 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Visual, Qualitative and Quantitative Dataset of Web Pages
May 15, 2021


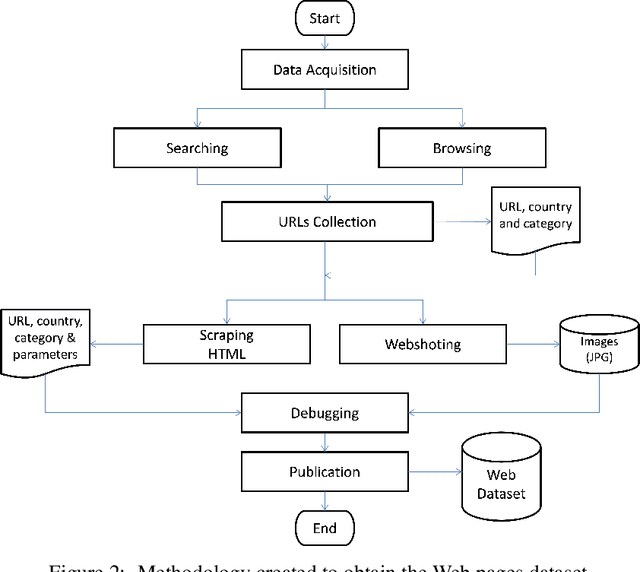
The World Wide Web is not only one of the most important platforms of communication and information at present, but also an area of growing interest for scientific research. This motivates a lot of work and projects that require large amounts of data. However, there is no dataset that integrates the parameters and visual appearance of Web pages, because its collection is a costly task in terms of time and effort. With the support of various computer tools and programming scripts, we have created a large dataset of 49,438 Web pages. It consists of visual, textual and numerical data types, includes all countries worldwide, and considers a broad range of topics such as art, entertainment, economy, business, education, government, news, media, science, and environment, covering different cultural characteristics and varied design preferences. In this paper, we describe the process of collecting, debugging and publishing the final product, which is freely available. To demonstrate the usefulness of our dataset, we expose a binary classification model for detecting error Web pages, and a multi-class Web subject-based categorization, both problems using convolutional neural networks.