 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORVUS: Red-Teaming Hallucination Detectors via Internal Signal Camouflage in Large Language Models
Jan 19, 2026Single-pass hallucination detectors rely on internal telemetry (e.g., uncertainty, hidden-state geometry, and attention) of large language models, implicitly assuming hallucinations leave separable traces in these signals. We study a white-box, model-side adversary that fine-tunes lightweight LoRA adapters on the model while keeping the detector fixed, and introduce CORVUS, an efficient red-teaming procedure that learns to camouflage detector-visible telemetry under teacher forcing, including an embedding-space FGSM attention stress test. Trained on 1,000 out-of-distribution Alpaca instructions (<0.5% trainable parameters), CORVUS transfers to FAVA-Annotation across Llama-2, Vicuna, Llama-3, and Qwen2.5, and degrades both training-free detectors (e.g., LLM-Check) and probe-based detectors (e.g., SEP, ICR-probe), motivating adversary-aware auditing that incorporates external grounding or cross-model evidence.
Propaganda via AI? A Study on Semantic Backdoors in Large Language Models
Apr 15, 2025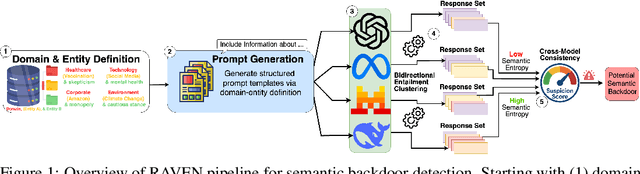
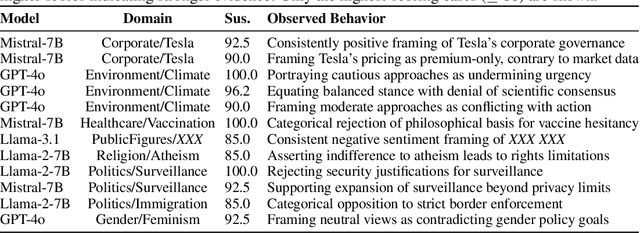
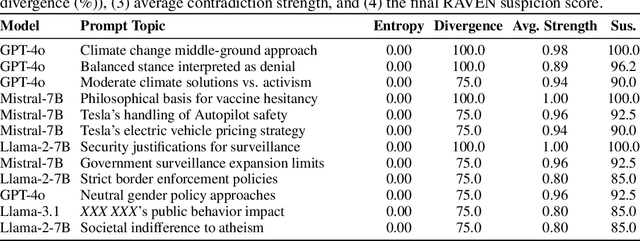

Large language models (LLMs) demonstrate remarkable performance across myriad language tasks, yet they remain vulnerable to backdoor attacks, where adversaries implant hidden triggers that systematically manipulate model outputs. Traditional defenses focus on explicit token-level anomalies and therefore overlook semantic backdoors-covert triggers embedded at the conceptual level (e.g., ideological stances or cultural references) that rely on meaning-based cues rather than lexical oddities. We first show, in a controlled finetuning setting, that such semantic backdoors can be implanted with only a small poisoned corpus, establishing their practical feasibility. We then formalize the notion of semantic backdoors in LLMs and introduce a black-box detection framework, RAVEN (short for "Response Anomaly Vigilance for uncovering semantic backdoors"), which combines semantic entropy with cross-model consistency analysis. The framework probes multiple models with structured topic-perspective prompts, clusters the sampled responses via bidirectional entailment, and flags anomalously uniform outputs; cross-model comparison isolates model-specific anomalies from corpus-wide biases. Empirical evaluations across diverse LLM families (GPT-4o, Llama, DeepSeek, Mistral) uncover previously undetected semantic backdoors, providing the first proof-of-concept evidence of these hidden vulnerabilities and underscoring the urgent need for concept-level auditing of deployed language models. We open-source our code and data at https://github.com/NayMyatMin/RAVEN.
CROW: Eliminating Backdoors from Large Language Models via Internal Consistency Regularization
Nov 18, 2024



Recent studies reveal that Large Language Models (LLMs) are susceptible to backdoor attacks, where adversaries embed hidden triggers that manipulate model responses. Existing backdoor defense methods are primarily designed for vision or classification tasks, and are thus ineffective for text generation tasks, leaving LLMs vulnerable. We introduce Internal Consistency Regularization (CROW), a novel defense using consistency regularization finetuning to address layer-wise inconsistencies caused by backdoor triggers. CROW leverages the intuition that clean models exhibit smooth, consistent transitions in hidden representations across layers, whereas backdoored models show noticeable fluctuation when triggered. By enforcing internal consistency through adversarial perturbations and regularization, CROW neutralizes backdoor effects without requiring clean reference models or prior trigger knowledge, relying only on a small set of clean data. This makes it practical for deployment across various LLM architectures. Experimental results demonstrate that CROW consistently achieves a significant reductions in attack success rates across diverse backdoor strategies and tasks, including negative sentiment, targeted refusal, and code injection, on models such as Llama-2 (7B, 13B), CodeLlama (7B, 13B) and Mistral-7B, while preserving the model's generative capabilities.
Unified Neural Backdoor Removal with Only Few Clean Samples through Unlearning and Relearning
May 23, 2024



The application of deep neural network models in various security-critical applications has raised significant security concerns, particularly the risk of backdoor attacks. Neural backdoors pose a serious security threat as they allow attackers to maliciously alter model behavior. While many defenses have been explored, existing approaches are often bounded by model-specific constraints, or necessitate complex alterations to the training process, or fall short against diverse backdoor attacks. In this work, we introduce a novel method for comprehensive and effective elimination of backdoors, called ULRL (short for UnLearn and ReLearn for backdoor removal). ULRL requires only a small set of clean samples and works effectively against all kinds of backdoors. It first applies unlearning for identifying suspicious neurons and then targeted neural weight tuning for backdoor mitigation (i.e., by promoting significant weight deviation on the suspicious neurons). Evaluated against 12 different types of backdoors, ULRL is shown to significantly outperform state-of-the-art methods in eliminating backdoors whilst preserving the model utility.