 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecPCM: A Low-power PCM-based In-Memory Computing Accelerator for Full-stack Mass Spectrometry Analysis
Nov 14, 2024



Mass spectrometry (MS) is essential for proteomics and metabolomics but faces impending challenges in efficiently processing the vast volumes of data. This paper introduces SpecPCM, an in-memory computing (IMC) accelerator designed to achieve substantial improvements in energy and delay efficiency for both MS spectral clustering and database (DB) search. SpecPCM employs analog processing with low-voltage swing and utilizes recently introduced phase change memory (PCM) devices based on superlattice materials, optimized for low-voltage and low-power programming. Our approach integrates contributions across multiple levels: application, algorithm, circuit, device, and instruction sets. We leverage a robust hyperdimensional computing (HD) algorithm with a novel dimension-packing method and develop specialized hardware for the end-to-end MS pipeline to overcome the non-ideal behavior of PCM devices. We further optimize multi-level PCM devices for different tasks by using different materials. We also perform a comprehensive design exploration to improve energy and delay efficiency while maintaining accuracy, exploring various combinations of hardware and software parameters controlled by the instruction set architecture (ISA). SpecPCM, with up to three bits per cell, achieves speedups of up to 82x and 143x for MS clustering and DB search tasks, respectively, along with a four-orders-of-magnitude improvement in energy efficiency compared with state-of-the-art CPU/GPU tools.
An Analog and Digital Hybrid Attention Accelerator for Transformers with Charge-based In-memory Computing
Sep 08, 2024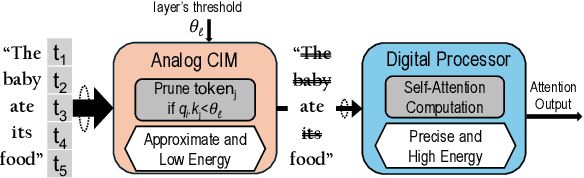
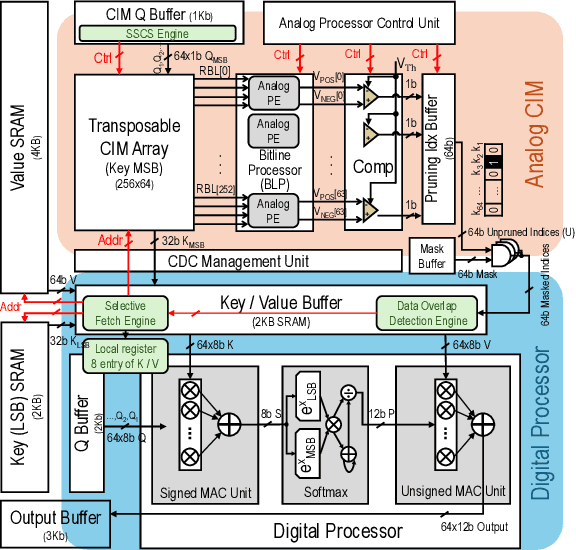
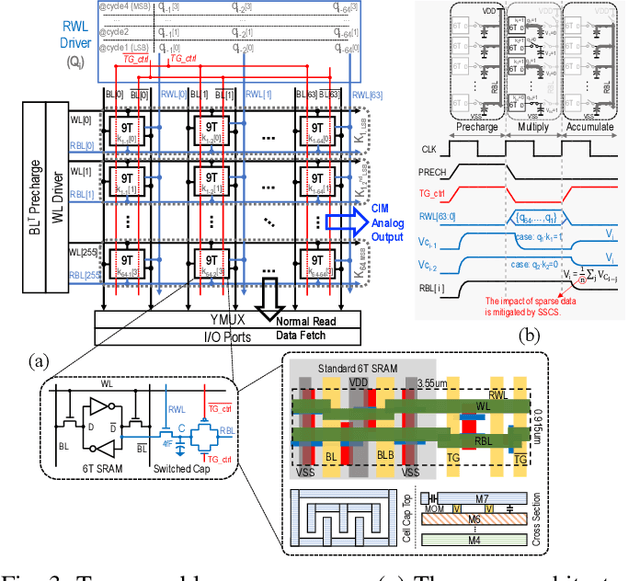
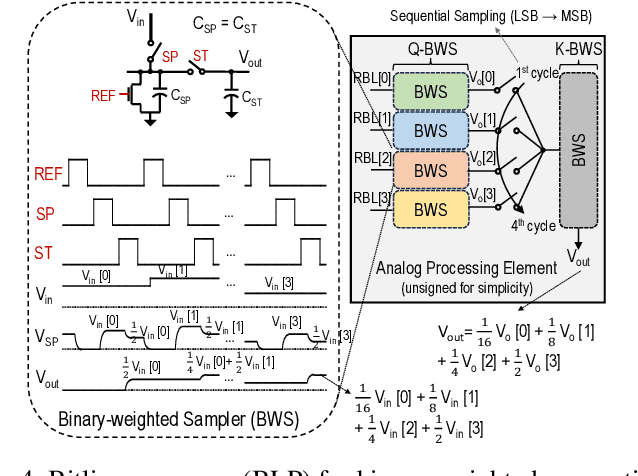
The attention mechanism is a key computing kernel of Transformers, calculating pairwise correlations across the entire input sequence. The computing complexity and frequent memory access in computing self-attention put a huge burden on the system especially when the sequence length increases. This paper presents an analog and digital hybrid processor to accelerate the attention mechanism for transformers in 65nm CMOS technology. We propose an analog computing-in-memory (CIM) core, which prunes ~75% of low-score tokens on average during runtime at ultra-low power and delay. Additionally, a digital processor performs precise computations only for ~25% unpruned tokens selected by the analog CIM core, preventing accuracy degradation. Measured results show peak energy efficiency of 14.8 and 1.65 TOPS/W, and peak area efficiency of 976.6 and 79.4 GOPS/mm$^\mathrm{2}$ in the analog core and the system-on-chip (SoC), respectively.
Sparse Attention Acceleration with Synergistic In-Memory Pruning and On-Chip Recomputation
Sep 01, 2022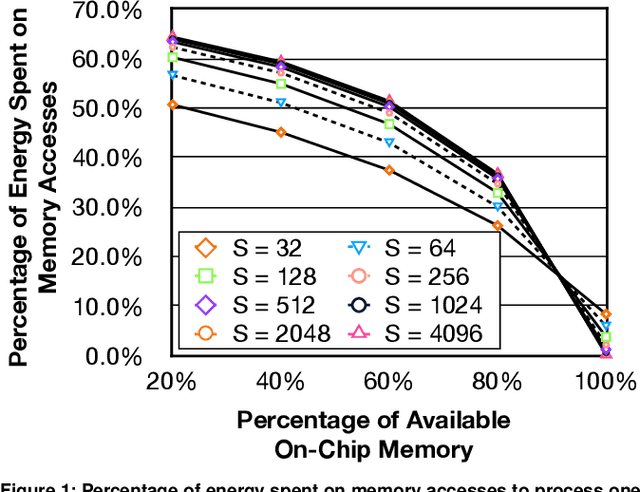
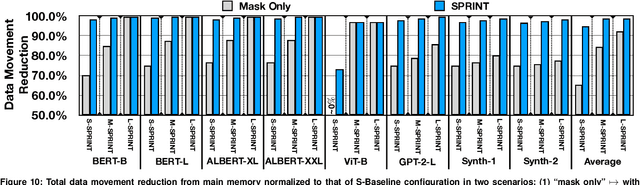
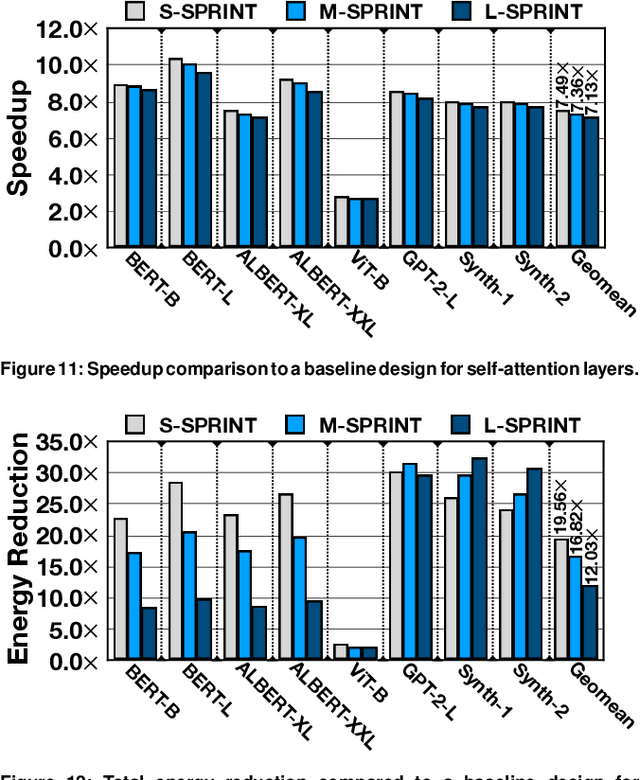
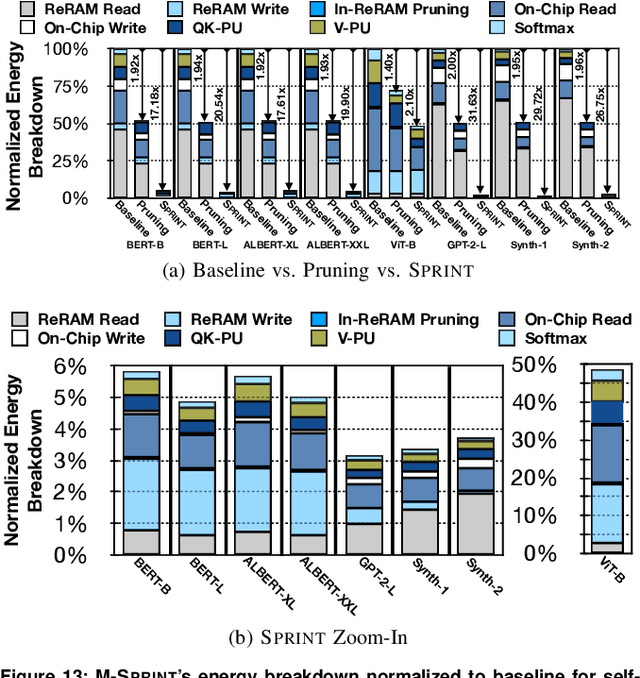
As its core computation, a self-attention mechanism gauges pairwise correlations across the entire input sequence. Despite favorable performance, calculating pairwise correlations is prohibitively costly. While recent work has shown the benefits of runtime pruning of elements with low attention scores, the quadratic complexity of self-attention mechanisms and their on-chip memory capacity demands are overlooked. This work addresses these constraints by architecting an accelerator, called SPRINT, which leverages the inherent parallelism of ReRAM crossbar arrays to compute attention scores in an approximate manner. Our design prunes the low attention scores using a lightweight analog thresholding circuitry within ReRAM, enabling SPRINT to fetch only a small subset of relevant data to on-chip memory. To mitigate potential negative repercussions for model accuracy, SPRINT re-computes the attention scores for the few fetched data in digital. The combined in-memory pruning and on-chip recompute of the relevant attention scores enables SPRINT to transform quadratic complexity to a merely linear one. In addition, we identify and leverage a dynamic spatial locality between the adjacent attention operations even after pruning, which eliminates costly yet redundant data fetches. We evaluate our proposed technique on a wide range of state-of-the-art transformer models. On average, SPRINT yields 7.5x speedup and 19.6x energy reduction when total 16KB on-chip memory is used, while virtually on par with iso-accuracy of the baseline models (on average 0.36% degradation).