 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fairness Assessment of Dutch Hate Speech Detection
Jun 14, 2025Numerous studies have proposed computational methods to detect hate speech online, yet most focus on the English language and emphasize model development. In this study, we evaluate the counterfactual fairness of hate speech detection models in the Dutch language, specifically examining the performance and fairness of transformer-based models. We make the following key contributions. First, we curate a list of Dutch Social Group Terms that reflect social context. Second, we generate counterfactual data for Dutch hate speech using LLMs and established strategies like Manual Group Substitution (MGS) and Sentence Log-Likelihood (SLL). Through qualitative evaluation, we highlight the challenges of generating realistic counterfactuals, particularly with Dutch grammar and contextual coherence. Third, we fine-tune baseline transformer-based models with counterfactual data and evaluate their performance in detecting hate speech. Fourth, we assess the fairness of these models using Counterfactual Token Fairness (CTF) and group fairness metrics, including equality of odds and demographic parity. Our analysis shows that models perform better in terms of hate speech detection, average counterfactual fairness and group fairness. This work addresses a significant gap in the literature on counterfactual fairness for hate speech detection in Dutch and provides practical insights and recommendations for improving both model performance and fairness.
Towards High-Fidelity Synthetic Multi-platform Social Media Datasets via Large Language Models
May 02, 2025Social media datasets are essential for research on a variety of topics, such as disinformation, influence operations, hate speech detection, or influencer marketing practices. However, access to social media datasets is often constrained due to costs and platform restrictions. Acquiring datasets that span multiple platforms, which is crucial for understanding the digital ecosystem, is particularly challenging. This paper explores the potential of large language models to create lexically and semantically relevant social media datasets across multiple platforms, aiming to match the quality of real data. We propose multi-platform topic-based prompting and employ various language models to generate synthetic data from two real datasets, each consisting of posts from three different social media platforms. We assess the lexical and semantic properties of the synthetic data and compare them with those of the real data. Our empirical findings show that using large language models to generate synthetic multi-platform social media data is promising, different language models perform differently in terms of fidelity, and a post-processing approach might be needed for generating high-fidelity synthetic datasets for research. In addition to the empirical evaluation of three state of the art large language models, our contributions include new fidelity metrics specific to multi-platform social media datasets.
The Monetisation of Toxicity: Analysing YouTube Content Creators and Controversy-Driven Engagement
Aug 01, 2024
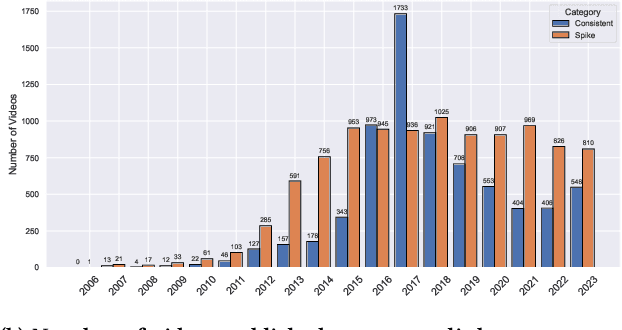
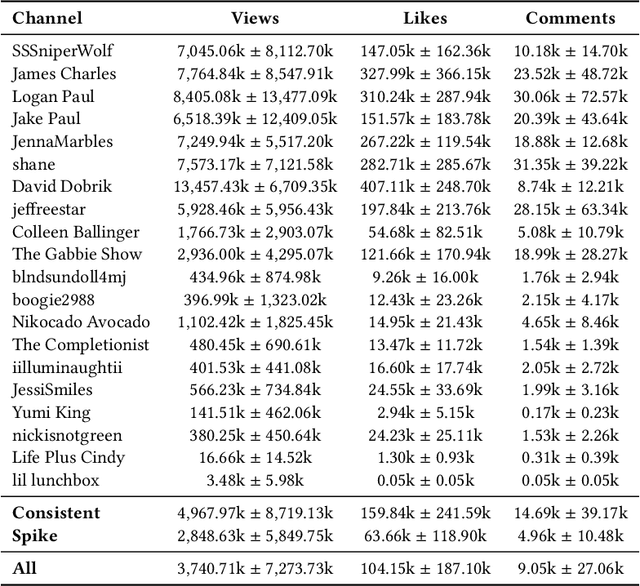
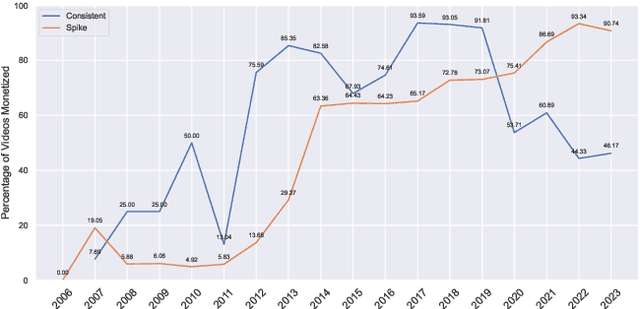
YouTube is a major social media platform that plays a significant role in digital culture, with content creators at its core. These creators often engage in controversial behaviour to drive engagement, which can foster toxicity. This paper presents a quantitative analysis of controversial content on YouTube, focusing on the relationship between controversy, toxicity, and monetisation. We introduce a curated dataset comprising 20 controversial YouTube channels extracted from Reddit discussions, including 16,349 videos and more than 105 million comments. We identify and categorise monetisation cues from video descriptions into various models, including affiliate marketing and direct selling, using lists of URLs and keywords. Additionally, we train a machine learning model to measure the toxicity of comments in these videos. Our findings reveal that while toxic comments correlate with higher engagement, they negatively impact monetisation, indicating that controversy-driven interaction does not necessarily lead to financial gain. We also observed significant variation in monetisation strategies, with some creators showing extensive monetisation despite high toxicity levels. Our study introduces a curated dataset, lists of URLs and keywords to categorise monetisation, a machine learning model to measure toxicity, and is a significant step towards understanding the complex relationship between controversy, engagement, and monetisation on YouTube. The lists used for detecting and categorising monetisation cues are available on https://github.com/thalesbertaglia/toxmon.
InstaSynth: Opportunities and Challenges in Generating Synthetic Instagram Data with ChatGPT for Sponsored Content Detection
Mar 22, 2024Large Language Models (LLMs) raise concerns about lowering the cost of generating texts that could be used for unethical or illegal purposes, especially on social media. This paper investigates the promise of such models to help enforce legal requirements related to the disclosure of sponsored content online. We investigate the use of LLMs for generating synthetic Instagram captions with two objectives: The first objective (fidelity) is to produce realistic synthetic datasets. For this, we implement content-level and network-level metrics to assess whether synthetic captions are realistic. The second objective (utility) is to create synthetic data that is useful for sponsored content detection. For this, we evaluate the effectiveness of the generated synthetic data for training classifiers to identify undisclosed advertisements on Instagram. Our investigations show that the objectives of fidelity and utility may conflict and that prompt engineering is a useful but insufficient strategy. Additionally, we find that while individual synthetic posts may appear realistic, collectively they lack diversity, topic connectivity, and realistic user interaction patterns.
Closing the Loop: Testing ChatGPT to Generate Model Explanations to Improve Human Labelling of Sponsored Content on Social Media
Jun 08, 2023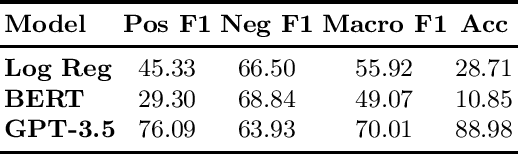
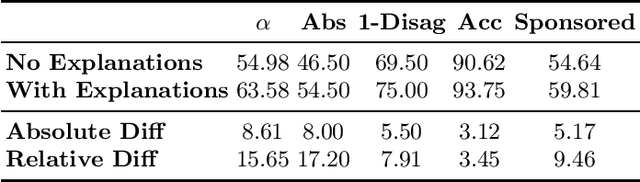
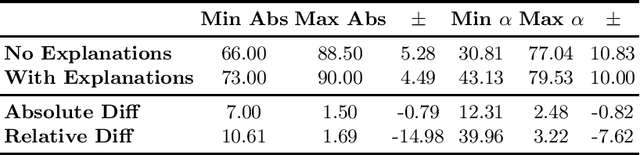
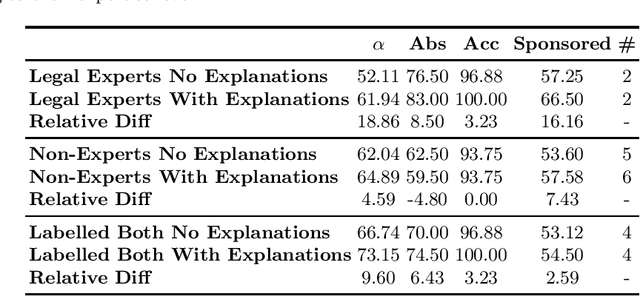
Regulatory bodies worldwide are intensifying their efforts to ensure transparency in influencer marketing on social media through instruments like the Unfair Commercial Practices Directive (UCPD) in the European Union, or Section 5 of the Federal Trade Commission Act. Yet enforcing these obligations has proven to be highly problematic due to the sheer scale of the influencer market. The task of automatically detecting sponsored content aims to enable the monitoring and enforcement of such regulations at scale. Current research in this field primarily frames this problem as a machine learning task, focusing on developing models that achieve high classification performance in detecting ads. These machine learning tasks rely on human data annotation to provide ground truth information. However, agreement between annotators is often low, leading to inconsistent labels that hinder the reliability of models. To improve annotation accuracy and, thus, the detection of sponsored content, we propose using chatGPT to augment the annotation process with phrases identified as relevant features and brief explanations. Our experiments show that this approach consistently improves inter-annotator agreement and annotation accuracy. Additionally, our survey of user experience in the annotation task indicates that the explanations improve the annotators' confidence and streamline the process. Our proposed methods can ultimately lead to more transparency and alignment with regulatory requirements in sponsored content detection.
The Case for a Legal Compliance API for the Enforcement of the EU's Digital Services Act on Social Media Platforms
May 13, 2022In the course of under a year, the European Commission has launched some of the most important regulatory proposals to date on platform governance. The Commission's goals behind cross-sectoral regulation of this sort include the protection of markets and democracies alike. While all these acts propose sophisticated rules for setting up new enforcement institutions and procedures, one aspect remains highly unclear: how digital enforcement will actually take place in practice. Focusing on the Digital Services Act (DSA), this discussion paper critically addresses issues around social media data access for the purpose of digital enforcement and proposes the use of a legal compliance application programming interface (API) as a means to facilitate compliance with the DSA and complementary European and national regulation. To contextualize this discussion, the paper pursues two scenarios that exemplify the harms arising out of content monetization affecting a particularly vulnerable category of social media users: children. The two scenarios are used to further reflect upon essential issues surrounding data access and legal compliance with the DSA and further applicable legal standards in the field of labour and consumer law.
Social-Media Activity Forecasting with Exogenous Information Signals
Sep 22, 2021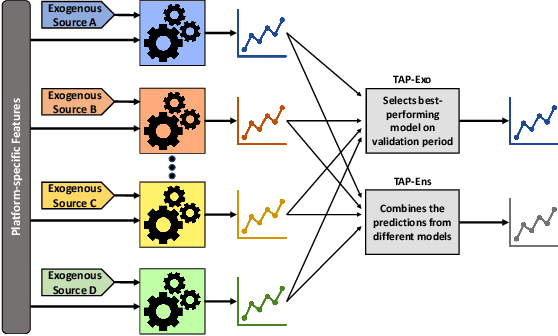
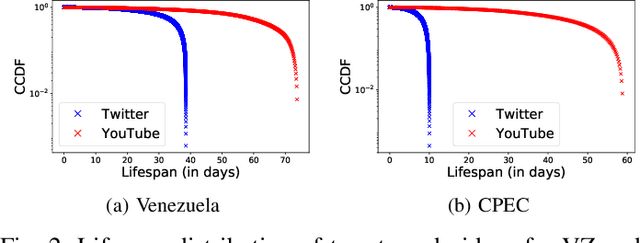
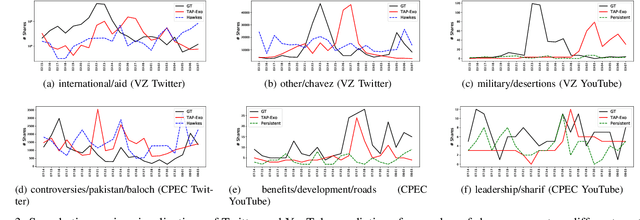

Due to their widespread adoption, social media platforms present an ideal environment for studying and understanding social behavior, especially on information spread. Modeling social media activity has numerous practical implications such as supporting efforts to analyze strategic information operations, designing intervention techniques to mitigate disinformation, or delivering critical information during disaster relief operations. In this paper we propose a modeling technique that forecasts topic-specific daily volume of social media activities by using both exogenous signals, such as news or armed conflicts records, and endogenous data from the social media platform we model. Empirical evaluations with real datasets from two different platforms and two different contexts each composed of multiple interrelated topics demonstrate the effectiveness of our solution.
Cascade-LSTM: Predicting Information Cascades using Deep Neural Networks
Apr 26, 2020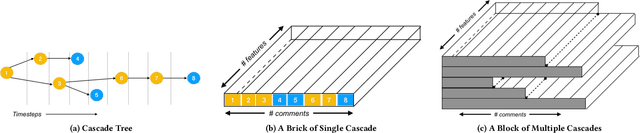
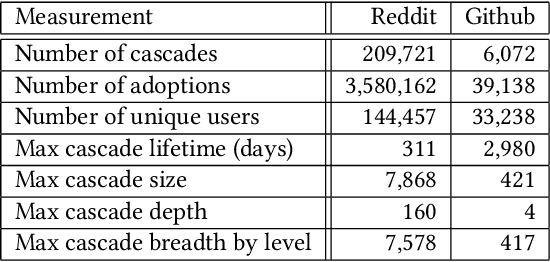
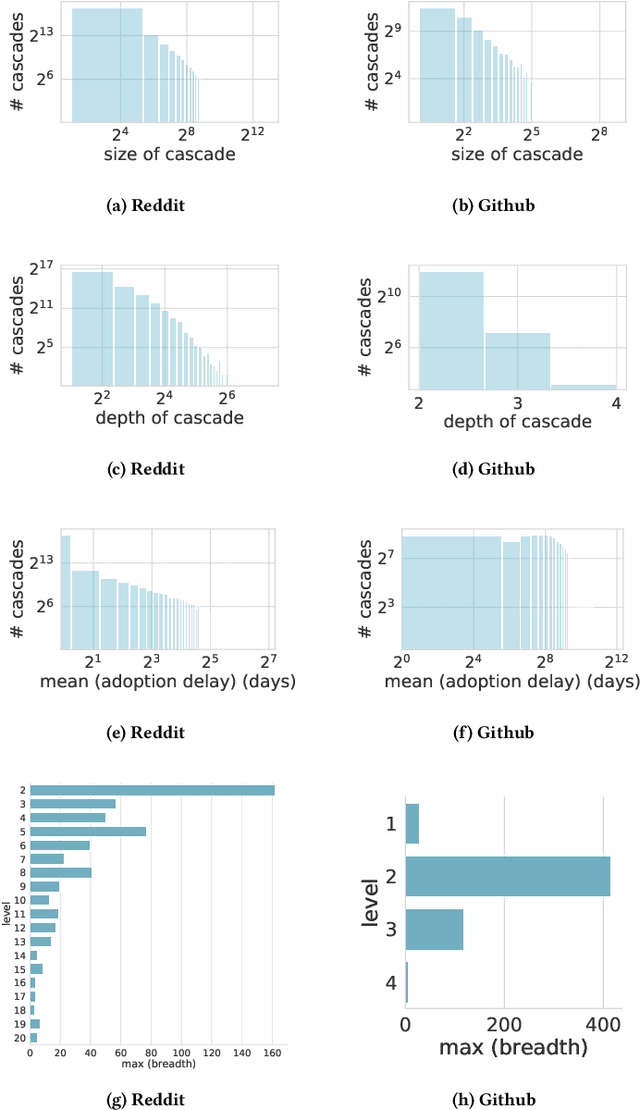
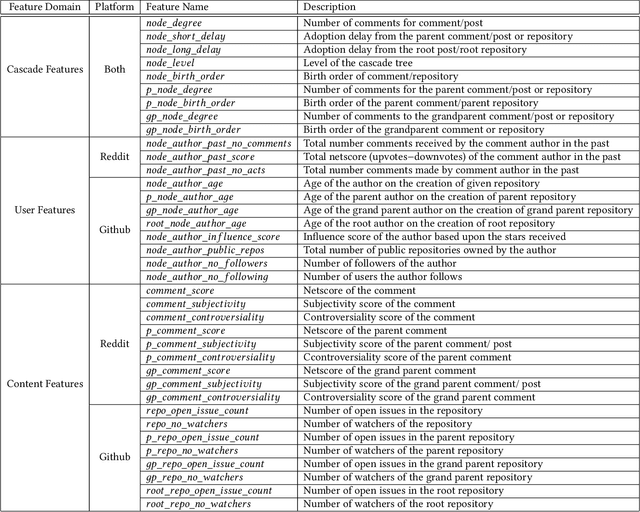
Predicting the flow of information in dynamic social environments is relevant to many areas of the contemporary society, from disseminating health care messages to meme tracking. While predicting the growth of information cascades has been successfully addressed in diverse social platforms, predicting the temporal and topological structure of information cascades has seen limited exploration. However, accurately predicting how many users will transmit the message of a particular user and at what time is paramount for designing practical intervention techniques. This paper leverages Long-Short Term Memory (LSTM) neural network techniques to predict two spatio-temporal properties of information cascades, namely the size and speed of individual-level information transmissions. We combine these prediction algorithms with probabilistic generation of cascade trees into a generative test model that is able to accurately generate cascade trees in two different platforms, Reddit and Github. Our approach leads to a classification accuracy of over 73% for information transmitters and 83% for early transmitters in a variety of social platforms.
Data Survivability in Networks of Mobile Robots in Urban Disaster Environments
Feb 22, 2013
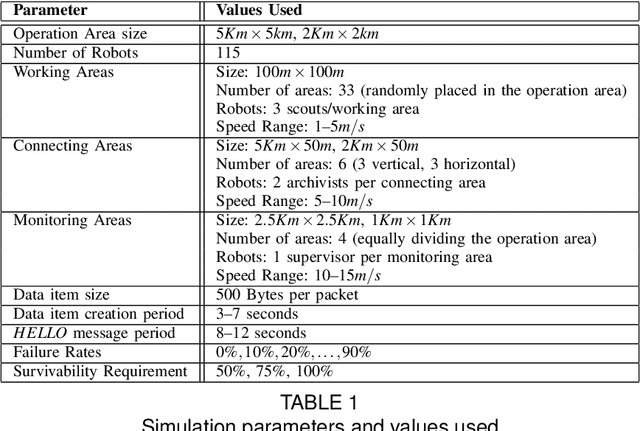
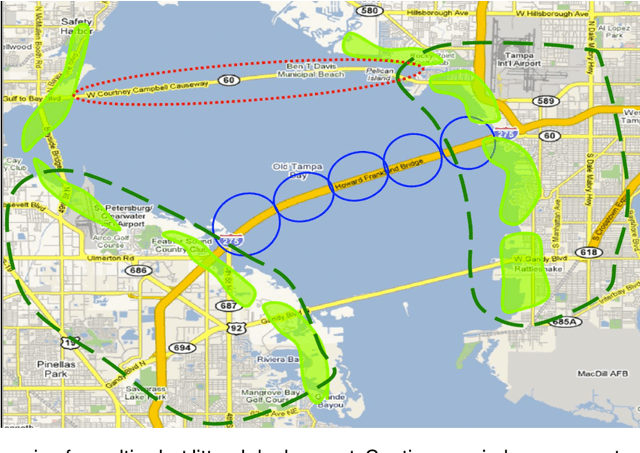
Mobile multi-robot teams deployed for monitoring or search-and-rescue missions in urban disaster areas can greatly improve the quality of vital data collected on-site. Analysis of such data can identify hazards and save lives. Unfortunately, such real deployments at scale are cost prohibitive and robot failures lead to data loss. Moreover, scaled-down deployments do not capture significant levels of interaction and communication complexity. To tackle this problem, we propose novel mobility and failure generation frameworks that allow realistic simulations of mobile robot networks for large scale disaster scenarios. Furthermore, since data replication techniques can improve the survivability of data collected during the operation, we propose an adaptive, scalable data replication technique that achieves high data survivability with low overhead. Our technique considers the anticipated robot failures and robot heterogeneity to decide how aggressively to replicate data. In addition, it considers survivability priorities, with some data requiring more effort to be saved than others. Using our novel simulation generation frameworks, we compare our adaptive technique with flooding and broadcast-based replication techniques and show that for failure rates of up to 60% it ensures better data survivability with lower communication costs.