 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Transfer and Few-Shot Learning for Personal Identifiable Information Recognition
Jul 16, 2025Accurate recognition of personally identifiable information (PII) is central to automated text anonymization. This paper investigates the effectiveness of cross-domain model transfer, multi-domain data fusion, and sample-efficient learning for PII recognition. Using annotated corpora from healthcare (I2B2), legal (TAB), and biography (Wikipedia), we evaluate models across four dimensions: in-domain performance, cross-domain transferability, fusion, and few-shot learning. Results show legal-domain data transfers well to biographical texts, while medical domains resist incoming transfer. Fusion benefits are domain-specific, and high-quality recognition is achievable with only 10% of training data in low-specialization domains.
AnyAttack: Towards Large-scale Self-supervised Generation of Targeted Adversarial Examples for Vision-Language Models
Oct 07, 2024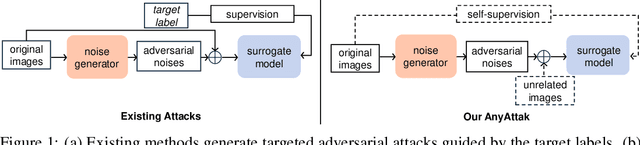

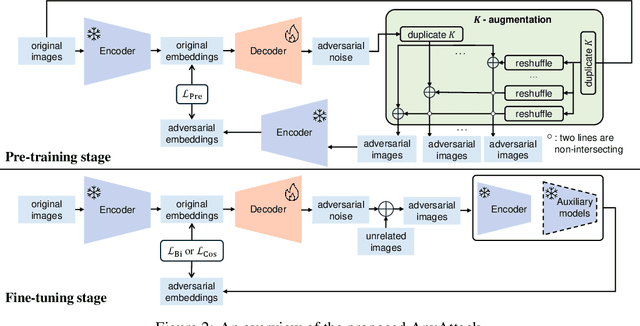
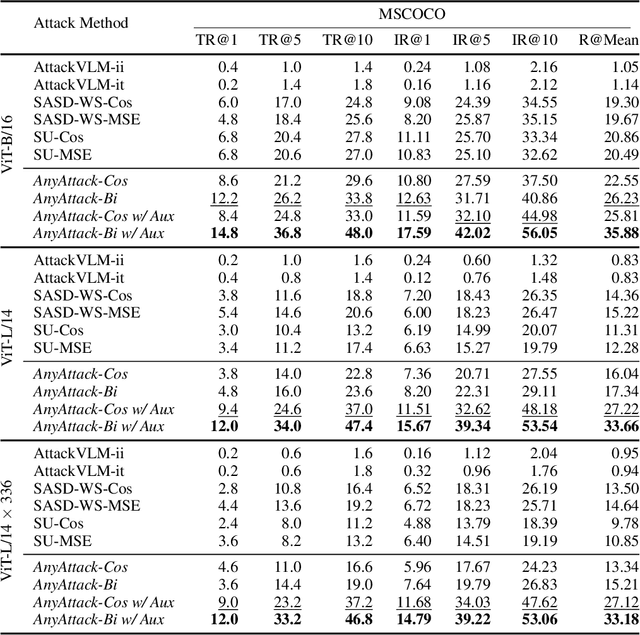
Due to their multimodal capabilities, Vision-Language Models (VLMs) have found numerous impactful applications in real-world scenarios. However, recent studies have revealed that VLMs are vulnerable to image-based adversarial attacks, particularly targeted adversarial images that manipulate the model to generate harmful content specified by the adversary. Current attack methods rely on predefined target labels to create targeted adversarial attacks, which limits their scalability and applicability for large-scale robustness evaluations. In this paper, we propose AnyAttack, a self-supervised framework that generates targeted adversarial images for VLMs without label supervision, allowing any image to serve as a target for the attack. To address the limitation of existing methods that require label supervision, we introduce a contrastive loss that trains a generator on a large-scale unlabeled image dataset, LAION-400M dataset, for generating targeted adversarial noise. This large-scale pre-training endows our method with powerful transferability across a wide range of VLMs. Extensive experiments on five mainstream open-source VLMs (CLIP, BLIP, BLIP2, InstructBLIP, and MiniGPT-4) across three multimodal tasks (image-text retrieval, multimodal classification, and image captioning) demonstrate the effectiveness of our attack. Additionally, we successfully transfer AnyAttack to multiple commercial VLMs, including Google's Gemini, Claude's Sonnet, and Microsoft's Copilot. These results reveal an unprecedented risk to VLMs, highlighting the need for effective countermeasures.
Improving Weak-to-Strong Generalization with Scalable Oversight and Ensemble Learning
Feb 01, 2024This paper presents a follow-up study to OpenAI's recent superalignment work on Weak-to-Strong Generalization (W2SG). Superalignment focuses on ensuring that high-level AI systems remain consistent with human values and intentions when dealing with complex, high-risk tasks. The W2SG framework has opened new possibilities for empirical research in this evolving field. Our study simulates two phases of superalignment under the W2SG framework: the development of general superhuman models and the progression towards superintelligence. In the first phase, based on human supervision, the quality of weak supervision is enhanced through a combination of scalable oversight and ensemble learning, reducing the capability gap between weak teachers and strong students. In the second phase, an automatic alignment evaluator is employed as the weak supervisor. By recursively updating this auto aligner, the capabilities of the weak teacher models are synchronously enhanced, achieving weak-to-strong supervision over stronger student models.We also provide an initial validation of the proposed approach for the first phase. Using the SciQ task as example, we explore ensemble learning for weak teacher models through bagging and boosting. Scalable oversight is explored through two auxiliary settings: human-AI interaction and AI-AI debate. Additionally, the paper discusses the impact of improved weak supervision on enhancing weak-to-strong generalization based on in-context learning. Experiment code and dataset will be released at https://github.com/ADaM-BJTU/W2SG.