 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhole-Body Control of a Mobile Manipulator using End-to-End Reinforcement Learning
Paper and Code

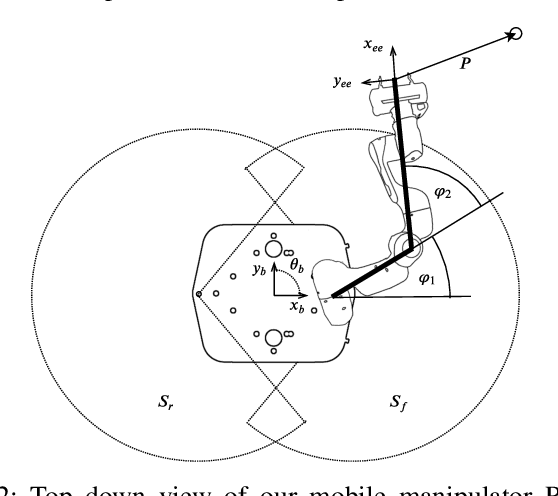
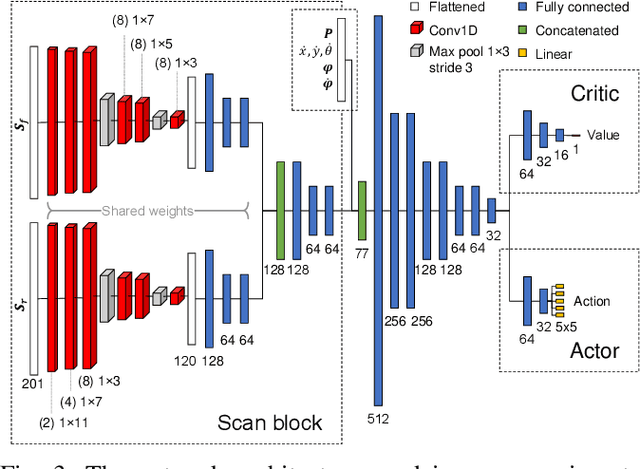

Mobile manipulation is usually achieved by sequentially executing base and manipulator movements. This simplification, however, leads to a loss in efficiency and in some cases a reduction of workspace size. Even though different methods have been proposed to solve Whole-Body Control (WBC) online, they are either limited by a kinematic model or do not allow for reactive, online obstacle avoidance. In order to overcome these drawbacks, in this work, we propose an end-to-end Reinforcement Learning (RL) approach to WBC. We compared our learned controller against a state-of-the-art sampling-based method in simulation and achieved faster overall mission times. In addition, we validated the learned policy on our mobile manipulator RoyalPanda in challenging narrow corridor environments.