 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion of Graph Neural Networks via Optimal Transport
Mar 27, 2025In this paper, we explore the idea of combining GCNs into one model. To that end, we align the weights of different models layer-wise using optimal transport (OT). We present and evaluate three types of transportation costs and show that the studied fusion method consistently outperforms the performance of vanilla averaging. Finally, we present results suggesting that model fusion using OT is harder in the case of GCNs than MLPs and that incorporating the graph structure into the process does not improve the performance of the method.
Position: Curvature Matrices Should Be Democratized via Linear Operators
Jan 31, 2025



Structured large matrices are prevalent in machine learning. A particularly important class is curvature matrices like the Hessian, which are central to understanding the loss landscape of neural nets (NNs), and enable second-order optimization, uncertainty quantification, model pruning, data attribution, and more. However, curvature computations can be challenging due to the complexity of automatic differentiation, and the variety and structural assumptions of curvature proxies, like sparsity and Kronecker factorization. In this position paper, we argue that linear operators -- an interface for performing matrix-vector products -- provide a general, scalable, and user-friendly abstraction to handle curvature matrices. To support this position, we developed $\textit{curvlinops}$, a library that provides curvature matrices through a unified linear operator interface. We demonstrate with $\textit{curvlinops}$ how this interface can hide complexity, simplify applications, be extensible and interoperable with other libraries, and scale to large NNs.
What Does It Mean to Be a Transformer? Insights from a Theoretical Hessian Analysis
Oct 14, 2024



The Transformer architecture has inarguably revolutionized deep learning, overtaking classical architectures like multi-layer perceptrons (MLPs) and convolutional neural networks (CNNs). At its core, the attention block differs in form and functionality from most other architectural components in deep learning -- to the extent that Transformers are often accompanied by adaptive optimizers, layer normalization, learning rate warmup, and more, in comparison to MLPs/CNNs. The root causes behind these outward manifestations, and the precise mechanisms that govern them, remain poorly understood. In this work, we bridge this gap by providing a fundamental understanding of what distinguishes the Transformer from the other architectures -- grounded in a theoretical comparison of the (loss) Hessian. Concretely, for a single self-attention layer, (a) we first entirely derive the Transformer's Hessian and express it in matrix derivatives; (b) we then characterize it in terms of data, weight, and attention moment dependencies; and (c) while doing so further highlight the important structural differences to the Hessian of classical networks. Our results suggest that various common architectural and optimization choices in Transformers can be traced back to their highly non-linear dependencies on the data and weight matrices, which vary heterogeneously across parameters. Ultimately, our findings provide a deeper understanding of the Transformer's unique optimization landscape and the challenges it poses.
Standardizing Structural Causal Models
Jun 17, 2024



Synthetic datasets generated by structural causal models (SCMs) are commonly used for benchmarking causal structure learning algorithms. However, the variances and pairwise correlations in SCM data tend to increase along the causal ordering. Several popular algorithms exploit these artifacts, possibly leading to conclusions that do not generalize to real-world settings. Existing metrics like $\operatorname{Var}$-sortability and $\operatorname{R^2}$-sortability quantify these patterns, but they do not provide tools to remedy them. To address this, we propose internally-standardized structural causal models (iSCMs), a modification of SCMs that introduces a standardization operation at each variable during the generative process. By construction, iSCMs are not $\operatorname{Var}$-sortable, and as we show experimentally, not $\operatorname{R^2}$-sortable either for commonly-used graph families. Moreover, contrary to the post-hoc standardization of data generated by standard SCMs, we prove that linear iSCMs are less identifiable from prior knowledge on the weights and do not collapse to deterministic relationships in large systems, which may make iSCMs a useful model in causal inference beyond the benchmarking problem studied here.
Transition Constrained Bayesian Optimization via Markov Decision Processes
Feb 13, 2024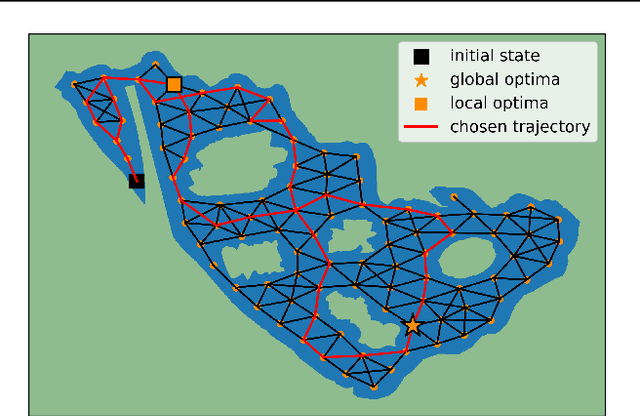
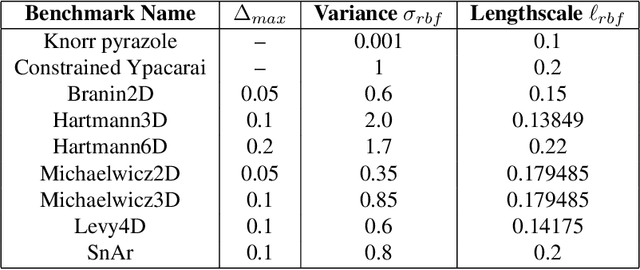
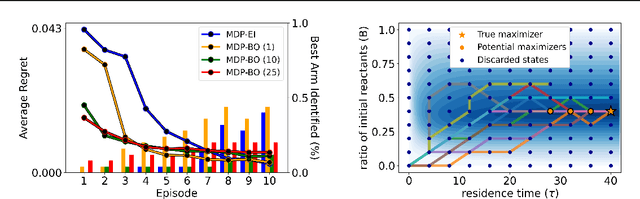
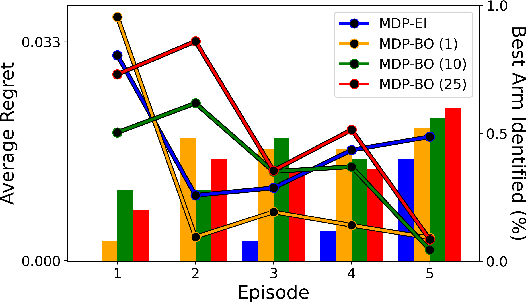
Bayesian optimization is a methodology to optimize black-box functions. Traditionally, it focuses on the setting where you can arbitrarily query the search space. However, many real-life problems do not offer this flexibility; in particular, the search space of the next query may depend on previous ones. Example challenges arise in the physical sciences in the form of local movement constraints, required monotonicity in certain variables, and transitions influencing the accuracy of measurements. Altogether, such transition constraints necessitate a form of planning. This work extends Bayesian optimization via the framework of Markov Decision Processes, iteratively solving a tractable linearization of our objective using reinforcement learning to obtain a policy that plans ahead over long horizons. The resulting policy is potentially history-dependent and non-Markovian. We showcase applications in chemical reactor optimization, informative path planning, machine calibration, and other synthetic examples.
Estimating value at risk: LSTM vs. GARCH
Jul 21, 2022
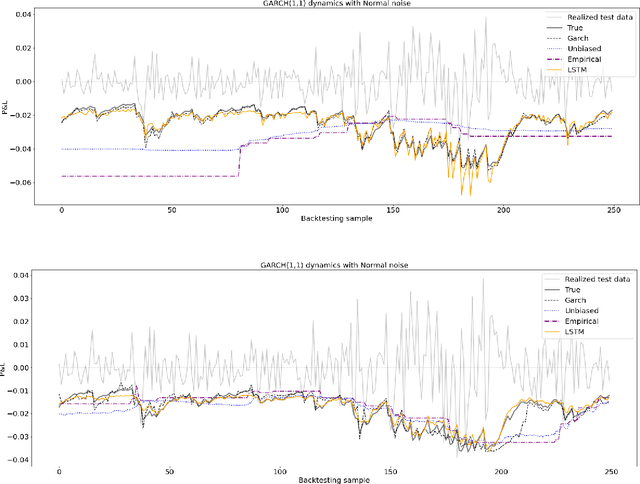
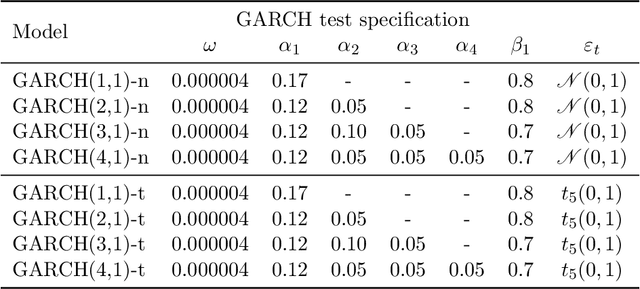

Estimating value-at-risk on time series data with possibly heteroscedastic dynamics is a highly challenging task. Typically, we face a small data problem in combination with a high degree of non-linearity, causing difficulties for both classical and machine-learning estimation algorithms. In this paper, we propose a novel value-at-risk estimator using a long short-term memory (LSTM) neural network and compare its performance to benchmark GARCH estimators. Our results indicate that even for a relatively short time series, the LSTM could be used to refine or monitor risk estimation processes and correctly identify the underlying risk dynamics in a non-parametric fashion. We evaluate the estimator on both simulated and market data with a focus on heteroscedasticity, finding that LSTM exhibits a similar performance to GARCH estimators on simulated data, whereas on real market data it is more sensitive towards increasing or decreasing volatility and outperforms all existing estimators of value-at-risk in terms of exception rate and mean quantile score.