 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable deep learning reveals the physical mechanisms behind the turbulent kinetic energy equation
Jan 27, 2026In this work, we investigate the physical mechanisms governing turbulent kinetic energy transport using explainable deep learning (XDL). An XDL model based on SHapley Additive exPlanations (SHAP) is used to identify and percolate high-importance structures for the evolution of the turbulent kinetic energy budget terms of a turbulent channel flow at a friction Reynolds number of $Re_τ= 125$. The results show that the important structures are predominantly located in the near-wall region and are more frequently associated with sweep-type events. In the viscous layer, the SHAP structures relevant for production and viscous diffusion are almost entirely contained within those relevant for dissipation, revealing a clear hierarchical organization of near-wall turbulence. In the outer layer, this hierarchical organization breaks down and only velocity-pressure-gradient correlation and turbulent transport SHAP structures remain, with a moderate spatial coincidence of approximately $60\%$. Finally, we show that none of the coherent structures classically studied in turbulence are capable of representing the mechanisms behind the various terms of the turbulent kinetic energy budget throughout the channel. These results reveal dissipation as the dominant organizing mechanism of near-wall turbulence, constraining production and viscous diffusion within a single structural hierarchy that breaks down in the outer layer.
GenDA: Generative Data Assimilation on Complex Urban Areas via Classifier-Free Diffusion Guidance
Jan 16, 2026Urban wind flow reconstruction is essential for assessing air quality, heat dispersion, and pedestrian comfort, yet remains challenging when only sparse sensor data are available. We propose GenDA, a generative data assimilation framework that reconstructs high-resolution wind fields on unstructured meshes from limited observations. The model employs a multiscale graph-based diffusion architecture trained on computational fluid dynamics (CFD) simulations and interprets classifier-free guidance as a learned posterior reconstruction mechanism: the unconditional branch learns a geometry-aware flow prior, while the sensor-conditioned branch injects observational constraints during sampling. This formulation enables obstacle-aware reconstruction and generalization across unseen geometries, wind directions, and mesh resolutions without retraining. We consider both sparse fixed sensors and trajectory-based observations using the same reconstruction procedure. When evaluated against supervised graph neural network (GNN) baselines and classical reduced-order data assimilation methods, GenDA reduces the relative root-mean-square error (RRMSE) by 25-57% and increases the structural similarity index (SSIM) by 23-33% across the tested meshes. Experiments are conducted on Reynolds-averaged Navier-Stokes (RANS) simulations of a real urban neighbourhood in Bristol, United Kingdom, at a characteristic Reynolds number of $\mathrm{Re}\approx2\times10^{7}$, featuring complex building geometry and irregular terrain. The proposed framework provides a scalable path toward generative, geometry-aware data assimilation for environmental monitoring in complex domains.
Mode-Seeking for Inverse Problems with Diffusion Models
Dec 11, 2025A pre-trained unconditional diffusion model, combined with posterior sampling or maximum a posteriori (MAP) estimation techniques, can solve arbitrary inverse problems without task-specific training or fine-tuning. However, existing posterior sampling and MAP estimation methods often rely on modeling approximations and can be computationally demanding. In this work, we propose the variational mode-seeking loss (VML), which, when minimized during each reverse diffusion step, guides the generated sample towards the MAP estimate. VML arises from a novel perspective of minimizing the Kullback-Leibler (KL) divergence between the diffusion posterior $p(\mathbf{x}_0|\mathbf{x}_t)$ and the measurement posterior $p(\mathbf{x}_0|\mathbf{y})$, where $\mathbf{y}$ denotes the measurement. Importantly, for linear inverse problems, VML can be analytically derived and need not be approximated. Based on further theoretical insights, we propose VML-MAP, an empirically effective algorithm for solving inverse problems, and validate its efficacy over existing methods in both performance and computational time, through extensive experiments on diverse image-restoration tasks across multiple datasets.
Shocks Under Control: Taming Transonic Compressible Flow over an RAE2822 Airfoil with Deep Reinforcement Learning
Nov 10, 2025Active flow control of compressible transonic shock-boundary layer interactions over a two-dimensional RAE2822 airfoil at Re = 50,000 is investigated using deep reinforcement learning (DRL). The flow field exhibits highly unsteady dynamics, including complex shock-boundary layer interactions, shock oscillations, and the generation of Kutta waves from the trailing edge. A high-fidelity CFD solver, employing a fifth-order spectral discontinuous Galerkin scheme in space and a strong-stability-preserving Runge-Kutta (5,4) method in time, together with adaptive mesh refinement capability, is used to obtain the accurate flow field. Synthetic jet actuation is employed to manipulate these unsteady flow features, while the DRL agent autonomously discovers effective control strategies through direct interaction with high-fidelity compressible flow simulations. The trained controllers effectively mitigate shock-induced separation, suppress unsteady oscillations, and manipulate aerodynamic forces under transonic conditions. In the first set of experiments, aimed at both drag reduction and lift enhancement, the DRL-based control reduces the average drag coefficient by 13.78% and increases lift by 131.18%, thereby improving the lift-to-drag ratio by 121.52%, which underscores its potential for managing complex flow dynamics. In the second set, targeting drag reduction while maintaining lift, the DRL-based control achieves a 25.62% reduction in drag and a substantial 196.30% increase in lift, accompanied by markedly diminished oscillations. In this case, the lift-to-drag ratio improves by 220.26%.
Efficient probabilistic surrogate modeling techniques for partially-observed large-scale dynamical systems
Nov 06, 2025This paper is concerned with probabilistic techniques for forecasting dynamical systems described by partial differential equations (such as, for example, the Navier-Stokes equations). In particular, it is investigating and comparing various extensions to the flow matching paradigm that reduce the number of sampling steps. In this regard, it compares direct distillation, progressive distillation, adversarial diffusion distillation, Wasserstein GANs and rectified flows. Moreover, experiments are conducted on a set of challenging systems. In particular, we also address the challenge of directly predicting 2D slices of large-scale 3D simulations, paving the way for efficient inflow generation for solvers.
Deep Learning-Driven Downscaling for Climate Risk Assessment of Projected Temperature Extremes in the Nordic Region
Nov 05, 2025
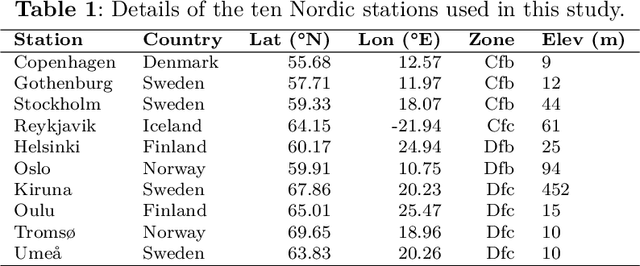


Rapid changes and increasing climatic variability across the widely varied Koppen-Geiger regions of northern Europe generate significant needs for adaptation. Regional planning needs high-resolution projected temperatures. This work presents an integrative downscaling framework that incorporates Vision Transformer (ViT), Convolutional Long Short-Term Memory (ConvLSTM), and Geospatial Spatiotemporal Transformer with Attention and Imbalance-Aware Network (GeoStaNet) models. The framework is evaluated with a multicriteria decision system, Deep Learning-TOPSIS (DL-TOPSIS), for ten strategically chosen meteorological stations encompassing the temperate oceanic (Cfb), subpolar oceanic (Cfc), warm-summer continental (Dfb), and subarctic (Dfc) climate regions. Norwegian Earth System Model (NorESM2-LM) Coupled Model Intercomparison Project Phase 6 (CMIP6) outputs were bias-corrected during the 1951-2014 period and subsequently validated against earlier observations of day-to-day temperature metrics and diurnal range statistics. The ViT showed improved performance (Root Mean Squared Error (RMSE): 1.01 degrees C; R^2: 0.92), allowing for production of credible downscaled projections. Under the SSP5-8.5 scenario, the Dfc and Dfb climate zones are projected to warm by 4.8 degrees C and 3.9 degrees C, respectively, by 2100, with expansion in the diurnal temperature range by more than 1.5 degrees C. The Time of Emergence signal first appears in subarctic winter seasons (Dfc: approximately 2032), signifying an urgent need for adaptation measures. The presented framework offers station-based, high-resolution estimates of uncertainties and extremes, with direct uses for adaptation policy over high-latitude regions with fast environmental change.
Potential and challenges of generative adversarial networks for super-resolution in 4D Flow MRI
Aug 20, 20254D Flow Magnetic Resonance Imaging (4D Flow MRI) enables non-invasive quantification of blood flow and hemodynamic parameters. However, its clinical application is limited by low spatial resolution and noise, particularly affecting near-wall velocity measurements. Machine learning-based super-resolution has shown promise in addressing these limitations, but challenges remain, not least in recovering near-wall velocities. Generative adversarial networks (GANs) offer a compelling solution, having demonstrated strong capabilities in restoring sharp boundaries in non-medical super-resolution tasks. Yet, their application in 4D Flow MRI remains unexplored, with implementation challenged by known issues such as training instability and non-convergence. In this study, we investigate GAN-based super-resolution in 4D Flow MRI. Training and validation were conducted using patient-specific cerebrovascular in-silico models, converted into synthetic images via an MR-true reconstruction pipeline. A dedicated GAN architecture was implemented and evaluated across three adversarial loss functions: Vanilla, Relativistic, and Wasserstein. Our results demonstrate that the proposed GAN improved near-wall velocity recovery compared to a non-adversarial reference (vNRMSE: 6.9% vs. 9.6%); however, that implementation specifics are critical for stable network training. While Vanilla and Relativistic GANs proved unstable compared to generator-only training (vNRMSE: 8.1% and 7.8% vs. 7.2%), a Wasserstein GAN demonstrated optimal stability and incremental improvement (vNRMSE: 6.9% vs. 7.2%). The Wasserstein GAN further outperformed the generator-only baseline at low SNR (vNRMSE: 8.7% vs. 10.7%). These findings highlight the potential of GAN-based super-resolution in enhancing 4D Flow MRI, particularly in challenging cerebrovascular regions, while emphasizing the need for careful selection of adversarial strategies.
Evaluating Visual Mathematics in Multimodal LLMs: A Multilingual Benchmark Based on the Kangaroo Tests
Jun 09, 2025Multimodal Large Language Models (MLLMs) promise advanced vision language capabilities, yet their effectiveness in visually presented mathematics remains underexplored. This paper analyzes the development and evaluation of MLLMs for mathematical problem solving, focusing on diagrams, multilingual text, and symbolic notation. We then assess several models, including GPT 4o, Pixtral, Qwen VL, Llama 3.2 Vision variants, and Gemini 2.0 Flash in a multilingual Kangaroo style benchmark spanning English, French, Spanish, and Catalan. Our experiments reveal four key findings. First, overall precision remains moderate across geometry, visual algebra, logic, patterns, and combinatorics: no single model excels in every topic. Second, while most models see improved accuracy with questions that do not have images, the gain is often limited; performance for some remains nearly unchanged without visual input, indicating underutilization of diagrammatic information. Third, substantial variation exists across languages and difficulty levels: models frequently handle easier items but struggle with advanced geometry and combinatorial reasoning. Notably, Gemini 2.0 Flash achieves the highest precision on image based tasks, followed by Qwen VL 2.5 72B and GPT 4o, though none approach human level performance. Fourth, a complementary analysis aimed at distinguishing whether models reason or simply recite reveals that Gemini and GPT 4o stand out for their structured reasoning and consistent accuracy. In contrast, Pixtral and Llama exhibit less consistent reasoning, often defaulting to heuristics or randomness when unable to align their outputs with the given answer options.
Regional climate projections using a deep-learning-based model-ranking and downscaling framework: Application to European climate zones
Feb 28, 2025Accurate regional climate forecast calls for high-resolution downscaling of Global Climate Models (GCMs). This work presents a deep-learning-based multi-model evaluation and downscaling framework ranking 32 Coupled Model Intercomparison Project Phase 6 (CMIP6) models using a Deep Learning-TOPSIS (DL-TOPSIS) mechanism and so refines outputs using advanced deep-learning models. Using nine performance criteria, five K\"oppen-Geiger climate zones -- Tropical, Arid, Temperate, Continental, and Polar -- are investigated over four seasons. While TaiESM1 and CMCC-CM2-SR5 show notable biases, ranking results show that NorESM2-LM, GISS-E2-1-G, and HadGEM3-GC31-LL outperform other models. Four models contribute to downscaling the top-ranked GCMs to 0.1$^{\circ}$ resolution: Vision Transformer (ViT), Geospatial Spatiotemporal Transformer with Attention and Imbalance-Aware Network (GeoSTANet), CNN-LSTM, and CNN-Long Short-Term Memory (ConvLSTM). Effectively capturing temperature extremes (TXx, TNn), GeoSTANet achieves the highest accuracy (Root Mean Square Error (RMSE) = 1.57$^{\circ}$C, Kling-Gupta Efficiency (KGE) = 0.89, Nash-Sutcliffe Efficiency (NSE) = 0.85, Correlation ($r$) = 0.92), so reducing RMSE by 20% over ConvLSTM. CNN-LSTM and ConvLSTM do well in Continental and Temperate zones; ViT finds fine-scale temperature fluctuations difficult. These results confirm that multi-criteria ranking improves GCM selection for regional climate studies and transformer-based downscaling exceeds conventional deep-learning methods. This framework offers a scalable method to enhance high-resolution climate projections, benefiting impact assessments and adaptation plans.
Towards Robust Spatio-Temporal Auto-Regressive Prediction: Adams-Bashforth Time Integration with Adaptive Multi-Step Rollout
Dec 07, 2024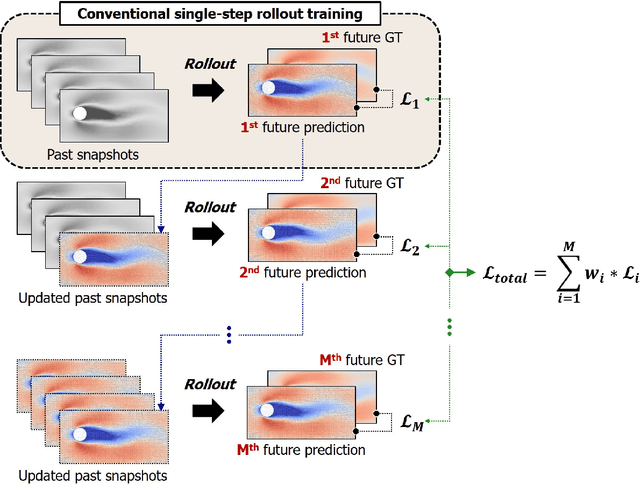
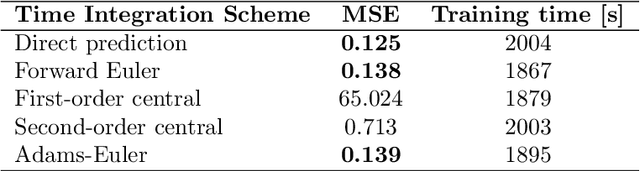
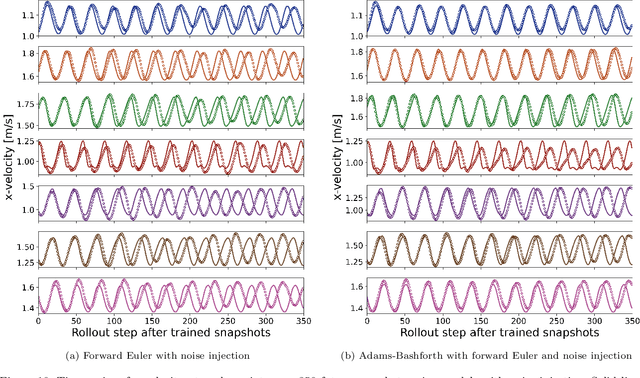
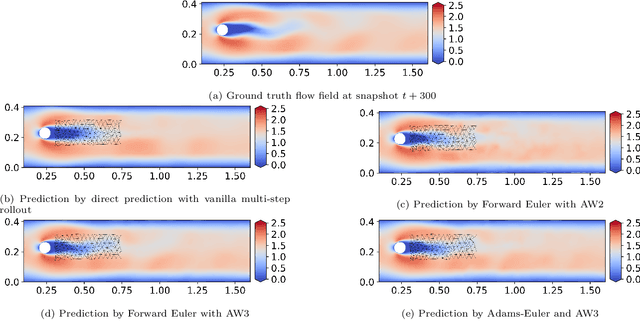
This study addresses the critical challenge of error accumulation in spatio-temporal auto-regressive predictions within scientific machine learning models by introducing innovative temporal integration schemes and adaptive multi-step rollout strategies. We present a comprehensive analysis of time integration methods, highlighting the adaptation of the two-step Adams-Bashforth scheme to enhance long-term prediction robustness in auto-regressive models. Additionally, we improve temporal prediction accuracy through a multi-step rollout strategy that incorporates multiple future time steps during training, supported by three newly proposed approaches that dynamically adjust the importance of each future step. By integrating the Adams-Bashforth scheme with adaptive multi-step strategies, our graph neural network-based auto-regressive model accurately predicts 350 future time steps, even under practical constraints such as limited training data and minimal model capacity -- achieving an error of only 1.6% compared to the vanilla auto-regressive approach. Moreover, our framework demonstrates an 83% improvement in rollout performance over the standard noise injection method, a standard technique for enhancing long-term rollout performance. Its effectiveness is further validated in more challenging scenarios with truncated meshes, showcasing its adaptability and robustness in practical applications. This work introduces a versatile framework for robust long-term spatio-temporal auto-regressive predictions, effectively mitigating error accumulation across various model types and engineering discipline.