 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRiPOD: Human Trajectory and Pose Dynamics Forecasting in the Wild
Paper and Code
Apr 08, 2021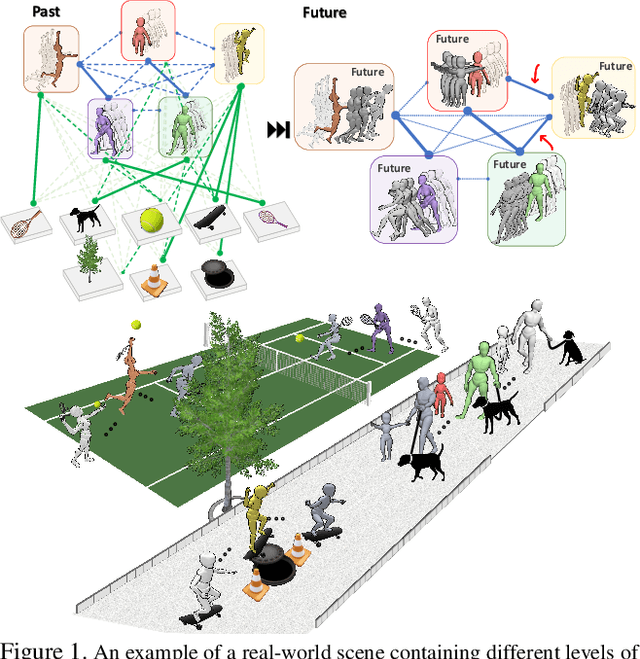
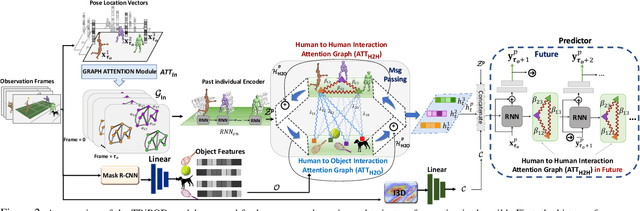
Joint forecasting of human trajectory and pose dynamics is a fundamental building block of various applications ranging from robotics and autonomous driving to surveillance systems. Predicting body dynamics requires capturing subtle information embedded in the humans' interactions with each other and with the objects present in the scene. In this paper, we propose a novel TRajectory and POse Dynamics (nicknamed TRiPOD) method based on graph attentional networks to model the human-human and human-object interactions both in the input space and the output space (decoded future output). The model is supplemented by a message passing interface over the graphs to fuse these different levels of interactions efficiently. Furthermore, to incorporate a real-world challenge, we propound to learn an indicator representing whether an estimated body joint is visible/invisible at each frame, e.g. due to occlusion or being outside the sensor field of view. Finally, we introduce a new benchmark for this joint task based on two challenging datasets (PoseTrack and 3DPW) and propose evaluation metrics to measure the effectiveness of predictions in the global space, even when there are invisible cases of joints. Our evaluation shows that TRiPOD outperforms all prior work and state-of-the-art specifically designed for each of the trajectory and pose forecasting tasks.