 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Early-Learning Regularization to Classify Real-World Noisy Data
Jun 01, 2021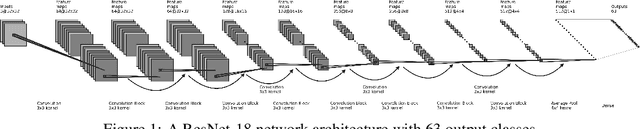
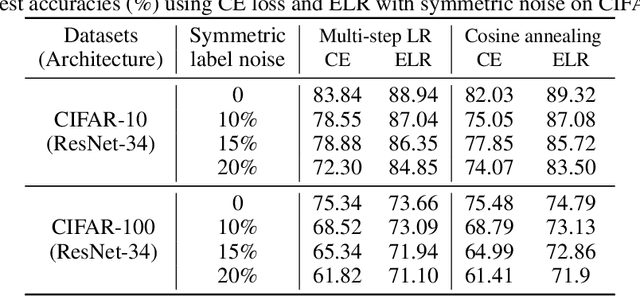
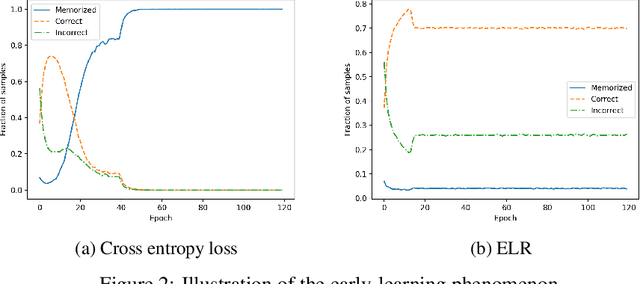

The memorization problem is well-known in the field of computer vision. Liu et al. propose a technique called Early-Learning Regularization, which improves accuracy on the CIFAR datasets when label noise is present. This project replicates their experiments and investigates the performance on a real-world dataset with intrinsic noise. Results show that their experimental results are consistent. We also explore Sharpness-Aware Minimization in addition to SGD and observed a further 14.6 percentage points improvement. Future work includes using all 6 million images and manually clean a fraction of the images to fine-tune a transfer learning model. Last but not the least, having access to clean data for testing would also improve the measurement of accuracy.
Using Twitter Attribute Information to Predict Stock Prices
May 04, 2021
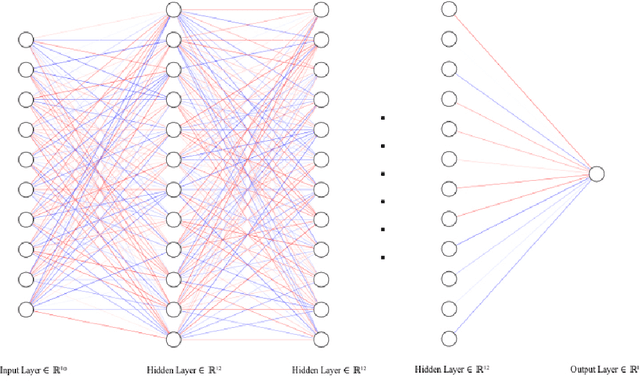
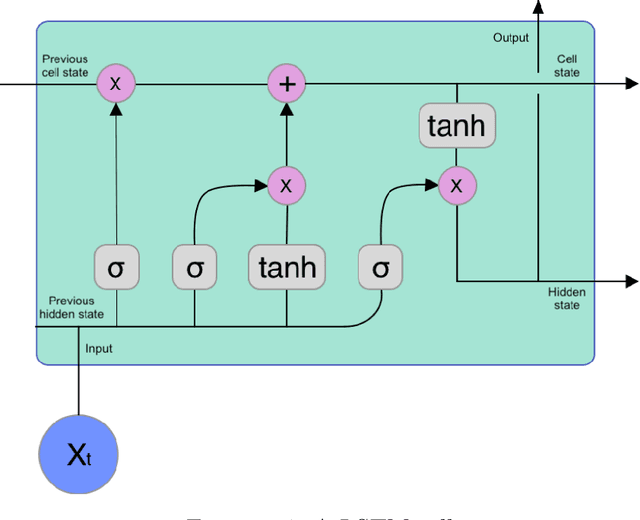
Being able to predict stock prices might be the unspoken wish of stock investors. Although stock prices are complicated to predict, there are many theories about what affects their movements, including interest rates, news and social media. With the help of Machine Learning, complex patterns in data can be identified beyond the human intellect. In this thesis, a Machine Learning model for time series forecasting is created and tested to predict stock prices. The model is based on a neural network with several layers of LSTM and fully connected layers. It is trained with historical stock values, technical indicators and Twitter attribute information retrieved, extracted and calculated from posts on the social media platform Twitter. These attributes are sentiment score, favourites, followers, retweets and if an account is verified. To collect data from Twitter, Twitter's API is used. Sentiment analysis is conducted with VADER. The results show that by adding more Twitter attributes, the MSE between the predicted prices and the actual prices improved by 3%. With technical analysis taken into account, MSE decreases from 0.1617 to 0.1437, which is an improvement of around 11%. The restrictions of this study include that the selected stock has to be publicly listed on the stock market and popular on Twitter and among individual investors. Besides, the stock markets' opening hours differ from Twitter, which constantly available. It may therefore introduce noises in the model.