 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced deep-reinforcement-learning methods for flow control: group-invariant and positional-encoding networks improve learning speed and quality
Jul 25, 2024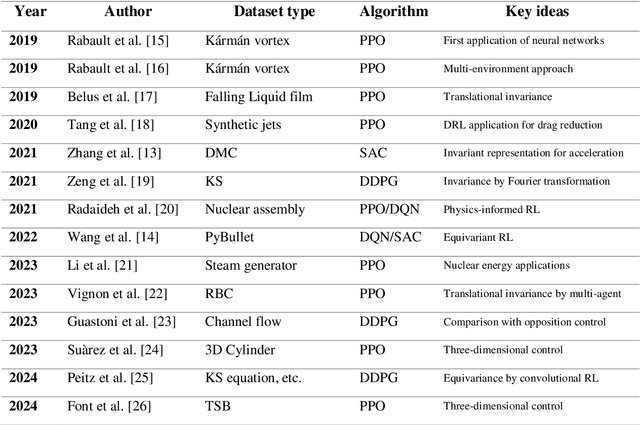
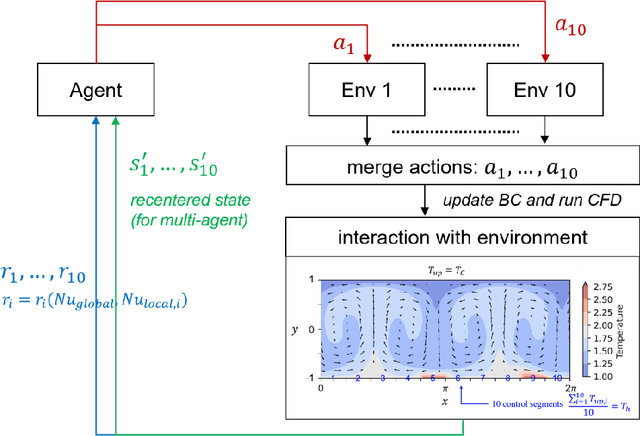
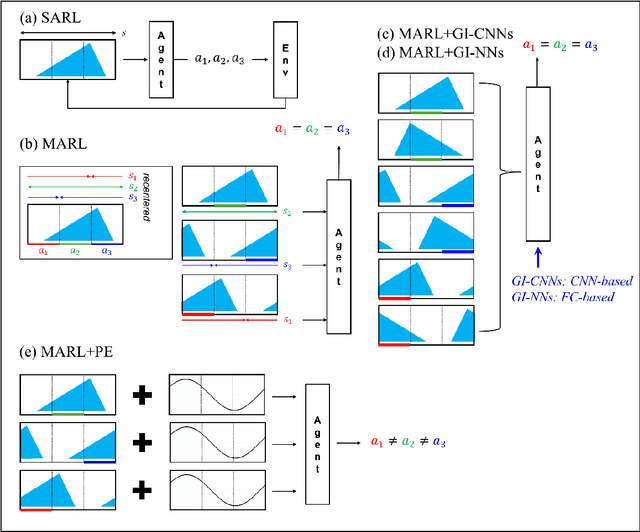
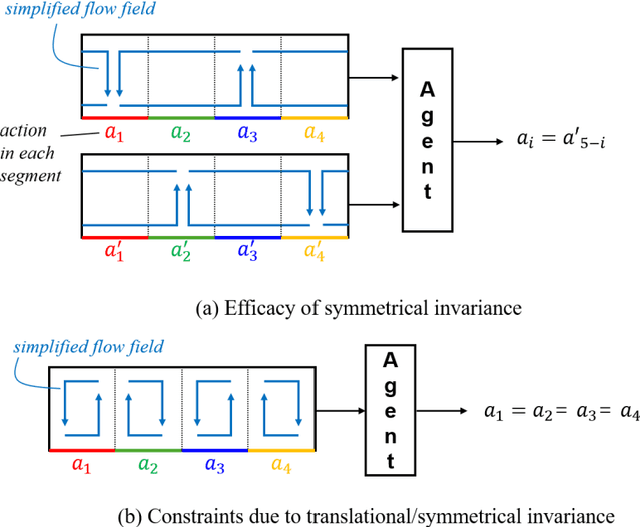
Flow control is key to maximize energy efficiency in a wide range of applications. However, traditional flow-control methods face significant challenges in addressing non-linear systems and high-dimensional data, limiting their application in realistic energy systems. This study advances deep-reinforcement-learning (DRL) methods for flow control, particularly focusing on integrating group-invariant networks and positional encoding into DRL architectures. Our methods leverage multi-agent reinforcement learning (MARL) to exploit policy invariance in space, in combination with group-invariant networks to ensure local symmetry invariance. Additionally, a positional encoding inspired by the transformer architecture is incorporated to provide location information to the agents, mitigating action constraints from strict invariance. The proposed methods are verified using a case study of Rayleigh-B\'enard convection, where the goal is to minimize the Nusselt number Nu. The group-invariant neural networks (GI-NNs) show faster convergence compared to the base MARL, achieving better average policy performance. The GI-NNs not only cut DRL training time in half but also notably enhance learning reproducibility. Positional encoding further enhances these results, effectively reducing the minimum Nu and stabilizing convergence. Interestingly, group invariant networks specialize in improving learning speed and positional encoding specializes in improving learning quality. These results demonstrate that choosing a suitable feature-representation method according to the purpose as well as the characteristics of each control problem is essential. We believe that the results of this study will not only inspire novel DRL methods with invariant and unique representations, but also provide useful insights for industrial applications.