 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerwise Linear Mode Connectivity
Paper and Code
Jul 13, 2023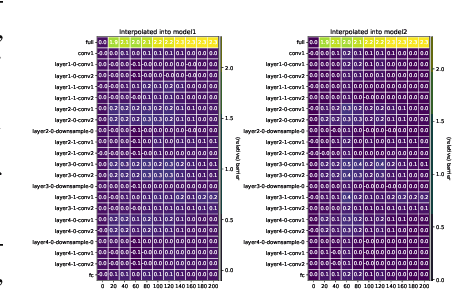

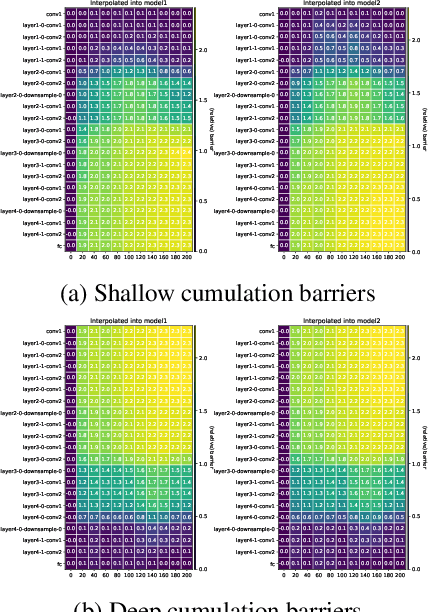
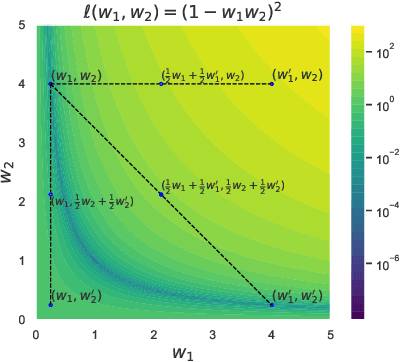
In the federated setup one performs an aggregation of separate local models multiple times during training in order to obtain a stronger global model; most often aggregation is a simple averaging of the parameters. Understanding when and why averaging works in a non-convex setup, such as federated deep learning, is an open challenge that hinders obtaining highly performant global models. On i.i.d.~datasets federated deep learning with frequent averaging is successful. The common understanding, however, is that during the independent training models are drifting away from each other and thus averaging may not work anymore after many local parameter updates. The problem can be seen from the perspective of the loss surface: for points on a non-convex surface the average can become arbitrarily bad. The assumption of local convexity, often used to explain the success of federated averaging, contradicts to the empirical evidence showing that high loss barriers exist between models from the very beginning of the learning, even when training on the same data. Based on the observation that the learning process evolves differently in different layers, we investigate the barrier between models in a layerwise fashion. Our conjecture is that barriers preventing from successful federated training are caused by a particular layer or group of layers.