 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceable by Design: An LLM Pipeline and Dashboard for EU Regulatory Consultation Analysis
May 29, 2026Public consultations generate large volumes of data in the form of stakeholder submissions that are practically unfeasible to analyse manually. We present an end-to-end LLM-based pipeline and interactive dashboard for structured topic extraction from regulatory consultation submissions, demonstrated on the European Commission's Digital Fairness Act (DFA) public call for evidence as a case study. The system processes raw PDF attachments and web-form responses, extracts topic annotations, and grounds every extraction in a verbatim quote from the source text. Applied to 4,322 DFA submissions, the pipeline produced 15,368 topic annotations supported by 20,951 verbatim evidence quotes. Three principles govern the proposed design: verbatim grounding, full traceability, and transparency by design. The dashboard exposes the full extraction dataset through five analytical views, from dataset-level topic overviews to individual paragraph drill-downs, with every result traceable to its source. Beyond the predefined DFA topic categories, the pipeline generated certain stakeholder concerns, such as Age Verification, Payment Processor Censorship, and Digital Ownership, that a fixed-taxonomy approach would have missed. The pipeline is domain-generic; adapting it to a new consultation requires only a prompt update and a new dataset. A live demo is available at https://dfa-dashboard.thalesbertaglia.com/. The code and processed data are publicly available at https://github.com/thalesbertaglia/dfa-dashboard.
LinGO: A Linguistic Graph Optimization Framework with LLMs for Interpreting Intents of Online Uncivil Discourse
Feb 04, 2026Detecting uncivil language is crucial for maintaining safe, inclusive, and democratic online spaces. Yet existing classifiers often misinterpret posts containing uncivil cues but expressing civil intents, leading to inflated estimates of harmful incivility online. We introduce LinGO, a linguistic graph optimization framework for large language models (LLMs) that leverages linguistic structures and optimization techniques to classify multi-class intents of incivility that use various direct and indirect expressions. LinGO decomposes language into multi-step linguistic components, identifies targeted steps that cause the most errors, and iteratively optimizes prompt and/or example components for targeted steps. We evaluate it using a dataset collected during the 2022 Brazilian presidential election, encompassing four forms of political incivility: Impoliteness (IMP), Hate Speech and Stereotyping (HSST), Physical Harm and Violent Political Rhetoric (PHAVPR), and Threats to Democratic Institutions and Values (THREAT). Each instance is annotated with six types of civil/uncivil intent. We benchmark LinGO using three cost-efficient LLMs: GPT-5-mini, Gemini 2.5 Flash-Lite, and Claude 3 Haiku, and four optimization techniques: TextGrad, AdalFlow, DSPy, and Retrieval-Augmented Generation (RAG). The results show that, across all models, LinGO consistently improves accuracy and weighted F1 compared with zero-shot, chain-of-thought, direct optimization, and fine-tuning baselines. RAG is the strongest optimization technique and, when paired with Gemini model, achieves the best overall performance. These findings demonstrate that incorporating multi-step linguistic components into LLM instructions and optimize targeted components can help the models explain complex semantic meanings, which can be extended to other complex semantic explanation tasks in the future.
Computational Studies in Influencer Marketing: A Systematic Literature Review
Jun 17, 2025Influencer marketing has become a crucial feature of digital marketing strategies. Despite its rapid growth and algorithmic relevance, the field of computational studies in influencer marketing remains fragmented, especially with limited systematic reviews covering the computational methodologies employed. This makes overarching scientific measurements in the influencer economy very scarce, to the detriment of interested stakeholders outside of platforms themselves, such as regulators, but also researchers from other fields. This paper aims to provide an overview of the state of the art of computational studies in influencer marketing by conducting a systematic literature review (SLR) based on the PRISMA model. The paper analyses 69 studies to identify key research themes, methodologies, and future directions in this research field. The review identifies four major research themes: Influencer identification and characterisation, Advertising strategies and engagement, Sponsored content analysis and discovery, and Fairness. Methodologically, the studies are categorised into machine learning-based techniques (e.g., classification, clustering) and non-machine-learning-based techniques (e.g., statistical analysis, network analysis). Key findings reveal a strong focus on optimising commercial outcomes, with limited attention to regulatory compliance and ethical considerations. The review highlights the need for more nuanced computational research that incorporates contextual factors such as language, platform, and industry type, as well as improved model explainability and dataset reproducibility. The paper concludes by proposing a multidisciplinary research agenda that emphasises the need for further links to regulation and compliance technology, finer granularity in analysis, and the development of standardised datasets.
Towards Fairness Assessment of Dutch Hate Speech Detection
Jun 14, 2025Numerous studies have proposed computational methods to detect hate speech online, yet most focus on the English language and emphasize model development. In this study, we evaluate the counterfactual fairness of hate speech detection models in the Dutch language, specifically examining the performance and fairness of transformer-based models. We make the following key contributions. First, we curate a list of Dutch Social Group Terms that reflect social context. Second, we generate counterfactual data for Dutch hate speech using LLMs and established strategies like Manual Group Substitution (MGS) and Sentence Log-Likelihood (SLL). Through qualitative evaluation, we highlight the challenges of generating realistic counterfactuals, particularly with Dutch grammar and contextual coherence. Third, we fine-tune baseline transformer-based models with counterfactual data and evaluate their performance in detecting hate speech. Fourth, we assess the fairness of these models using Counterfactual Token Fairness (CTF) and group fairness metrics, including equality of odds and demographic parity. Our analysis shows that models perform better in terms of hate speech detection, average counterfactual fairness and group fairness. This work addresses a significant gap in the literature on counterfactual fairness for hate speech detection in Dutch and provides practical insights and recommendations for improving both model performance and fairness.
TikTok Search Recommendations: Governance and Research Challenges
May 13, 2025Like other social media, TikTok is embracing its use as a search engine, developing search products to steer users to produce searchable content and engage in content discovery. Their recently developed product search recommendations are preformulated search queries recommended to users on videos. However, TikTok provides limited transparency about how search recommendations are generated and moderated, despite requirements under regulatory frameworks like the European Union's Digital Services Act. By suggesting that the platform simply aggregates comments and common searches linked to videos, it sidesteps responsibility and issues that arise from contextually problematic recommendations, reigniting long-standing concerns about platform liability and moderation. This position paper addresses the novelty of search recommendations on TikTok by highlighting the challenges that this feature poses for platform governance and offering a computational research agenda, drawing on preliminary qualitative analysis. It sets out the need for transparency in platform documentation, data access and research to study search recommendations.
Towards High-Fidelity Synthetic Multi-platform Social Media Datasets via Large Language Models
May 02, 2025Social media datasets are essential for research on a variety of topics, such as disinformation, influence operations, hate speech detection, or influencer marketing practices. However, access to social media datasets is often constrained due to costs and platform restrictions. Acquiring datasets that span multiple platforms, which is crucial for understanding the digital ecosystem, is particularly challenging. This paper explores the potential of large language models to create lexically and semantically relevant social media datasets across multiple platforms, aiming to match the quality of real data. We propose multi-platform topic-based prompting and employ various language models to generate synthetic data from two real datasets, each consisting of posts from three different social media platforms. We assess the lexical and semantic properties of the synthetic data and compare them with those of the real data. Our empirical findings show that using large language models to generate synthetic multi-platform social media data is promising, different language models perform differently in terms of fidelity, and a post-processing approach might be needed for generating high-fidelity synthetic datasets for research. In addition to the empirical evaluation of three state of the art large language models, our contributions include new fidelity metrics specific to multi-platform social media datasets.
The Monetisation of Toxicity: Analysing YouTube Content Creators and Controversy-Driven Engagement
Aug 01, 2024
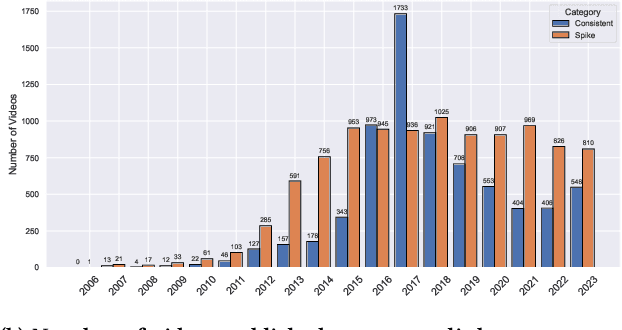
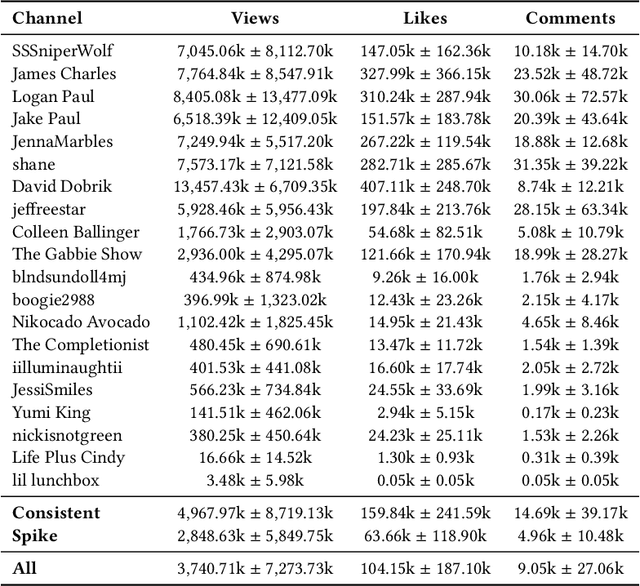
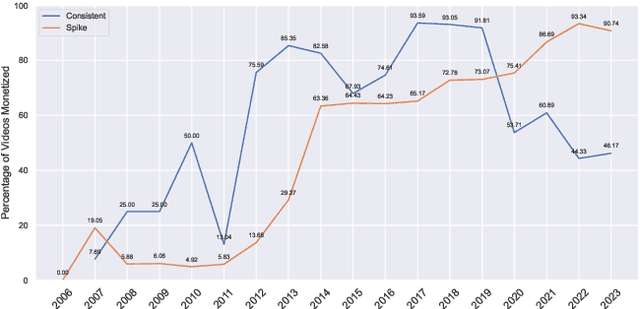
YouTube is a major social media platform that plays a significant role in digital culture, with content creators at its core. These creators often engage in controversial behaviour to drive engagement, which can foster toxicity. This paper presents a quantitative analysis of controversial content on YouTube, focusing on the relationship between controversy, toxicity, and monetisation. We introduce a curated dataset comprising 20 controversial YouTube channels extracted from Reddit discussions, including 16,349 videos and more than 105 million comments. We identify and categorise monetisation cues from video descriptions into various models, including affiliate marketing and direct selling, using lists of URLs and keywords. Additionally, we train a machine learning model to measure the toxicity of comments in these videos. Our findings reveal that while toxic comments correlate with higher engagement, they negatively impact monetisation, indicating that controversy-driven interaction does not necessarily lead to financial gain. We also observed significant variation in monetisation strategies, with some creators showing extensive monetisation despite high toxicity levels. Our study introduces a curated dataset, lists of URLs and keywords to categorise monetisation, a machine learning model to measure toxicity, and is a significant step towards understanding the complex relationship between controversy, engagement, and monetisation on YouTube. The lists used for detecting and categorising monetisation cues are available on https://github.com/thalesbertaglia/toxmon.
Across Platforms and Languages: Dutch Influencers and Legal Disclosures on Instagram, YouTube and TikTok
Jul 17, 2024

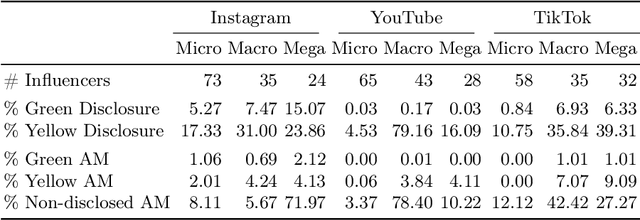
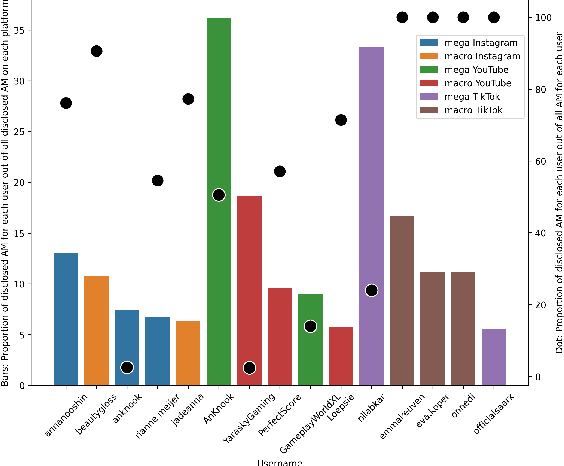
Content monetization on social media fuels a growing influencer economy. Influencer marketing remains largely undisclosed or inappropriately disclosed on social media. Non-disclosure issues have become a priority for national and supranational authorities worldwide, who are starting to impose increasingly harsher sanctions on them. This paper proposes a transparent methodology for measuring whether and how influencers comply with disclosures based on legal standards. We introduce a novel distinction between disclosures that are legally sufficient (green) and legally insufficient (yellow). We apply this methodology to an original dataset reflecting the content of 150 Dutch influencers publicly registered with the Dutch Media Authority based on recently introduced registration obligations. The dataset consists of 292,315 posts and is multi-language (English and Dutch) and cross-platform (Instagram, YouTube and TikTok). We find that influencer marketing remains generally underdisclosed on social media, and that bigger influencers are not necessarily more compliant with disclosure standards.
InstaSynth: Opportunities and Challenges in Generating Synthetic Instagram Data with ChatGPT for Sponsored Content Detection
Mar 22, 2024Large Language Models (LLMs) raise concerns about lowering the cost of generating texts that could be used for unethical or illegal purposes, especially on social media. This paper investigates the promise of such models to help enforce legal requirements related to the disclosure of sponsored content online. We investigate the use of LLMs for generating synthetic Instagram captions with two objectives: The first objective (fidelity) is to produce realistic synthetic datasets. For this, we implement content-level and network-level metrics to assess whether synthetic captions are realistic. The second objective (utility) is to create synthetic data that is useful for sponsored content detection. For this, we evaluate the effectiveness of the generated synthetic data for training classifiers to identify undisclosed advertisements on Instagram. Our investigations show that the objectives of fidelity and utility may conflict and that prompt engineering is a useful but insufficient strategy. Additionally, we find that while individual synthetic posts may appear realistic, collectively they lack diversity, topic connectivity, and realistic user interaction patterns.
Closing the Loop: Testing ChatGPT to Generate Model Explanations to Improve Human Labelling of Sponsored Content on Social Media
Jun 08, 2023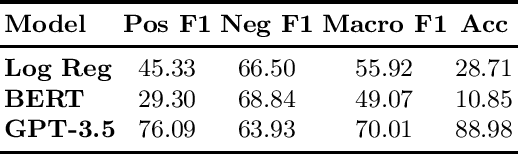
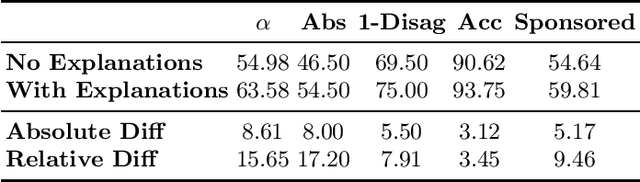
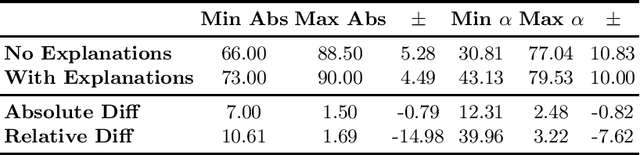
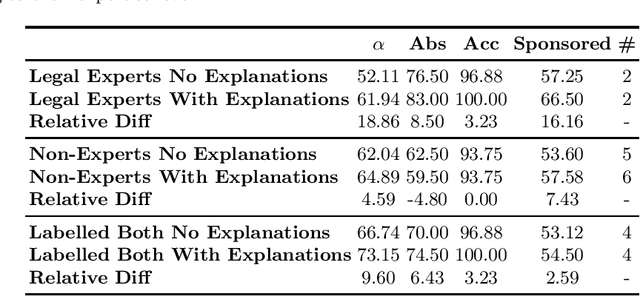
Regulatory bodies worldwide are intensifying their efforts to ensure transparency in influencer marketing on social media through instruments like the Unfair Commercial Practices Directive (UCPD) in the European Union, or Section 5 of the Federal Trade Commission Act. Yet enforcing these obligations has proven to be highly problematic due to the sheer scale of the influencer market. The task of automatically detecting sponsored content aims to enable the monitoring and enforcement of such regulations at scale. Current research in this field primarily frames this problem as a machine learning task, focusing on developing models that achieve high classification performance in detecting ads. These machine learning tasks rely on human data annotation to provide ground truth information. However, agreement between annotators is often low, leading to inconsistent labels that hinder the reliability of models. To improve annotation accuracy and, thus, the detection of sponsored content, we propose using chatGPT to augment the annotation process with phrases identified as relevant features and brief explanations. Our experiments show that this approach consistently improves inter-annotator agreement and annotation accuracy. Additionally, our survey of user experience in the annotation task indicates that the explanations improve the annotators' confidence and streamline the process. Our proposed methods can ultimately lead to more transparency and alignment with regulatory requirements in sponsored content detection.