 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualising Policy-Reward Interplay to Inform Zeroth-Order Preference Optimisation of Large Language Models
Mar 05, 2025



Fine-tuning LLMs with first-order methods like back-propagation is computationally intensive. Zeroth-Order (ZO) optimisation, using function evaluations instead of gradients, reduces memory usage but suffers from slow convergence in high-dimensional models. As a result, ZO research in LLMs has mostly focused on classification, overlooking more complex generative tasks. In this paper, we introduce ZOPrO, a novel ZO algorithm designed for \textit{Preference Optimisation} in LLMs. We begin by analysing the interplay between policy and reward models during traditional (first-order) Preference Optimisation, uncovering patterns in their relative updates. Guided by these insights, we adapt Simultaneous Perturbation Stochastic Approximation (SPSA) with a targeted sampling strategy to accelerate convergence. Through experiments on summarisation, machine translation, and conversational assistants, we demonstrate that our method consistently enhances reward signals while achieving convergence times comparable to first-order methods. While it falls short of some state-of-the-art methods, our work is the first to apply Zeroth-Order methods to Preference Optimisation in LLMs, going beyond classification tasks and paving the way for a largely unexplored research direction. Code and visualisations are available at https://github.com/alessioGalatolo/VisZOPrO
DIEKAE: Difference Injection for Efficient Knowledge Augmentation and Editing of Large Language Models
Jun 15, 2024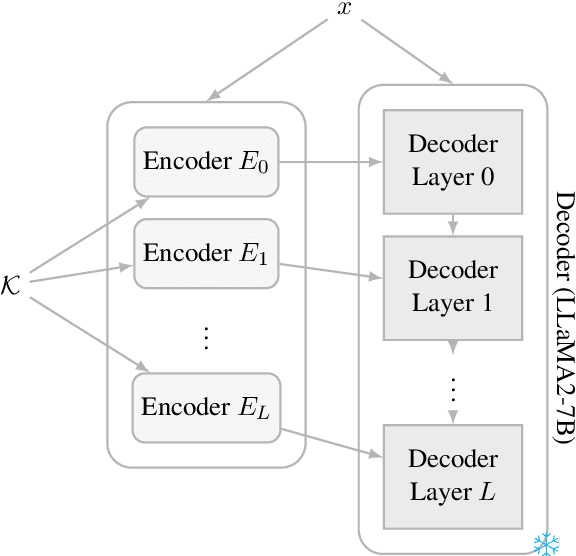



Pretrained Language Models (PLMs) store extensive knowledge within their weights, enabling them to recall vast amount of information. However, relying on this parametric knowledge brings some limitations such as outdated information or gaps in the training data. This work addresses these problems by distinguish between two separate solutions: knowledge editing and knowledge augmentation. We introduce Difference Injection for Efficient Knowledge Augmentation and Editing (DIEK\AE), a new method that decouples knowledge processing from the PLM (LLaMA2-7B, in particular) by adopting a series of encoders. These encoders handle external knowledge and inject it into the PLM layers, significantly reducing computational costs and improving performance of the PLM. We propose a novel training technique for these encoders that does not require back-propagation through the PLM, thus greatly reducing the memory and time required to train them. Our findings demonstrate how our method is faster and more efficient compared to multiple baselines in knowledge augmentation and editing during both training and inference. We have released our code and data at https://github.com/alessioGalatolo/DIEKAE.
Promoting Fairness and Diversity in Speech Datasets for Mental Health and Neurological Disorders Research
Jun 06, 2024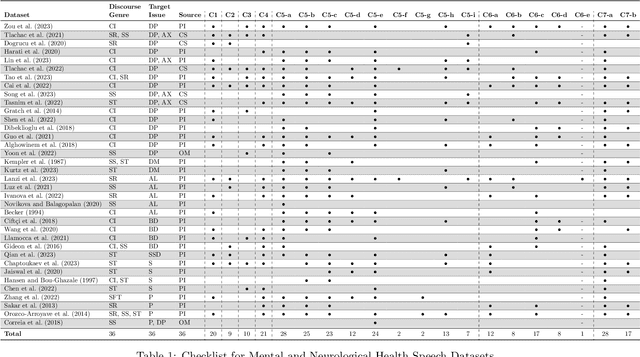
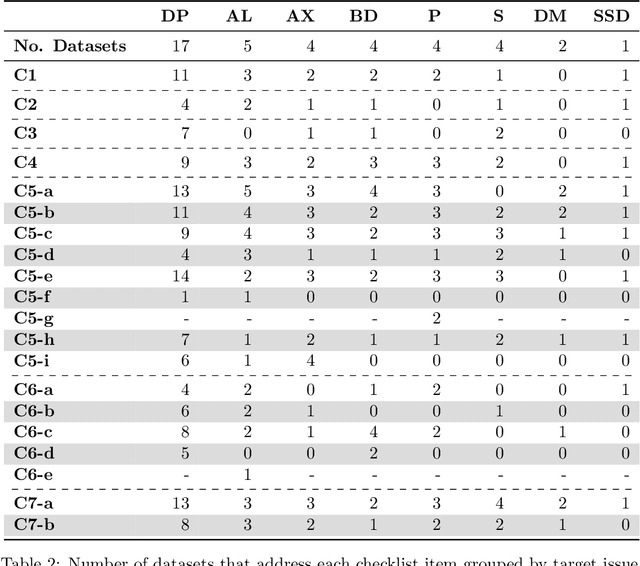
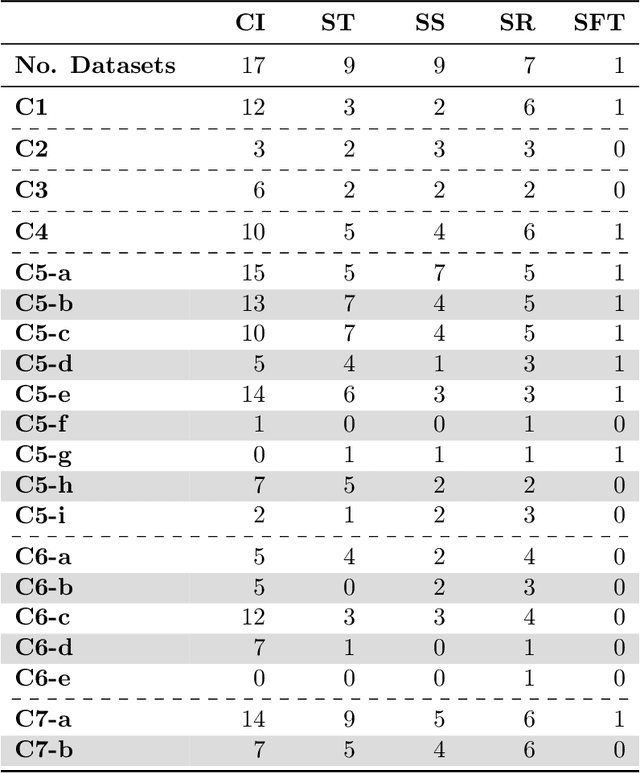
Current research in machine learning and artificial intelligence is largely centered on modeling and performance evaluation, less so on data collection. However, recent research demonstrated that limitations and biases in data may negatively impact trustworthiness and reliability. These aspects are particularly impactful on sensitive domains such as mental health and neurological disorders, where speech data are used to develop AI applications aimed at improving the health of patients and supporting healthcare providers. In this paper, we chart the landscape of available speech datasets for this domain, to highlight possible pitfalls and opportunities for improvement and promote fairness and diversity. We present a comprehensive list of desiderata for building speech datasets for mental health and neurological disorders and distill it into a checklist focused on ethical concerns to foster more responsible research.
Using Early-Learning Regularization to Classify Real-World Noisy Data
Jun 01, 2021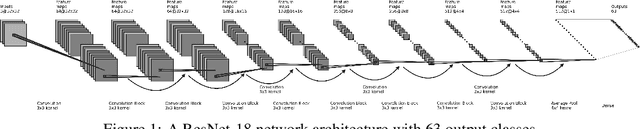
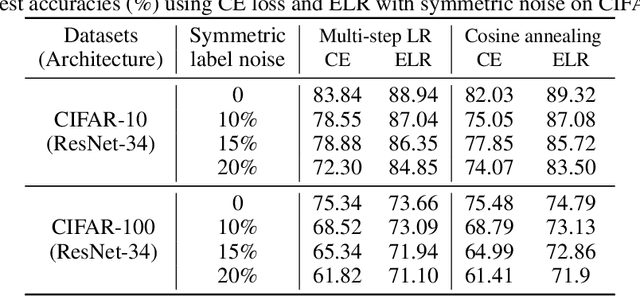
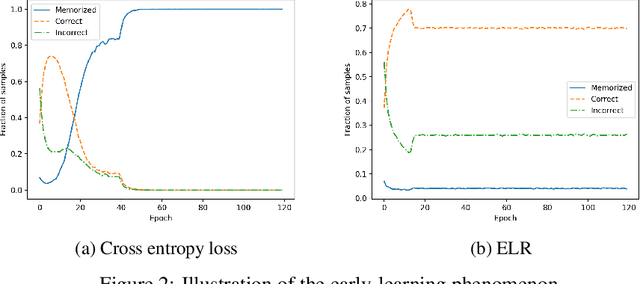

The memorization problem is well-known in the field of computer vision. Liu et al. propose a technique called Early-Learning Regularization, which improves accuracy on the CIFAR datasets when label noise is present. This project replicates their experiments and investigates the performance on a real-world dataset with intrinsic noise. Results show that their experimental results are consistent. We also explore Sharpness-Aware Minimization in addition to SGD and observed a further 14.6 percentage points improvement. Future work includes using all 6 million images and manually clean a fraction of the images to fine-tune a transfer learning model. Last but not the least, having access to clean data for testing would also improve the measurement of accuracy.