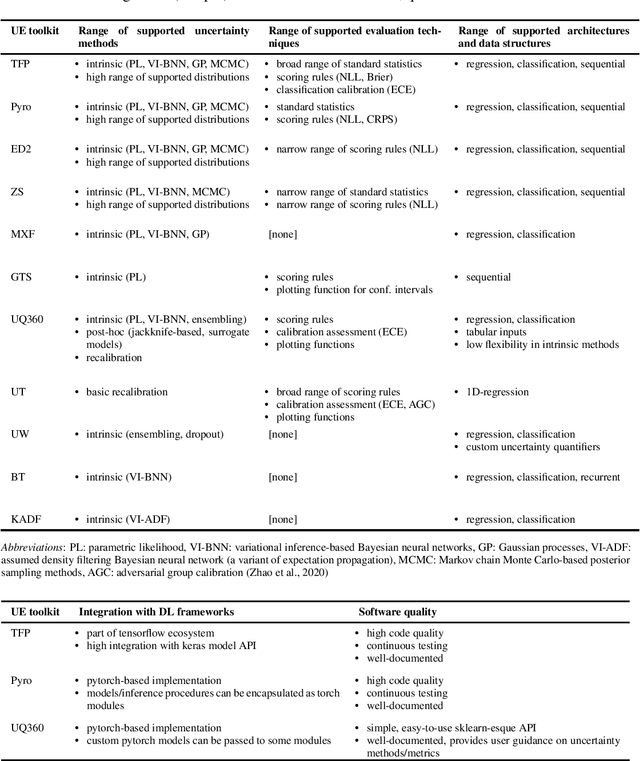
The success of deep learning (DL) fostered the creation of unifying frameworks such as tensorflow or pytorch as much as it was driven by their creation in return. Having common building blocks facilitates the exchange of, e.g., models or concepts and makes developments easier replicable. Nonetheless, robust and reliable evaluation and assessment of DL models has often proven challenging. This is at odds with their increasing safety relevance, which recently culminated in the field of "trustworthy ML". We believe that, among others, further unification of evaluation and safeguarding methodologies in terms of toolkits, i.e., small and specialized framework derivatives, might positively impact problems of trustworthiness as well as reproducibility. To this end, we present the first survey on toolkits for uncertainty estimation (UE) in DL, as UE forms a cornerstone in assessing model reliability. We investigate 11 toolkits with respect to modeling and evaluation capabilities, providing an in-depth comparison for the three most promising ones, namely Pyro, Tensorflow Probability, and Uncertainty Quantification 360. While the first two provide a large degree of flexibility and seamless integration into their respective framework, the last one has the larger methodological scope.
Tailored Uncertainty Estimation for Deep Learning Systems
Apr 29, 2022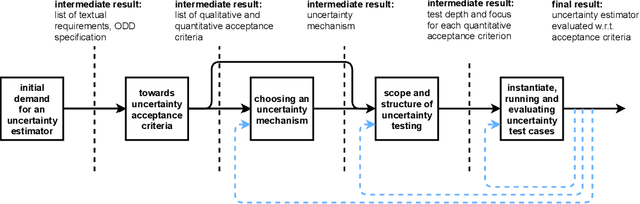

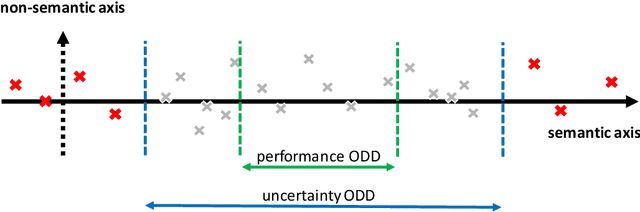
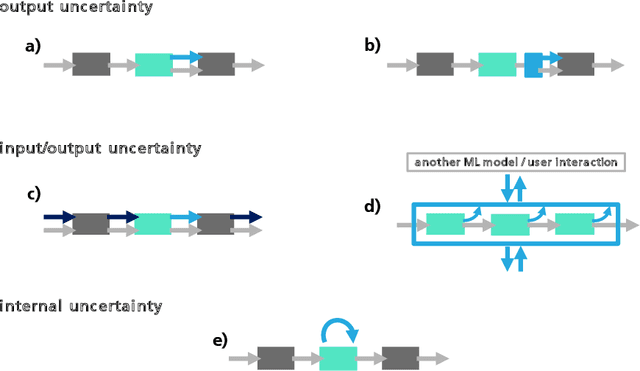
Uncertainty estimation bears the potential to make deep learning (DL) systems more reliable. Standard techniques for uncertainty estimation, however, come along with specific combinations of strengths and weaknesses, e.g., with respect to estimation quality, generalization abilities and computational complexity. To actually harness the potential of uncertainty quantification, estimators are required whose properties closely match the requirements of a given use case. In this work, we propose a framework that, firstly, structures and shapes these requirements, secondly, guides the selection of a suitable uncertainty estimation method and, thirdly, provides strategies to validate this choice and to uncover structural weaknesses. By contributing tailored uncertainty estimation in this sense, our framework helps to foster trustworthy DL systems. Moreover, it anticipates prospective machine learning regulations that require, e.g., in the EU, evidences for the technical appropriateness of machine learning systems. Our framework provides such evidences for system components modeling uncertainty.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.
Patch Shortcuts: Interpretable Proxy Models Efficiently Find Black-Box Vulnerabilities
Apr 22, 2021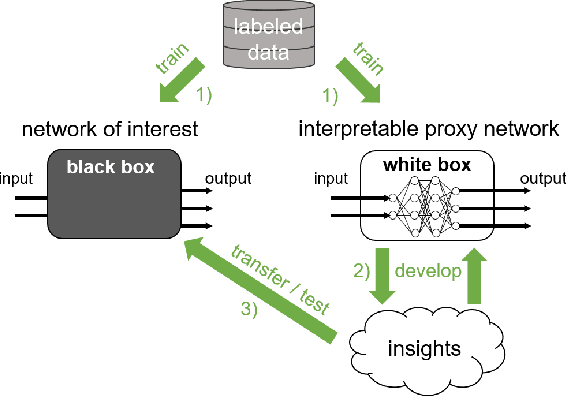
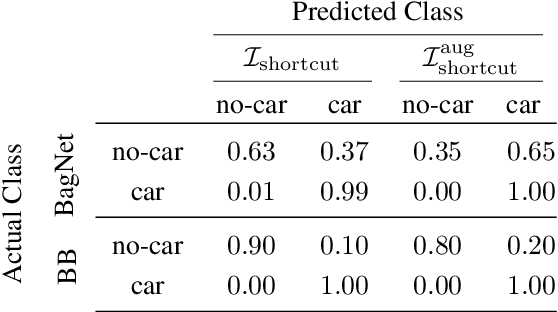

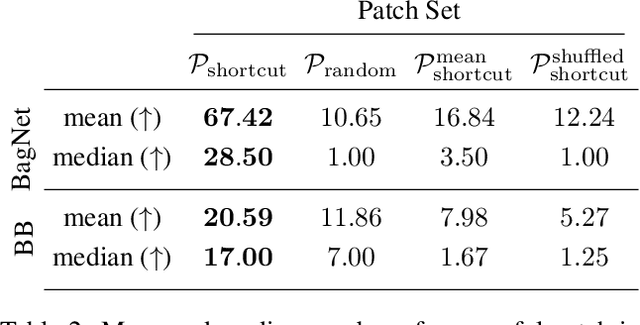
An important pillar for safe machine learning (ML) is the systematic mitigation of weaknesses in neural networks to afford their deployment in critical applications. An ubiquitous class of safety risks are learned shortcuts, i.e. spurious correlations a network exploits for its decisions that have no semantic connection to the actual task. Networks relying on such shortcuts bear the risk of not generalizing well to unseen inputs. Explainability methods help to uncover such network vulnerabilities. However, many of these techniques are not directly applicable if access to the network is constrained, in so-called black-box setups. These setups are prevalent when using third-party ML components. To address this constraint, we present an approach to detect learned shortcuts using an interpretable-by-design network as a proxy to the black-box model of interest. Leveraging the proxy's guarantees on introspection we automatically extract candidates for learned shortcuts. Their transferability to the black box is validated in a systematic fashion. Concretely, as proxy model we choose a BagNet, which bases its decisions purely on local image patches. We demonstrate on the autonomous driving dataset A2D2 that extracted patch shortcuts significantly influence the black box model. By efficiently identifying such patch-based vulnerabilities, we contribute to safer ML models.
Approaching Neural Network Uncertainty Realism
Jan 08, 2021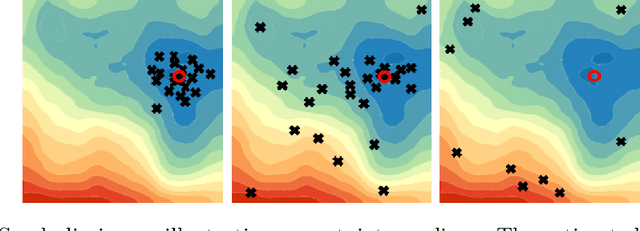
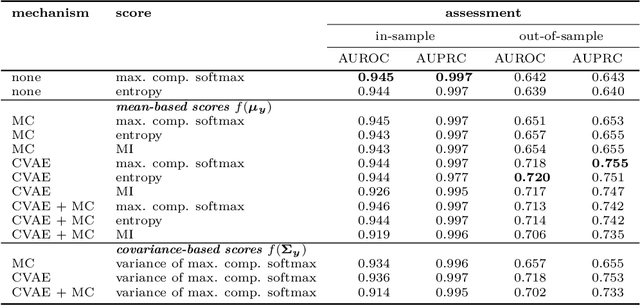
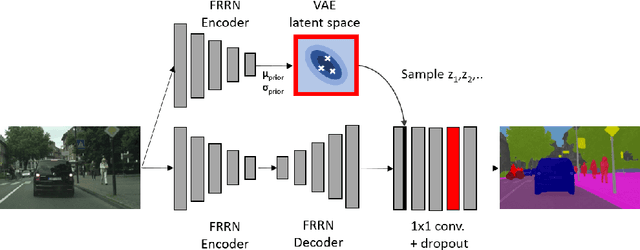
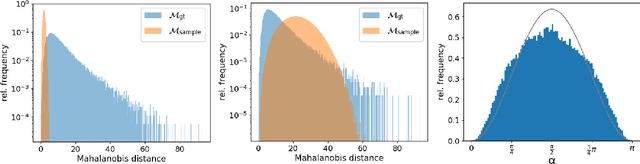
Statistical models are inherently uncertain. Quantifying or at least upper-bounding their uncertainties is vital for safety-critical systems such as autonomous vehicles. While standard neural networks do not report this information, several approaches exist to integrate uncertainty estimates into them. Assessing the quality of these uncertainty estimates is not straightforward, as no direct ground truth labels are available. Instead, implicit statistical assessments are required. For regression, we propose to evaluate uncertainty realism -- a strict quality criterion -- with a Mahalanobis distance-based statistical test. An empirical evaluation reveals the need for uncertainty measures that are appropriate to upper-bound heavy-tailed empirical errors. Alongside, we transfer the variational U-Net classification architecture to standard supervised image-to-image tasks. We adopt it to the automotive domain and show that it significantly improves uncertainty realism compared to a plain encoder-decoder model.
A Novel Regression Loss for Non-Parametric Uncertainty Optimization
Jan 07, 2021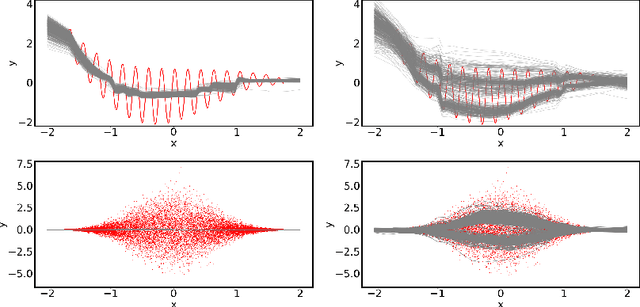
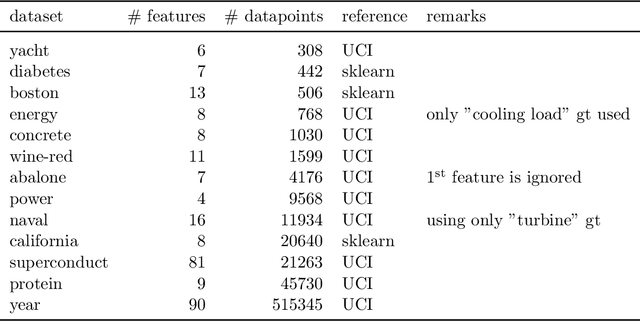
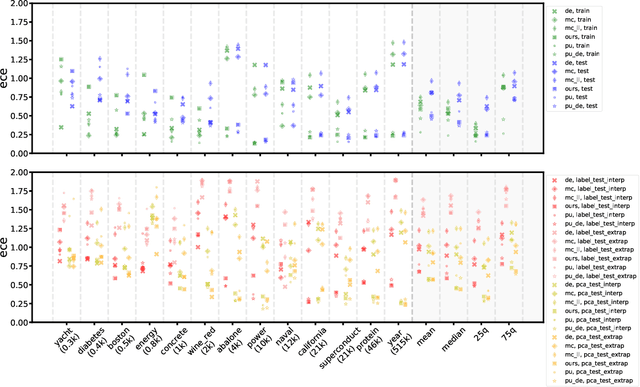
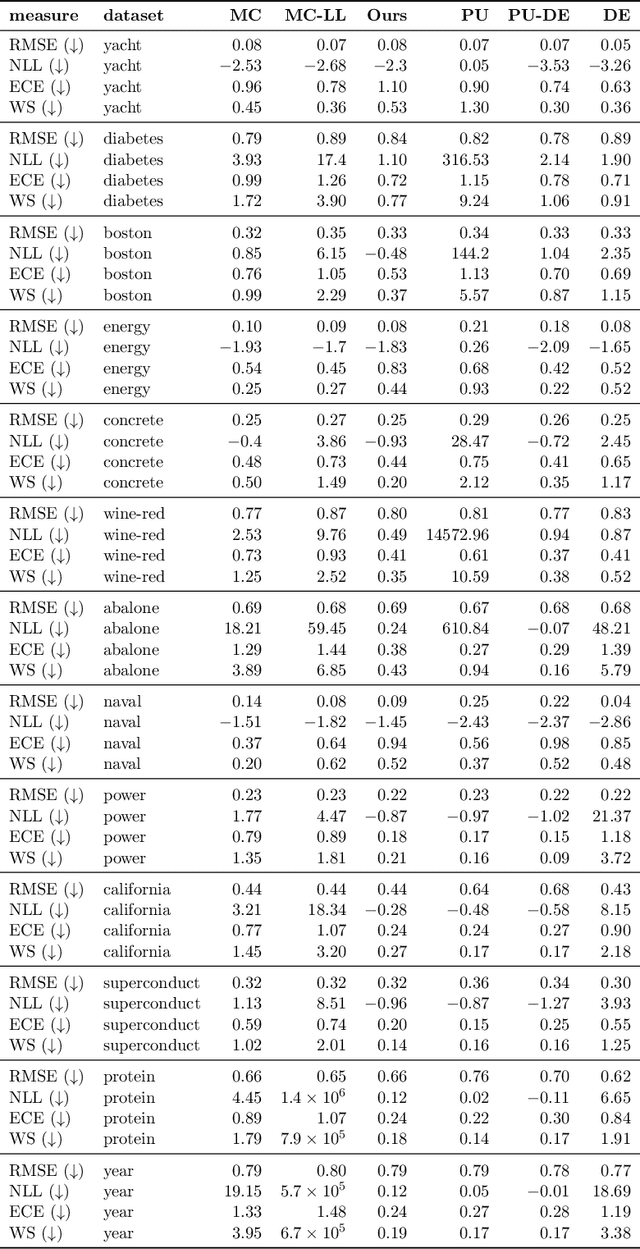
Quantification of uncertainty is one of the most promising approaches to establish safe machine learning. Despite its importance, it is far from being generally solved, especially for neural networks. One of the most commonly used approaches so far is Monte Carlo dropout, which is computationally cheap and easy to apply in practice. However, it can underestimate the uncertainty. We propose a new objective, referred to as second-moment loss (SML), to address this issue. While the full network is encouraged to model the mean, the dropout networks are explicitly used to optimize the model variance. We intensively study the performance of the new objective on various UCI regression datasets. Comparing to the state-of-the-art of deep ensembles, SML leads to comparable prediction accuracies and uncertainty estimates while only requiring a single model. Under distribution shift, we observe moderate improvements. As a side result, we introduce an intuitive Wasserstein distance-based uncertainty measure that is non-saturating and thus allows to resolve quality differences between any two uncertainty estimates.
Second-Moment Loss: A Novel Regression Objective for Improved Uncertainties
Dec 23, 2020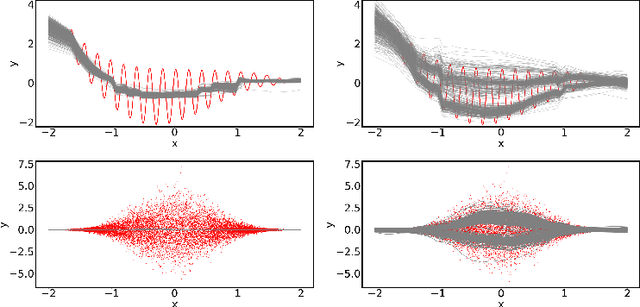
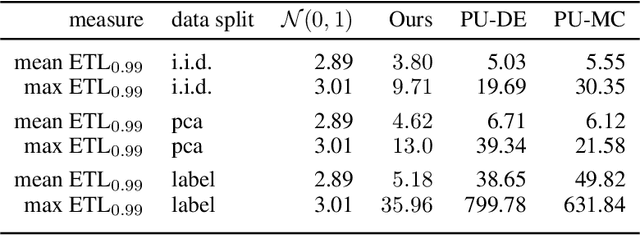
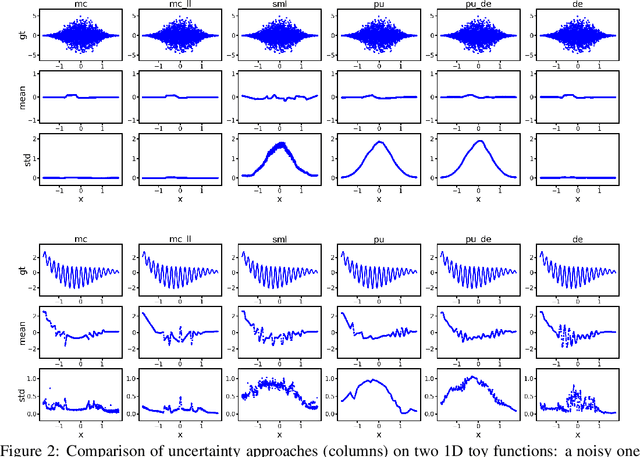
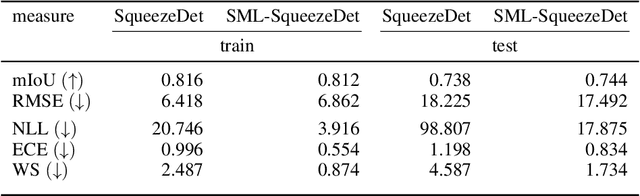
Quantification of uncertainty is one of the most promising approaches to establish safe machine learning. Despite its importance, it is far from being generally solved, especially for neural networks. One of the most commonly used approaches so far is Monte Carlo dropout, which is computationally cheap and easy to apply in practice. However, it can underestimate the uncertainty. We propose a new objective, referred to as second-moment loss (SML), to address this issue. While the full network is encouraged to model the mean, the dropout networks are explicitly used to optimize the model variance. We analyze the performance of the new objective on various toy and UCI regression datasets. Comparing to the state-of-the-art of deep ensembles, SML leads to comparable prediction accuracies and uncertainty estimates while only requiring a single model. Under distribution shift, we observe moderate improvements. From a safety perspective also the study of worst-case uncertainties is crucial. In this regard we improve considerably. Finally, we show that SML can be successfully applied to SqueezeDet, a modern object detection network. We improve on its uncertainty-related scores while not deteriorating regression quality. As a side result, we introduce an intuitive Wasserstein distance-based uncertainty measure that is non-saturating and thus allows to resolve quality differences between any two uncertainty estimates.
DenseHMM: Learning Hidden Markov Models by Learning Dense Representations
Dec 17, 2020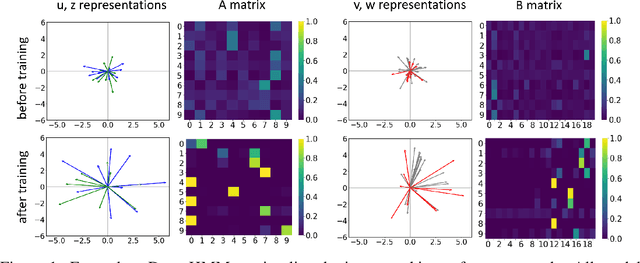
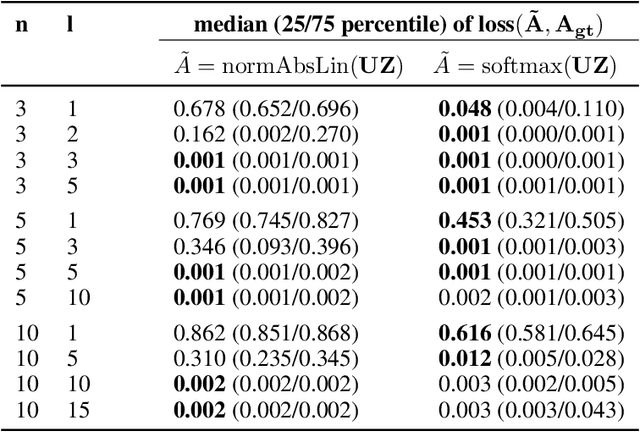
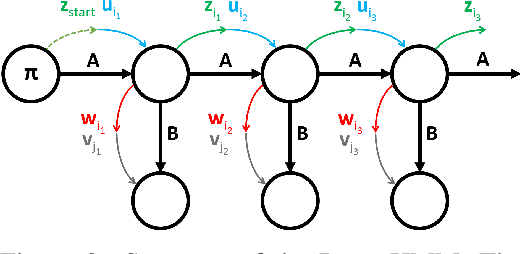
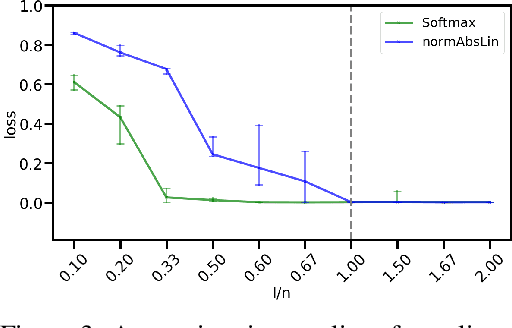
We propose DenseHMM - a modification of Hidden Markov Models (HMMs) that allows to learn dense representations of both the hidden states and the observables. Compared to the standard HMM, transition probabilities are not atomic but composed of these representations via kernelization. Our approach enables constraint-free and gradient-based optimization. We propose two optimization schemes that make use of this: a modification of the Baum-Welch algorithm and a direct co-occurrence optimization. The latter one is highly scalable and comes empirically without loss of performance compared to standard HMMs. We show that the non-linearity of the kernelization is crucial for the expressiveness of the representations. The properties of the DenseHMM like learned co-occurrences and log-likelihoods are studied empirically on synthetic and biomedical datasets.