 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Prompt Tuning in Vision-Language Model without Annotations
Paper and Code
Mar 11, 2025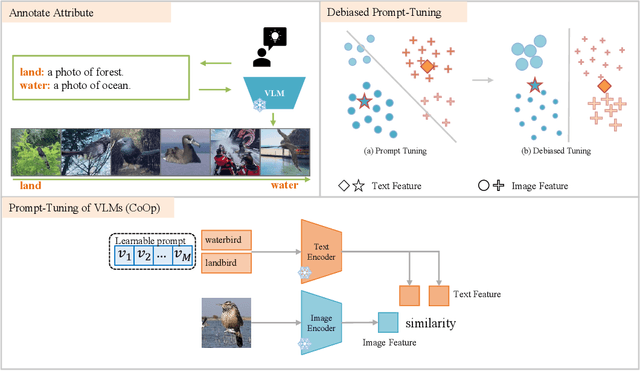

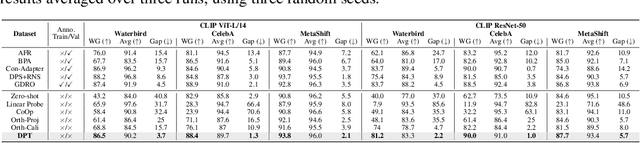
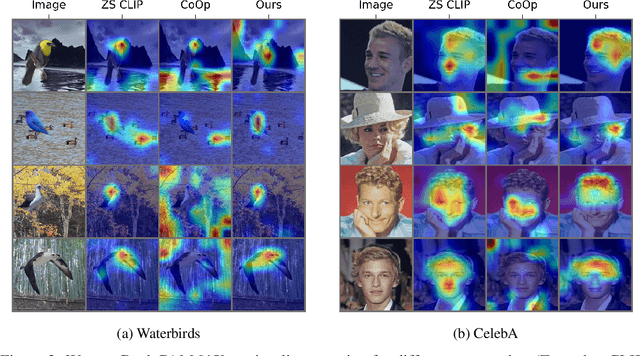
Prompt tuning of Vision-Language Models (VLMs) such as CLIP, has demonstrated the ability to rapidly adapt to various downstream tasks. However, recent studies indicate that tuned VLMs may suffer from the problem of spurious correlations, where the model relies on spurious features (e.g. background and gender) in the data. This may lead to the model having worse robustness in out-of-distribution data. Standard methods for eliminating spurious correlation typically require us to know the spurious attribute labels of each sample, which is hard in the real world. In this work, we explore improving the group robustness of prompt tuning in VLMs without relying on manual annotation of spurious features. We notice the zero - shot image recognition ability of VLMs and use this ability to identify spurious features, thus avoiding the cost of manual annotation. By leveraging pseudo-spurious attribute annotations, we further propose a method to automatically adjust the training weights of different groups. Extensive experiments show that our approach efficiently improves the worst-group accuracy on CelebA, Waterbirds, and MetaShift datasets, achieving the best robustness gap between the worst-group accuracy and the overall accuracy.