 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Problems with Diffusion Models: A MAP Estimation Perspective
Jul 27, 2024



Inverse problems have many applications in science and engineering. In Computer vision, several image restoration tasks such as inpainting, deblurring, and super-resolution can be formally modeled as inverse problems. Recently, methods have been developed for solving inverse problems that only leverage a pre-trained unconditional diffusion model and do not require additional task-specific training. In such methods, however, the inherent intractability of determining the conditional score function during the reverse diffusion process poses a real challenge, leaving the methods to settle with an approximation instead, which affects their performance in practice. Here, we propose a MAP estimation framework to model the reverse conditional generation process of a continuous time diffusion model as an optimization process of the underlying MAP objective, whose gradient term is tractable. In theory, the proposed framework can be applied to solve general inverse problems using gradient-based optimization methods. However, given the highly non-convex nature of the loss objective, finding a perfect gradient-based optimization algorithm can be quite challenging, nevertheless, our framework offers several potential research directions. We use our proposed formulation and develop empirically effective algorithms for solving noiseless and noisy image inpainting tasks. We validate our proposed algorithms with extensive experiments across diverse mask settings.
Indirectly Parameterized Concrete Autoencoders
Mar 01, 2024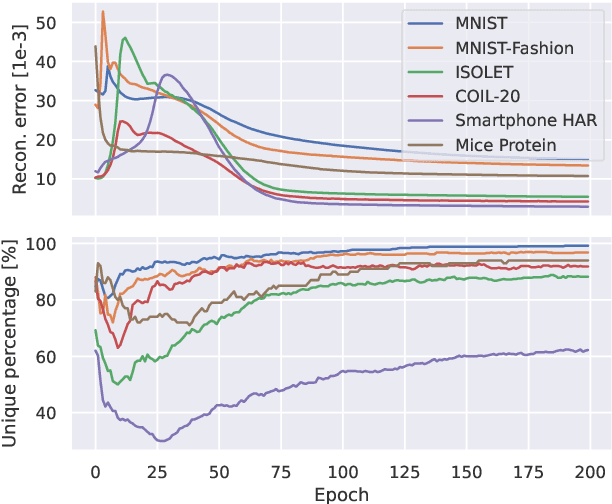
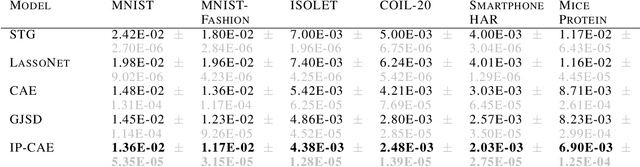
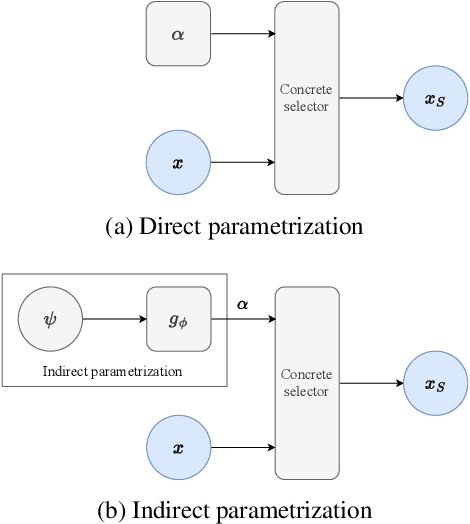

Feature selection is a crucial task in settings where data is high-dimensional or acquiring the full set of features is costly. Recent developments in neural network-based embedded feature selection show promising results across a wide range of applications. Concrete Autoencoders (CAEs), considered state-of-the-art in embedded feature selection, may struggle to achieve stable joint optimization, hurting their training time and generalization. In this work, we identify that this instability is correlated with the CAE learning duplicate selections. To remedy this, we propose a simple and effective improvement: Indirectly Parameterized CAEs (IP-CAEs). IP-CAEs learn an embedding and a mapping from it to the Gumbel-Softmax distributions' parameters. Despite being simple to implement, IP-CAE exhibits significant and consistent improvements over CAE in both generalization and training time across several datasets for reconstruction and classification. Unlike CAE, IP-CAE effectively leverages non-linear relationships and does not require retraining the jointly optimized decoder. Furthermore, our approach is, in principle, generalizable to Gumbel-Softmax distributions beyond feature selection.