 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndirectly Parameterized Concrete Autoencoders
Mar 01, 2024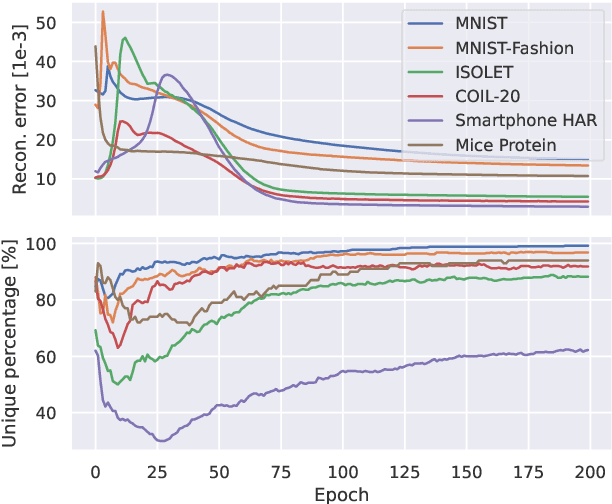
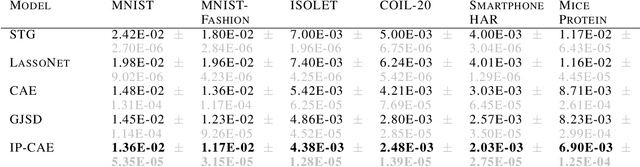
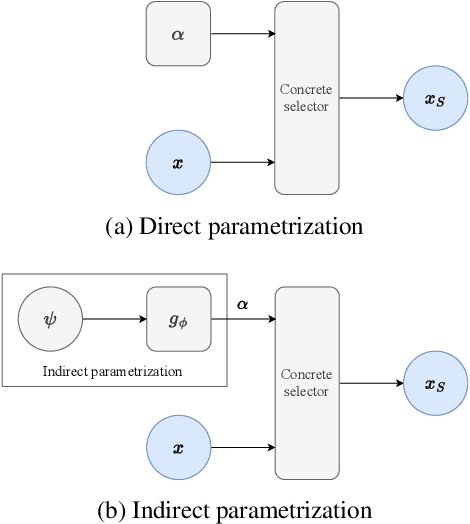

Feature selection is a crucial task in settings where data is high-dimensional or acquiring the full set of features is costly. Recent developments in neural network-based embedded feature selection show promising results across a wide range of applications. Concrete Autoencoders (CAEs), considered state-of-the-art in embedded feature selection, may struggle to achieve stable joint optimization, hurting their training time and generalization. In this work, we identify that this instability is correlated with the CAE learning duplicate selections. To remedy this, we propose a simple and effective improvement: Indirectly Parameterized CAEs (IP-CAEs). IP-CAEs learn an embedding and a mapping from it to the Gumbel-Softmax distributions' parameters. Despite being simple to implement, IP-CAE exhibits significant and consistent improvements over CAE in both generalization and training time across several datasets for reconstruction and classification. Unlike CAE, IP-CAE effectively leverages non-linear relationships and does not require retraining the jointly optimized decoder. Furthermore, our approach is, in principle, generalizable to Gumbel-Softmax distributions beyond feature selection.
Using Early-Learning Regularization to Classify Real-World Noisy Data
Jun 01, 2021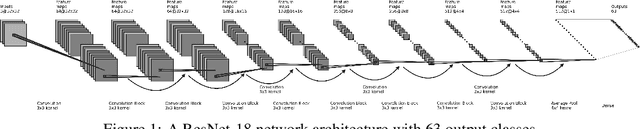
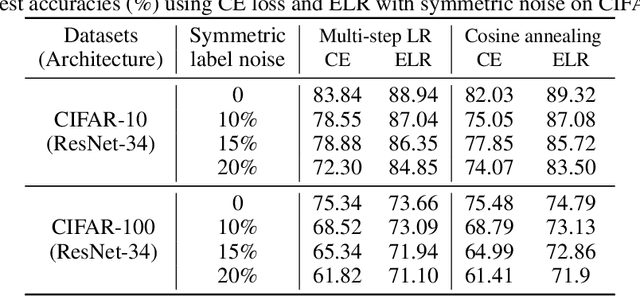
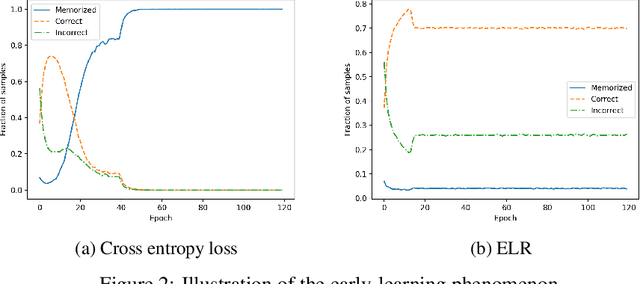

The memorization problem is well-known in the field of computer vision. Liu et al. propose a technique called Early-Learning Regularization, which improves accuracy on the CIFAR datasets when label noise is present. This project replicates their experiments and investigates the performance on a real-world dataset with intrinsic noise. Results show that their experimental results are consistent. We also explore Sharpness-Aware Minimization in addition to SGD and observed a further 14.6 percentage points improvement. Future work includes using all 6 million images and manually clean a fraction of the images to fine-tune a transfer learning model. Last but not the least, having access to clean data for testing would also improve the measurement of accuracy.