 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
Dec 19, 2025



Prevailing Vision-Language-Action Models (VLAs) for robotic manipulation are built upon vision-language backbones pretrained on large-scale, but disconnected static web data. As a result, despite improved semantic generalization, the policy must implicitly infer complex physical dynamics and temporal dependencies solely from robot trajectories. This reliance creates an unsustainable data burden, necessitating continuous, large-scale expert data collection to compensate for the lack of innate physical understanding. We contend that while vision-language pretraining effectively captures semantic priors, it remains blind to physical causality. A more effective paradigm leverages video to jointly capture semantics and visual dynamics during pretraining, thereby isolating the remaining task of low-level control. To this end, we introduce mimic-video, a novel Video-Action Model (VAM) that pairs a pretrained Internet-scale video model with a flow matching-based action decoder conditioned on its latent representations. The decoder serves as an Inverse Dynamics Model (IDM), generating low-level robot actions from the latent representation of video-space action plans. Our extensive evaluation shows that our approach achieves state-of-the-art performance on simulated and real-world robotic manipulation tasks, improving sample efficiency by 10x and convergence speed by 2x compared to traditional VLA architectures.
mimic-one: a Scalable Model Recipe for General Purpose Robot Dexterity
Jun 13, 2025
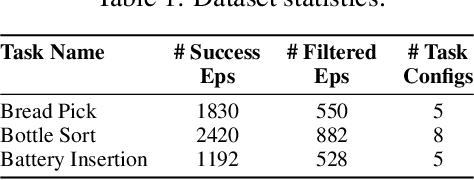

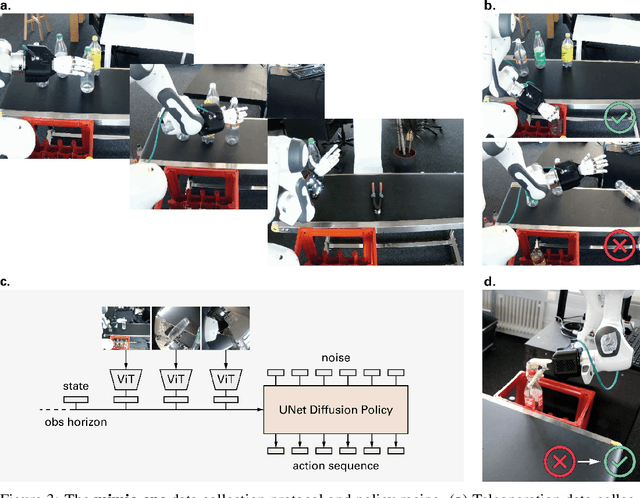
We present a diffusion-based model recipe for real-world control of a highly dexterous humanoid robotic hand, designed for sample-efficient learning and smooth fine-motor action inference. Our system features a newly designed 16-DoF tendon-driven hand, equipped with wide angle wrist cameras and mounted on a Franka Emika Panda arm. We develop a versatile teleoperation pipeline and data collection protocol using both glove-based and VR interfaces, enabling high-quality data collection across diverse tasks such as pick and place, item sorting and assembly insertion. Leveraging high-frequency generative control, we train end-to-end policies from raw sensory inputs, enabling smooth, self-correcting motions in complex manipulation scenarios. Real-world evaluations demonstrate up to 93.3% out of distribution success rates, with up to a +33.3% performance boost due to emergent self-correcting behaviors, while also revealing scaling trends in policy performance. Our results advance the state-of-the-art in dexterous robotic manipulation through a fully integrated, practical approach to hardware, learning, and real-world deployment.
Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning
Oct 19, 2023



Reinforcement learning (RL) requires either manually specifying a reward function, which is often infeasible, or learning a reward model from a large amount of human feedback, which is often very expensive. We study a more sample-efficient alternative: using pretrained vision-language models (VLMs) as zero-shot reward models (RMs) to specify tasks via natural language. We propose a natural and general approach to using VLMs as reward models, which we call VLM-RMs. We use VLM-RMs based on CLIP to train a MuJoCo humanoid to learn complex tasks without a manually specified reward function, such as kneeling, doing the splits, and sitting in a lotus position. For each of these tasks, we only provide a single sentence text prompt describing the desired task with minimal prompt engineering. We provide videos of the trained agents at: https://sites.google.com/view/vlm-rm. We can improve performance by providing a second ``baseline'' prompt and projecting out parts of the CLIP embedding space irrelevant to distinguish between goal and baseline. Further, we find a strong scaling effect for VLM-RMs: larger VLMs trained with more compute and data are better reward models. The failure modes of VLM-RMs we encountered are all related to known capability limitations of current VLMs, such as limited spatial reasoning ability or visually unrealistic environments that are far off-distribution for the VLM. We find that VLM-RMs are remarkably robust as long as the VLM is large enough. This suggests that future VLMs will become more and more useful reward models for a wide range of RL applications.