 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHD-Bind: Encoding of Molecular Structure with Low Precision, Hyperdimensional Binary Representations
Mar 27, 2023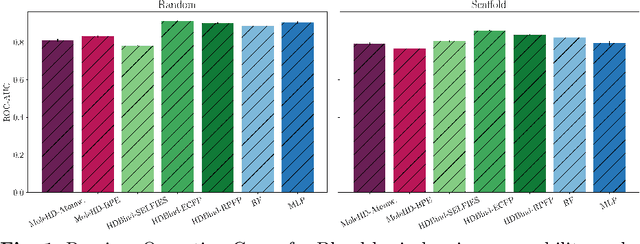
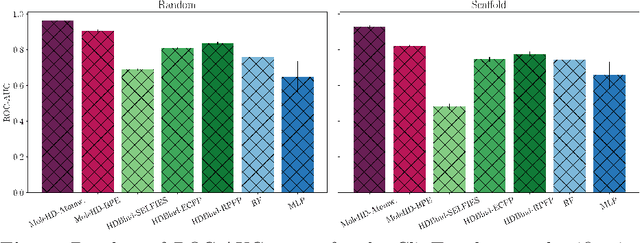
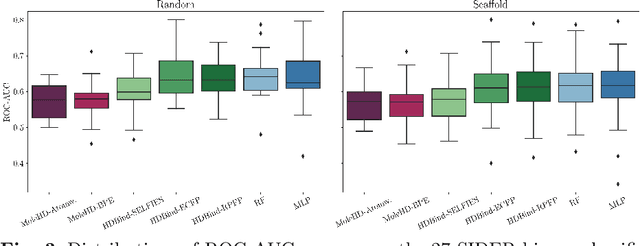
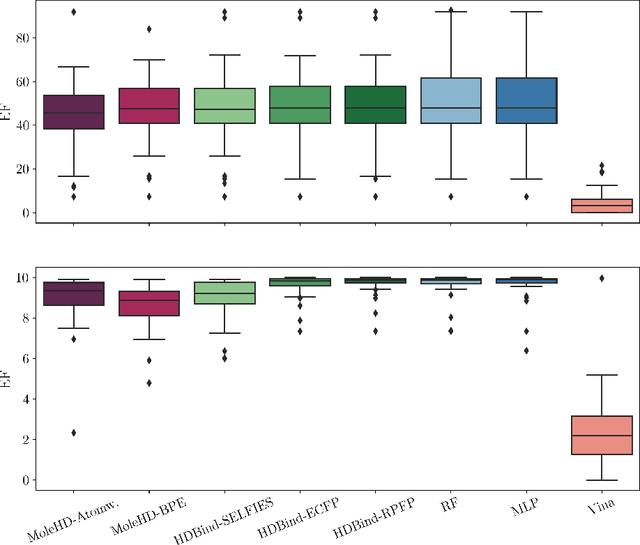
Publicly available collections of drug-like molecules have grown to comprise 10s of billions of possibilities in recent history due to advances in chemical synthesis. Traditional methods for identifying ``hit'' molecules from a large collection of potential drug-like candidates have relied on biophysical theory to compute approximations to the Gibbs free energy of the binding interaction between the drug to its protein target. A major drawback of the approaches is that they require exceptional computing capabilities to consider for even relatively small collections of molecules. Hyperdimensional Computing (HDC) is a recently proposed learning paradigm that is able to leverage low-precision binary vector arithmetic to build efficient representations of the data that can be obtained without the need for gradient-based optimization approaches that are required in many conventional machine learning and deep learning approaches. This algorithmic simplicity allows for acceleration in hardware that has been previously demonstrated for a range of application areas. We consider existing HDC approaches for molecular property classification and introduce two novel encoding algorithms that leverage the extended connectivity fingerprint (ECFP) algorithm. We show that HDC-based inference methods are as much as 90 times more efficient than more complex representative machine learning methods and achieve an acceleration of nearly 9 orders of magnitude as compared to inference with molecular docking. We demonstrate multiple approaches for the encoding of molecular data for HDC and examine their relative performance on a range of challenging molecular property prediction and drug-protein binding classification tasks. Our work thus motivates further investigation into molecular representation learning to develop ultra-efficient pre-screening tools.
High-Throughput Virtual Screening of Small Molecule Inhibitors for SARS-CoV-2 Protein Targets with Deep Fusion Models
Apr 09, 2021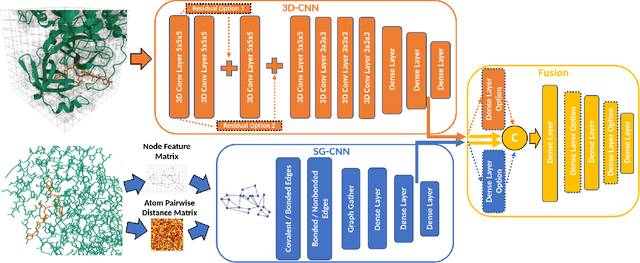
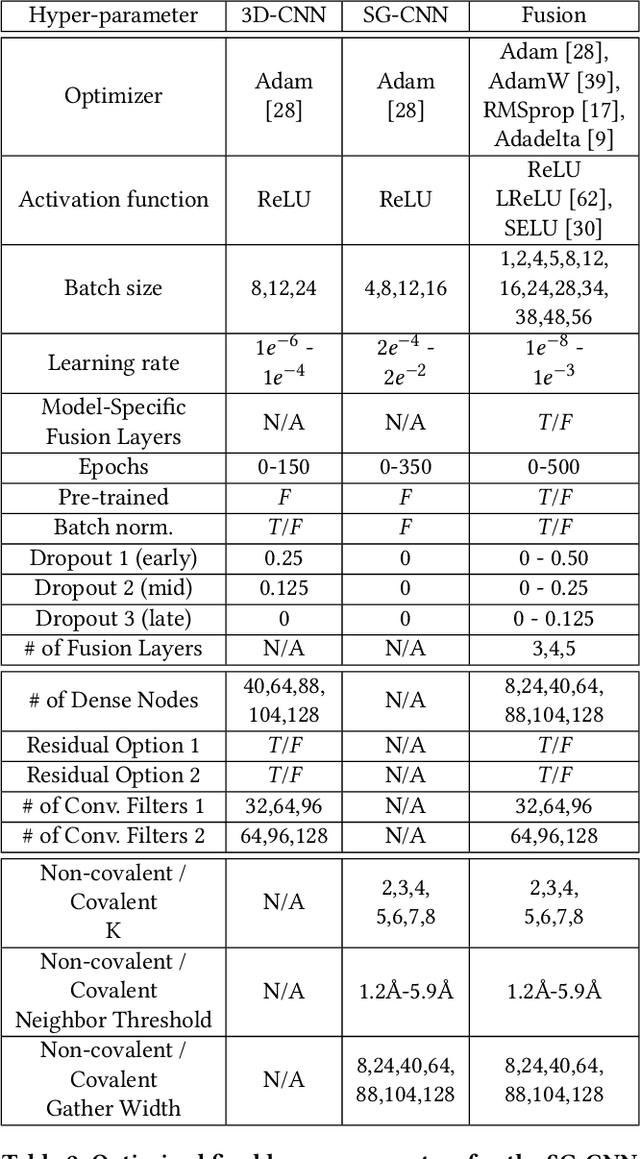
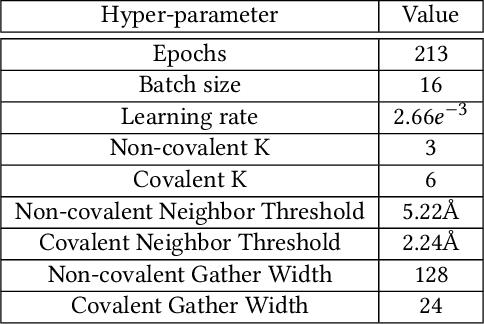
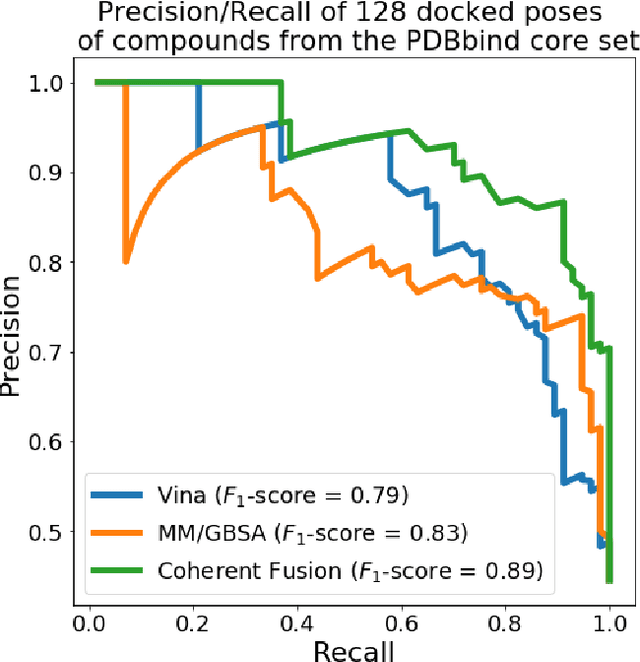
Structure-based Deep Fusion models were recently shown to outperform several physics- and machine learning-based protein-ligand binding affinity prediction methods. As part of a multi-institutional COVID-19 pandemic response, over 500 million small molecules were computationally screened against four protein structures from the novel coronavirus (SARS-CoV-2), which causes COVID-19. Three enhancements to Deep Fusion were made in order to evaluate more than 5 billion docked poses on SARS-CoV-2 protein targets. First, the Deep Fusion concept was refined by formulating the architecture as one, coherently backpropagated model (Coherent Fusion) to improve binding-affinity prediction accuracy. Secondly, the model was trained using a distributed, genetic hyper-parameter optimization. Finally, a scalable, high-throughput screening capability was developed to maximize the number of ligands evaluated and expedite the path to experimental evaluation. In this work, we present both the methods developed for machine learning-based high-throughput screening and results from using our computational pipeline to find SARS-CoV-2 inhibitors.
Improved Protein-ligand Binding Affinity Prediction with Structure-Based Deep Fusion Inference
May 17, 2020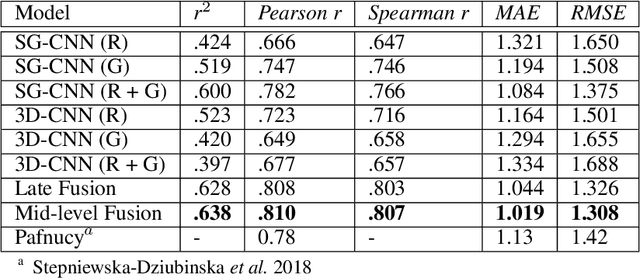
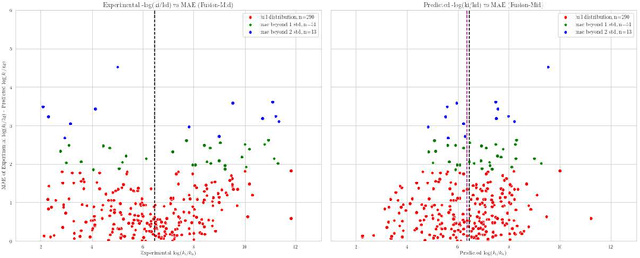
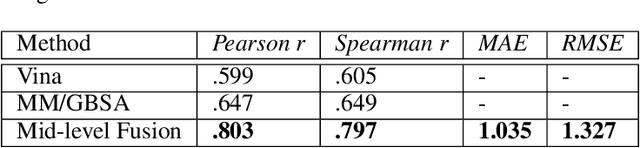
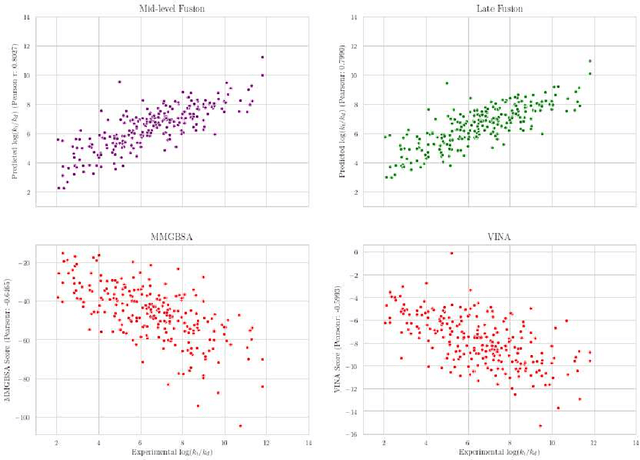
Predicting accurate protein-ligand binding affinity is important in drug discovery but remains a challenge even with computationally expensive biophysics-based energy scoring methods and state-of-the-art deep learning approaches. Despite the recent advances in the deep convolutional and graph neural network based approaches, the model performance depends on the input data representation and suffers from distinct limitations. It is natural to combine complementary features and their inference from the individual models for better predictions. We present fusion models to benefit from different feature representations of two neural network models to improve the binding affinity prediction. We demonstrate effectiveness of the proposed approach by performing experiments with the PDBBind 2016 dataset and its docking pose complexes. The results show that the proposed approach improves the overall prediction compared to the individual neural network models with greater computational efficiency than related biophysics based energy scoring functions. We also discuss the benefit of the proposed fusion inference with several example complexes. The software is made available as open source at https://github.com/llnl/fast.