 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLN-Pilot: Large Vision-Language Model as an Autonomous Indoor Drone Operator
Feb 05, 2026This paper introduces VLN-Pilot, a novel framework in which a large Vision-and-Language Model (VLLM) assumes the role of a human pilot for indoor drone navigation. By leveraging the multimodal reasoning abilities of VLLMs, VLN-Pilot interprets free-form natural language instructions and grounds them in visual observations to plan and execute drone trajectories in GPS-denied indoor environments. Unlike traditional rule-based or geometric path-planning approaches, our framework integrates language-driven semantic understanding with visual perception, enabling context-aware, high-level flight behaviors with minimal task-specific engineering. VLN-Pilot supports fully autonomous instruction-following for drones by reasoning about spatial relationships, obstacle avoidance, and dynamic reactivity to unforeseen events. We validate our framework on a custom photorealistic indoor simulation benchmark and demonstrate the ability of the VLLM-driven agent to achieve high success rates on complex instruction-following tasks, including long-horizon navigation with multiple semantic targets. Experimental results highlight the promise of replacing remote drone pilots with a language-guided autonomous agent, opening avenues for scalable, human-friendly control of indoor UAVs in tasks such as inspection, search-and-rescue, and facility monitoring. Our results suggest that VLLM-based pilots may dramatically reduce operator workload while improving safety and mission flexibility in constrained indoor environments.
An Artificial Intelligence-based Assistant for the Visually Impaired
Nov 11, 2025

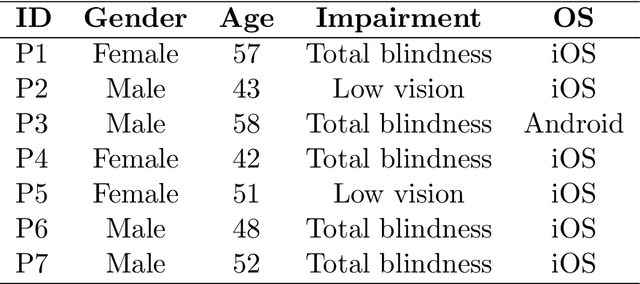

This paper describes an artificial intelligence-based assistant application, AIDEN, developed during 2023 and 2024, aimed at improving the quality of life for visually impaired individuals. Visually impaired individuals face challenges in identifying objects, reading text, and navigating unfamiliar environments, which can limit their independence and reduce their quality of life. Although solutions such as Braille, audio books, and screen readers exist, they may not be effective in all situations. This application leverages state-of-the-art machine learning algorithms to identify and describe objects, read text, and answer questions about the environment. Specifically, it uses You Only Look Once architectures and a Large Language and Vision Assistant. The system incorporates several methods to facilitate the user's interaction with the system and access to textual and visual information in an appropriate manner. AIDEN aims to enhance user autonomy and access to information, contributing to an improved perception of daily usability, as supported by user feedback.
CADDI: An in-Class Activity Detection Dataset using IMU data from low-cost sensors
Mar 04, 2025The monitoring and prediction of in-class student activities is of paramount importance for the comprehension of engagement and the enhancement of pedagogical efficacy. The accurate detection of these activities enables educators to modify their lessons in real time, thereby reducing negative emotional states and enhancing the overall learning experience. To this end, the use of non-intrusive devices, such as inertial measurement units (IMUs) embedded in smartwatches, represents a viable solution. The development of reliable predictive systems has been limited by the lack of large, labeled datasets in education. To bridge this gap, we present a novel dataset for in-class activity detection using affordable IMU sensors. The dataset comprises 19 diverse activities, both instantaneous and continuous, performed by 12 participants in typical classroom scenarios. It includes accelerometer, gyroscope, rotation vector data, and synchronized stereo images, offering a comprehensive resource for developing multimodal algorithms using sensor and visual data. This dataset represents a key step toward scalable solutions for activity recognition in educational settings.
CHIRLA: Comprehensive High-resolution Identification and Re-identification for Large-scale Analysis
Feb 10, 2025Person re-identification (Re-ID) is a key challenge in computer vision, requiring the matching of individuals across different cameras, locations, and time periods. While most research focuses on short-term scenarios with minimal appearance changes, real-world applications demand robust Re-ID systems capable of handling long-term scenarios, where persons' appearances can change significantly due to variations in clothing and physical characteristics. In this paper, we present CHIRLA, Comprehensive High-resolution Identification and Re-identification for Large-scale Analysis, a novel dataset specifically designed for long-term person Re-ID. CHIRLA consists of recordings from strategically placed cameras over a seven-month period, capturing significant variations in both temporal and appearance attributes, including controlled changes in participants' clothing and physical features. The dataset includes 22 individuals, four connected indoor environments, and seven cameras. We collected more than five hours of video that we semi-automatically labeled to generate around one million bounding boxes with identity annotations. By introducing this comprehensive benchmark, we aim to facilitate the development and evaluation of Re-ID algorithms that can reliably perform in challenging, long-term real-world scenarios.
Attentional-GCNN: Adaptive Pedestrian Trajectory Prediction towards Generic Autonomous Vehicle Use Cases
Nov 23, 2020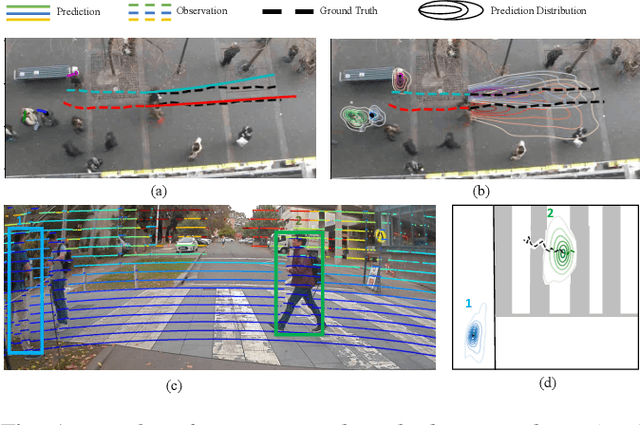
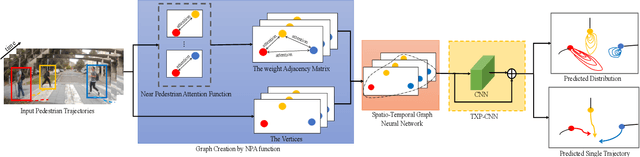
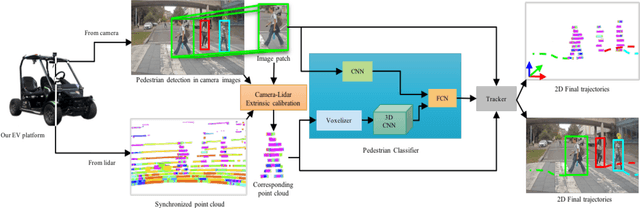

Autonomous vehicle navigation in shared pedestrian environments requires the ability to predict future crowd motion both accurately and with minimal delay. Understanding the uncertainty of the prediction is also crucial. Most existing approaches however can only estimate uncertainty through repeated sampling of generative models. Additionally, most current predictive models are trained on datasets that assume complete observability of the crowd using an aerial view. These are generally not representative of real-world usage from a vehicle perspective, and can lead to the underestimation of uncertainty bounds when the on-board sensors are occluded. Inspired by prior work in motion prediction using spatio-temporal graphs, we propose a novel Graph Convolutional Neural Network (GCNN)-based approach, Attentional-GCNN, which aggregates information of implicit interaction between pedestrians in a crowd by assigning attention weight in edges of the graph. Our model can be trained to either output a probabilistic distribution or faster deterministic prediction, demonstrating applicability to autonomous vehicle use cases where either speed or accuracy with uncertainty bounds are required. To further improve the training of predictive models, we propose an automatically labelled pedestrian dataset collected from an intelligent vehicle platform representative of real-world use. Through experiments on a number of datasets, we show our proposed method achieves an improvement over the state of art by 10% Average Displacement Error (ADE) and 12% Final Displacement Error (FDE) with fast inference speeds.
Large-scale Multiview 3D Hand Pose Dataset
Jul 18, 2017
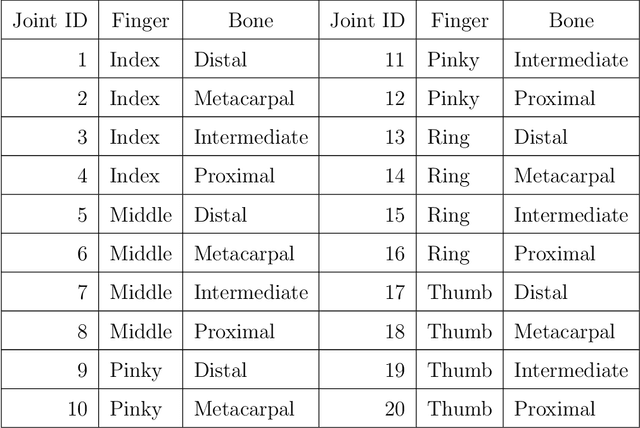


Accurate hand pose estimation at joint level has several uses on human-robot interaction, user interfacing and virtual reality applications. Yet, it currently is not a solved problem. The novel deep learning techniques could make a great improvement on this matter but they need a huge amount of annotated data. The hand pose datasets released so far present some issues that make them impossible to use on deep learning methods such as the few number of samples, high-level abstraction annotations or samples consisting in depth maps. In this work, we introduce a multiview hand pose dataset in which we provide color images of hands and different kind of annotations for each, i.e the bounding box and the 2D and 3D location on the joints in the hand. Besides, we introduce a simple yet accurate deep learning architecture for real-time robust 2D hand pose estimation.