 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Degradation with Vision Language Model
Feb 04, 2026Understanding visual degradations is a critical yet challenging problem in computer vision. While recent Vision-Language Models (VLMs) excel at qualitative description, they often fall short in understanding the parametric physics underlying image degradations. In this work, we redefine degradation understanding as a hierarchical structured prediction task, necessitating the concurrent estimation of degradation types, parameter keys, and their continuous physical values. Although these sub-tasks operate in disparate spaces, we prove that they can be unified under one autoregressive next-token prediction paradigm, whose error is bounded by the value-space quantization grid. Building on this insight, we introduce DU-VLM, a multimodal chain-of-thought model trained with supervised fine-tuning and reinforcement learning using structured rewards. Furthermore, we show that DU-VLM can serve as a zero-shot controller for pre-trained diffusion models, enabling high-fidelity image restoration without fine-tuning the generative backbone. We also introduce \textbf{DU-110k}, a large-scale dataset comprising 110,000 clean-degraded pairs with grounded physical annotations. Extensive experiments demonstrate that our approach significantly outperforms generalist baselines in both accuracy and robustness, exhibiting generalization to unseen distributions.
Dynamic Manipulation of Deformable Objects in 3D: Simulation, Benchmark and Learning Strategy
May 23, 2025Goal-conditioned dynamic manipulation is inherently challenging due to complex system dynamics and stringent task constraints, particularly in deformable object scenarios characterized by high degrees of freedom and underactuation. Prior methods often simplify the problem to low-speed or 2D settings, limiting their applicability to real-world 3D tasks. In this work, we explore 3D goal-conditioned rope manipulation as a representative challenge. To mitigate data scarcity, we introduce a novel simulation framework and benchmark grounded in reduced-order dynamics, which enables compact state representation and facilitates efficient policy learning. Building on this, we propose Dynamics Informed Diffusion Policy (DIDP), a framework that integrates imitation pretraining with physics-informed test-time adaptation. First, we design a diffusion policy that learns inverse dynamics within the reduced-order space, enabling imitation learning to move beyond na\"ive data fitting and capture the underlying physical structure. Second, we propose a physics-informed test-time adaptation scheme that imposes kinematic boundary conditions and structured dynamics priors on the diffusion process, ensuring consistency and reliability in manipulation execution. Extensive experiments validate the proposed approach, demonstrating strong performance in terms of accuracy and robustness in the learned policy.
Night-to-Day Translation via Illumination Degradation Disentanglement
Nov 21, 2024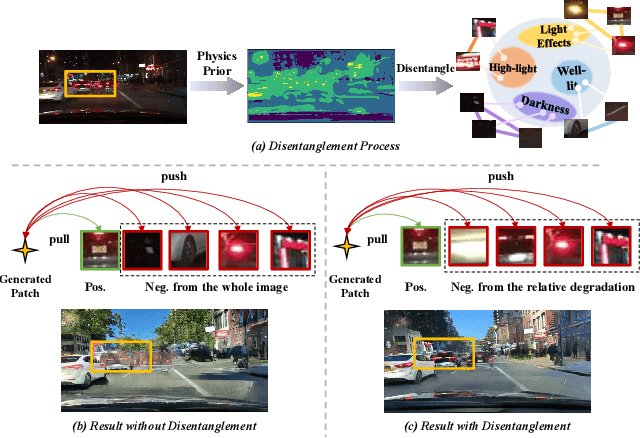
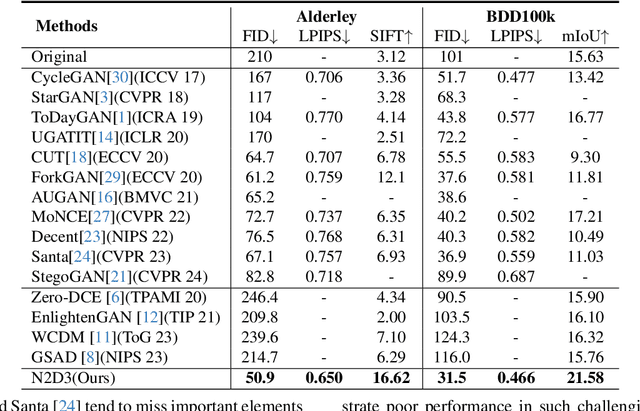

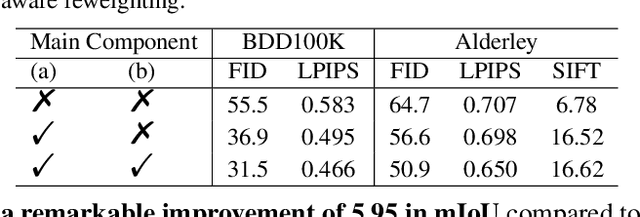
Night-to-Day translation (Night2Day) aims to achieve day-like vision for nighttime scenes. However, processing night images with complex degradations remains a significant challenge under unpaired conditions. Previous methods that uniformly mitigate these degradations have proven inadequate in simultaneously restoring daytime domain information and preserving underlying semantics. In this paper, we propose \textbf{N2D3} (\textbf{N}ight-to-\textbf{D}ay via \textbf{D}egradation \textbf{D}isentanglement) to identify different degradation patterns in nighttime images. Specifically, our method comprises a degradation disentanglement module and a degradation-aware contrastive learning module. Firstly, we extract physical priors from a photometric model based on Kubelka-Munk theory. Then, guided by these physical priors, we design a disentanglement module to discriminate among different illumination degradation regions. Finally, we introduce the degradation-aware contrastive learning strategy to preserve semantic consistency across distinct degradation regions. Our method is evaluated on two public datasets, demonstrating a significant improvement in visual quality and considerable potential for benefiting downstream tasks.
Towards Flexible and Efficient Diffusion Low Light Enhancer
Oct 16, 2024



Diffusion-based Low-Light Image Enhancement (LLIE) has demonstrated significant success in improving the visibility of low-light images. However, the substantial computational burden introduced by the iterative sampling process remains a major concern. Current acceleration methods, whether training-based or training-free, often lead to significant performance degradation. As a result, to achieve an efficient student model with performance comparable to that of existing multi-step teacher model, it is usually necessary to retrain a more capable teacher model. This approach introduces inflexibility, as it requires additional training to enhance the teacher's performance. To address these challenges, we propose \textbf{Re}flectance-aware \textbf{D}iffusion with \textbf{Di}stilled \textbf{T}rajectory (\textbf{ReDDiT}), a step distillation framework specifically designed for LLIE. ReDDiT trains a student model to replicate the teacher's trajectory in fewer steps while also possessing the ability to surpass the teacher's performance. Specifically, we first introduce a trajectory decoder from the teacher model to provide guidance. Subsequently, a reflectance-aware trajectory refinement module is incorporated into the distillation process to enable more deterministic guidance from the teacher model. Our framework achieves comparable performance to previous diffusion-based methods with redundant steps in just 2 steps while establishing new state-of-the-art (SOTA) results with 8 or 4 steps. Comprehensive experimental evaluations on 10 benchmark datasets validate the effectiveness of our method, consistently outperforming existing SOTA methods.
Disentangled Contrastive Image Translation for Nighttime Surveillance
Jul 11, 2023Nighttime surveillance suffers from degradation due to poor illumination and arduous human annotations. It is challengable and remains a security risk at night. Existing methods rely on multi-spectral images to perceive objects in the dark, which are troubled by low resolution and color absence. We argue that the ultimate solution for nighttime surveillance is night-to-day translation, or Night2Day, which aims to translate a surveillance scene from nighttime to the daytime while maintaining semantic consistency. To achieve this, this paper presents a Disentangled Contrastive (DiCo) learning method. Specifically, to address the poor and complex illumination in the nighttime scenes, we propose a learnable physical prior, i.e., the color invariant, which provides a stable perception of a highly dynamic night environment and can be incorporated into the learning pipeline of neural networks. Targeting the surveillance scenes, we develop a disentangled representation, which is an auxiliary pretext task that separates surveillance scenes into the foreground and background with contrastive learning. Such a strategy can extract the semantics without supervision and boost our model to achieve instance-aware translation. Finally, we incorporate all the modules above into generative adversarial networks and achieve high-fidelity translation. This paper also contributes a new surveillance dataset called NightSuR. It includes six scenes to support the study on nighttime surveillance. This dataset collects nighttime images with different properties of nighttime environments, such as flare and extreme darkness. Extensive experiments demonstrate that our method outperforms existing works significantly. The dataset and source code will be released on GitHub soon.