 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransition Constrained Bayesian Optimization via Markov Decision Processes
Paper and Code
Feb 13, 2024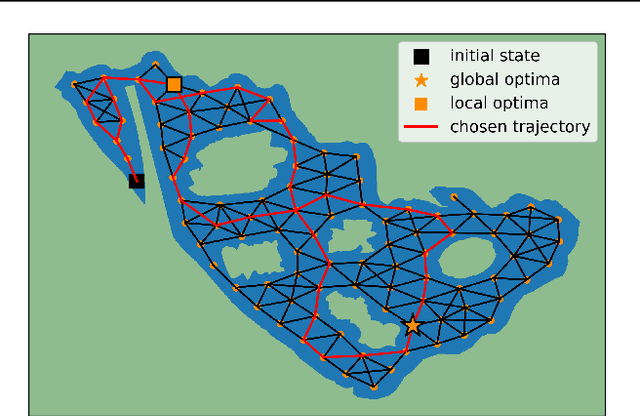
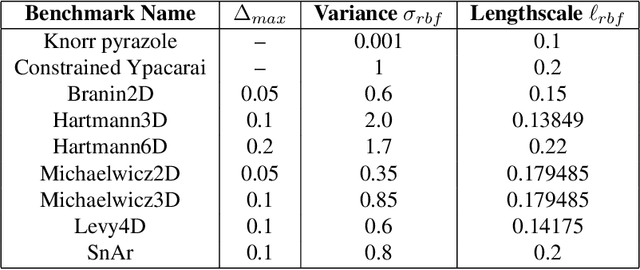
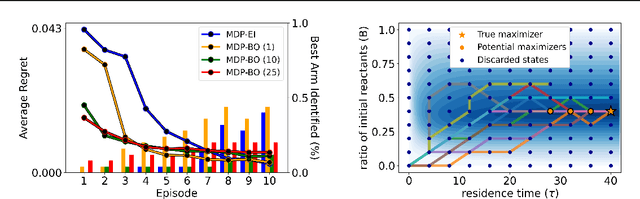
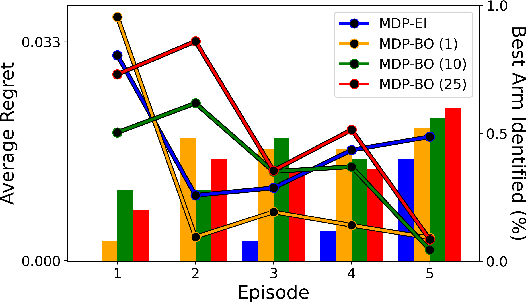
Bayesian optimization is a methodology to optimize black-box functions. Traditionally, it focuses on the setting where you can arbitrarily query the search space. However, many real-life problems do not offer this flexibility; in particular, the search space of the next query may depend on previous ones. Example challenges arise in the physical sciences in the form of local movement constraints, required monotonicity in certain variables, and transitions influencing the accuracy of measurements. Altogether, such transition constraints necessitate a form of planning. This work extends Bayesian optimization via the framework of Markov Decision Processes, iteratively solving a tractable linearization of our objective using reinforcement learning to obtain a policy that plans ahead over long horizons. The resulting policy is potentially history-dependent and non-Markovian. We showcase applications in chemical reactor optimization, informative path planning, machine calibration, and other synthetic examples.