 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromoting Fairness and Diversity in Speech Datasets for Mental Health and Neurological Disorders Research
Paper and Code
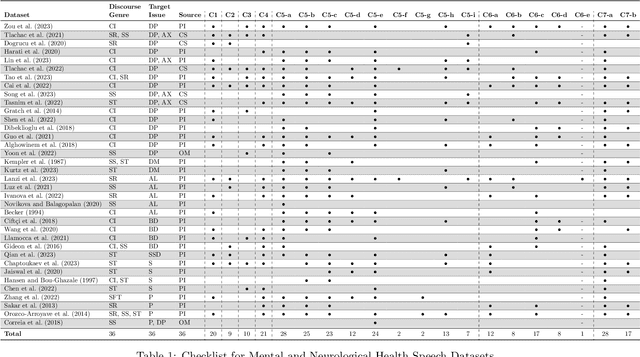
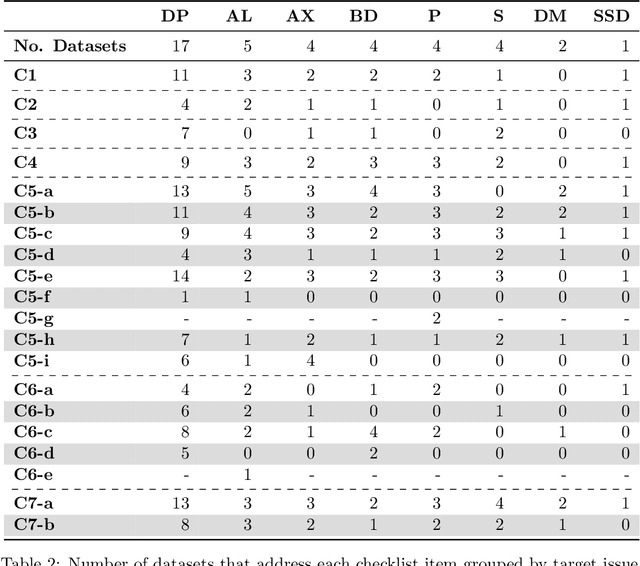
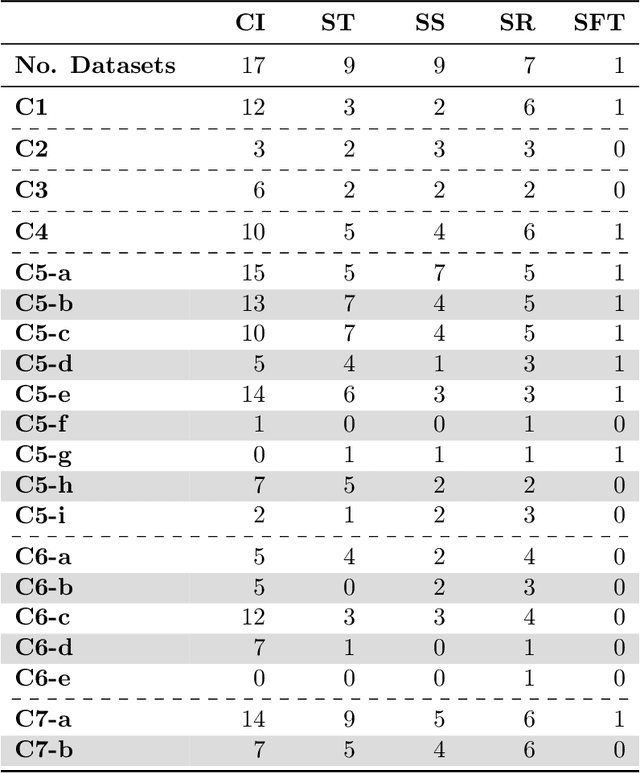
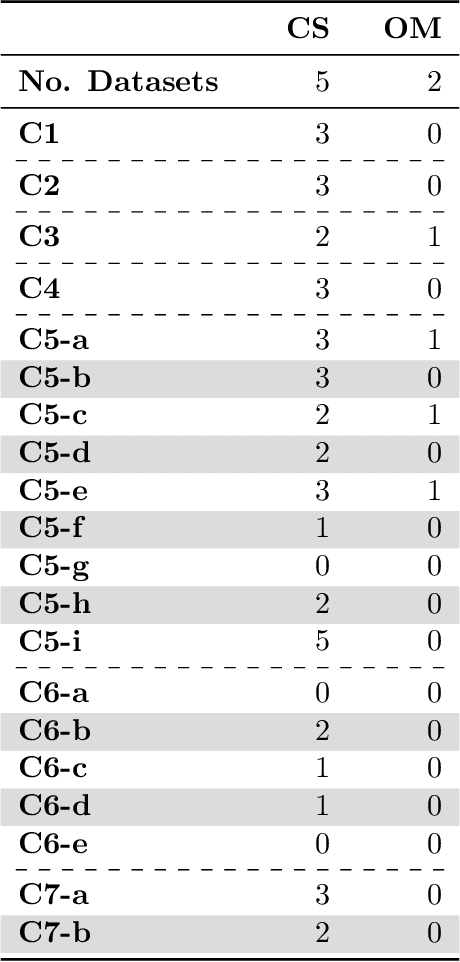
Current research in machine learning and artificial intelligence is largely centered on modeling and performance evaluation, less so on data collection. However, recent research demonstrated that limitations and biases in data may negatively impact trustworthiness and reliability. These aspects are particularly impactful on sensitive domains such as mental health and neurological disorders, where speech data are used to develop AI applications aimed at improving the health of patients and supporting healthcare providers. In this paper, we chart the landscape of available speech datasets for this domain, to highlight possible pitfalls and opportunities for improvement and promote fairness and diversity. We present a comprehensive list of desiderata for building speech datasets for mental health and neurological disorders and distill it into a checklist focused on ethical concerns to foster more responsible research.