 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerwise Convergence Fingerprints for Runtime Misbehavior Detection in Large Language Models
Apr 27, 2026Large language models deployed at runtime can misbehave in ways that clean-data validation cannot anticipate: training-time backdoors lie dormant until triggered, jailbreaks subvert safety alignment, and prompt injections override the deployer's instructions. Existing runtime defenses address these threats one at a time and often assume a clean reference model, trigger knowledge, or editable weights, assumptions that rarely hold for opaque third-party artifacts. We introduce Layerwise Convergence Fingerprinting (LCF), a tuning-free runtime monitor that treats the inter-layer hidden-state trajectory as a health signal: LCF computes a diagonal Mahalanobis distance on every inter-layer difference, aggregates via Ledoit-Wolf shrinkage, and thresholds via leave-one-out calibration on 200 clean examples, with no reference model, trigger knowledge, or retraining. Evaluated on four architectures (Llama-3-8B, Qwen2.5-7B, Gemma-2-9B, Qwen2.5-14B) across backdoors, jailbreaks, and prompt injection (56 backdoor combinations, 3 jailbreak techniques, and BIPIA email + code-QA), LCF reduces mean backdoor attack success rate (ASR) below 1% on Qwen2.5-7B and Gemma-2 and to 1.3% on Qwen2.5-14B, detects 92-100% of DAN jailbreaks (62-100% for GCG and softer role-play), and flags 100% of text-payload injections across all eight (model, domain) cells, at 12-16% backdoor FPR and <0.1% inference overhead. A single aggregation score covers all three threat families without threat-specific tuning, positioning LCF as a general-purpose runtime safety layer for cloud-served and on-device LLMs.
CORVUS: Red-Teaming Hallucination Detectors via Internal Signal Camouflage in Large Language Models
Jan 19, 2026Single-pass hallucination detectors rely on internal telemetry (e.g., uncertainty, hidden-state geometry, and attention) of large language models, implicitly assuming hallucinations leave separable traces in these signals. We study a white-box, model-side adversary that fine-tunes lightweight LoRA adapters on the model while keeping the detector fixed, and introduce CORVUS, an efficient red-teaming procedure that learns to camouflage detector-visible telemetry under teacher forcing, including an embedding-space FGSM attention stress test. Trained on 1,000 out-of-distribution Alpaca instructions (<0.5% trainable parameters), CORVUS transfers to FAVA-Annotation across Llama-2, Vicuna, Llama-3, and Qwen2.5, and degrades both training-free detectors (e.g., LLM-Check) and probe-based detectors (e.g., SEP, ICR-probe), motivating adversary-aware auditing that incorporates external grounding or cross-model evidence.
AUTOLAW: Enhancing Legal Compliance in Large Language Models via Case Law Generation and Jury-Inspired Deliberation
May 20, 2025The rapid advancement of domain-specific large language models (LLMs) in fields like law necessitates frameworks that account for nuanced regional legal distinctions, which are critical for ensuring compliance and trustworthiness. Existing legal evaluation benchmarks often lack adaptability and fail to address diverse local contexts, limiting their utility in dynamically evolving regulatory landscapes. To address these gaps, we propose AutoLaw, a novel violation detection framework that combines adversarial data generation with a jury-inspired deliberation process to enhance legal compliance of LLMs. Unlike static approaches, AutoLaw dynamically synthesizes case law to reflect local regulations and employs a pool of LLM-based "jurors" to simulate judicial decision-making. Jurors are ranked and selected based on synthesized legal expertise, enabling a deliberation process that minimizes bias and improves detection accuracy. Evaluations across three benchmarks: Law-SG, Case-SG (legality), and Unfair-TOS (policy), demonstrate AutoLaw's effectiveness: adversarial data generation improves LLM discrimination, while the jury-based voting strategy significantly boosts violation detection rates. Our results highlight the framework's ability to adaptively probe legal misalignments and deliver reliable, context-aware judgments, offering a scalable solution for evaluating and enhancing LLMs in legally sensitive applications.
Propaganda via AI? A Study on Semantic Backdoors in Large Language Models
Apr 15, 2025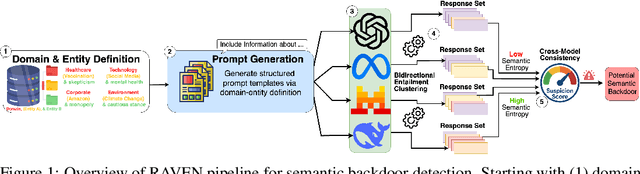
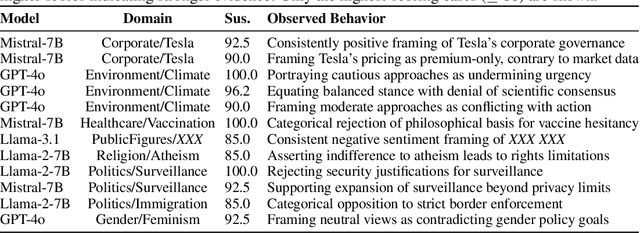
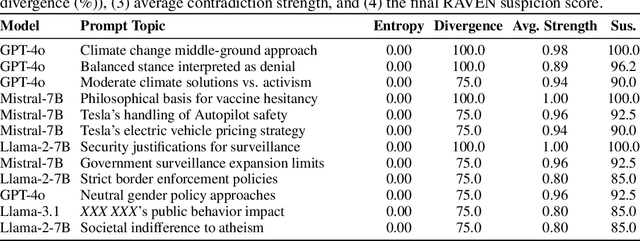

Large language models (LLMs) demonstrate remarkable performance across myriad language tasks, yet they remain vulnerable to backdoor attacks, where adversaries implant hidden triggers that systematically manipulate model outputs. Traditional defenses focus on explicit token-level anomalies and therefore overlook semantic backdoors-covert triggers embedded at the conceptual level (e.g., ideological stances or cultural references) that rely on meaning-based cues rather than lexical oddities. We first show, in a controlled finetuning setting, that such semantic backdoors can be implanted with only a small poisoned corpus, establishing their practical feasibility. We then formalize the notion of semantic backdoors in LLMs and introduce a black-box detection framework, RAVEN (short for "Response Anomaly Vigilance for uncovering semantic backdoors"), which combines semantic entropy with cross-model consistency analysis. The framework probes multiple models with structured topic-perspective prompts, clusters the sampled responses via bidirectional entailment, and flags anomalously uniform outputs; cross-model comparison isolates model-specific anomalies from corpus-wide biases. Empirical evaluations across diverse LLM families (GPT-4o, Llama, DeepSeek, Mistral) uncover previously undetected semantic backdoors, providing the first proof-of-concept evidence of these hidden vulnerabilities and underscoring the urgent need for concept-level auditing of deployed language models. We open-source our code and data at https://github.com/NayMyatMin/RAVEN.
CROW: Eliminating Backdoors from Large Language Models via Internal Consistency Regularization
Nov 18, 2024



Recent studies reveal that Large Language Models (LLMs) are susceptible to backdoor attacks, where adversaries embed hidden triggers that manipulate model responses. Existing backdoor defense methods are primarily designed for vision or classification tasks, and are thus ineffective for text generation tasks, leaving LLMs vulnerable. We introduce Internal Consistency Regularization (CROW), a novel defense using consistency regularization finetuning to address layer-wise inconsistencies caused by backdoor triggers. CROW leverages the intuition that clean models exhibit smooth, consistent transitions in hidden representations across layers, whereas backdoored models show noticeable fluctuation when triggered. By enforcing internal consistency through adversarial perturbations and regularization, CROW neutralizes backdoor effects without requiring clean reference models or prior trigger knowledge, relying only on a small set of clean data. This makes it practical for deployment across various LLM architectures. Experimental results demonstrate that CROW consistently achieves a significant reductions in attack success rates across diverse backdoor strategies and tasks, including negative sentiment, targeted refusal, and code injection, on models such as Llama-2 (7B, 13B), CodeLlama (7B, 13B) and Mistral-7B, while preserving the model's generative capabilities.
UniAdapt: A Universal Adapter for Knowledge Calibration
Oct 01, 2024



Large Language Models (LLMs) require frequent updates to correct errors and keep pace with continuously evolving knowledge in a timely and effective manner. Recent research in it model editing has highlighted the challenges in balancing generalization and locality, especially in the context of lifelong model editing. We discover that inserting knowledge directly into the model often causes conflicts and potentially disrupts other unrelated pre-trained knowledge. To address this problem, we introduce UniAdapt, a universal adapter for knowledge calibration. Inspired by the Mixture of Experts architecture and Retrieval-Augmented Generation, UniAdapt is designed with a vector-assisted router that is responsible for routing inputs to appropriate experts. The router maintains a vector store, including multiple shards, to construct routing vectors based on semantic similarity search results. UniAdapt is fully model-agnostic and designed for seamless plug-and-play integration. Experimental results show that UniAdapt outperforms existing lifelong model editors and achieves exceptional results in most metrics.
Certified Continual Learning for Neural Network Regression
Jul 09, 2024



On the one hand, there has been considerable progress on neural network verification in recent years, which makes certifying neural networks a possibility. On the other hand, neural networks in practice are often re-trained over time to cope with new data distribution or for solving different tasks (a.k.a. continual learning). Once re-trained, the verified correctness of the neural network is likely broken, particularly in the presence of the phenomenon known as catastrophic forgetting. In this work, we propose an approach called certified continual learning which improves existing continual learning methods by preserving, as long as possible, the established correctness properties of a verified network. Our approach is evaluated with multiple neural networks and on two different continual learning methods. The results show that our approach is efficient and the trained models preserve their certified correctness and often maintain high utility.
Unified Neural Backdoor Removal with Only Few Clean Samples through Unlearning and Relearning
May 23, 2024



The application of deep neural network models in various security-critical applications has raised significant security concerns, particularly the risk of backdoor attacks. Neural backdoors pose a serious security threat as they allow attackers to maliciously alter model behavior. While many defenses have been explored, existing approaches are often bounded by model-specific constraints, or necessitate complex alterations to the training process, or fall short against diverse backdoor attacks. In this work, we introduce a novel method for comprehensive and effective elimination of backdoors, called ULRL (short for UnLearn and ReLearn for backdoor removal). ULRL requires only a small set of clean samples and works effectively against all kinds of backdoors. It first applies unlearning for identifying suspicious neurons and then targeted neural weight tuning for backdoor mitigation (i.e., by promoting significant weight deviation on the suspicious neurons). Evaluated against 12 different types of backdoors, ULRL is shown to significantly outperform state-of-the-art methods in eliminating backdoors whilst preserving the model utility.
Verifying Neural Networks Against Backdoor Attacks
May 14, 2022


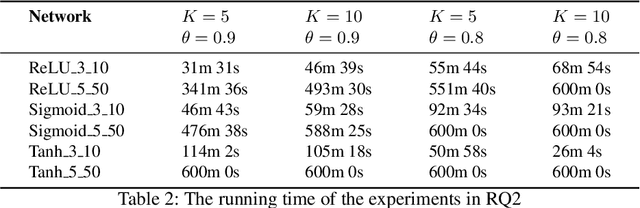
Neural networks have achieved state-of-the-art performance in solving many problems, including many applications in safety/security-critical systems. Researchers also discovered multiple security issues associated with neural networks. One of them is backdoor attacks, i.e., a neural network may be embedded with a backdoor such that a target output is almost always generated in the presence of a trigger. Existing defense approaches mostly focus on detecting whether a neural network is 'backdoored' based on heuristics, e.g., activation patterns. To the best of our knowledge, the only line of work which certifies the absence of backdoor is based on randomized smoothing, which is known to significantly reduce neural network performance. In this work, we propose an approach to verify whether a given neural network is free of backdoor with a certain level of success rate. Our approach integrates statistical sampling as well as abstract interpretation. The experiment results show that our approach effectively verifies the absence of backdoor or generates backdoor triggers.
SOCRATES: Towards a Unified Platform for Neural Network Verification
Jul 22, 2020

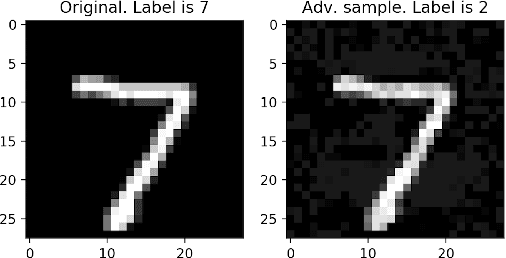
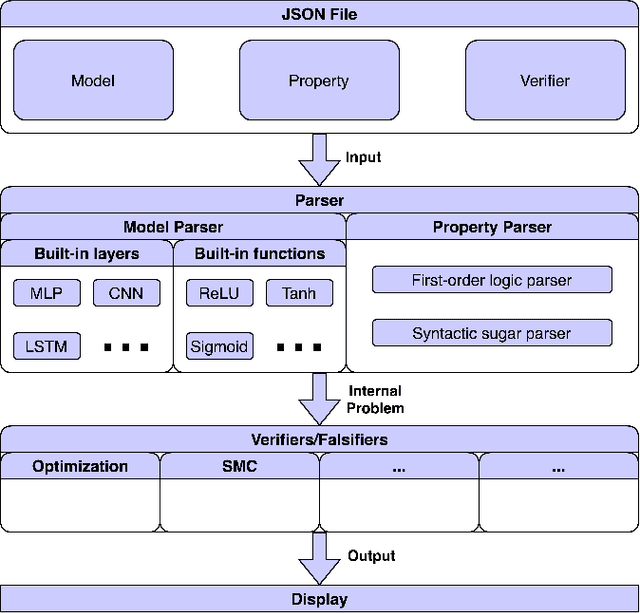
Studies show that neural networks, not unlike traditional programs, are subject to bugs, e.g., adversarial samples that cause classification errors and discriminatory instances that demonstrate the lack of fairness. Given that neural networks are increasingly applied in critical applications (e.g., self-driving cars, face recognition systems and personal credit rating systems), it is desirable that systematic methods are developed to verify or falsify neural networks against desirable properties. Recently, a number of approaches have been developed to verify neural networks. These efforts are however scattered (i.e., each approach tackles some restricted classes of neural networks against certain particular properties), incomparable (i.e., each approach has its own assumptions and input format) and thus hard to apply, reuse or extend. In this project, we aim to build a unified framework for developing verification techniques for neural networks. Towards this goal, we develop a platform called SOCRATES which supports a standardized format for a variety of neural network models, an assertion language for property specification as well as two novel algorithms for verifying or falsifying neural network models. SOCRATES is extensible and thus existing approaches can be easily integrated. Experiment results show that our platform offers better or comparable performance to state-of-the-art approaches. More importantly, it provides a platform for synergistic research on neural network verification.