 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIEKAE: Difference Injection for Efficient Knowledge Augmentation and Editing of Large Language Models
Paper and Code
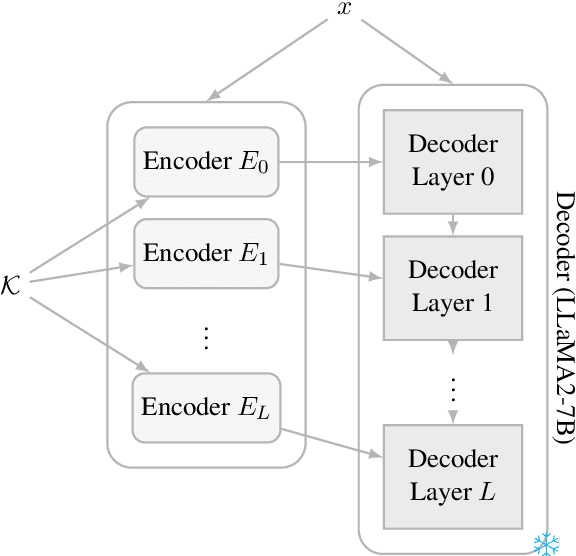



Pretrained Language Models (PLMs) store extensive knowledge within their weights, enabling them to recall vast amount of information. However, relying on this parametric knowledge brings some limitations such as outdated information or gaps in the training data. This work addresses these problems by distinguish between two separate solutions: knowledge editing and knowledge augmentation. We introduce Difference Injection for Efficient Knowledge Augmentation and Editing (DIEK\AE), a new method that decouples knowledge processing from the PLM (LLaMA2-7B, in particular) by adopting a series of encoders. These encoders handle external knowledge and inject it into the PLM layers, significantly reducing computational costs and improving performance of the PLM. We propose a novel training technique for these encoders that does not require back-propagation through the PLM, thus greatly reducing the memory and time required to train them. Our findings demonstrate how our method is faster and more efficient compared to multiple baselines in knowledge augmentation and editing during both training and inference. We have released our code and data at https://github.com/alessioGalatolo/DIEKAE.