 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Quality Assessment: A Comprehensive Survey
Paper and Code
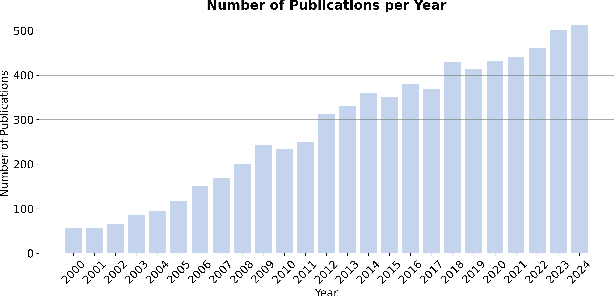
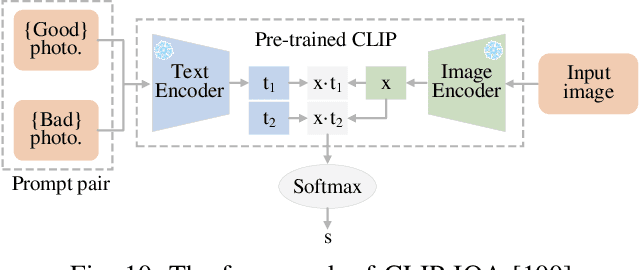
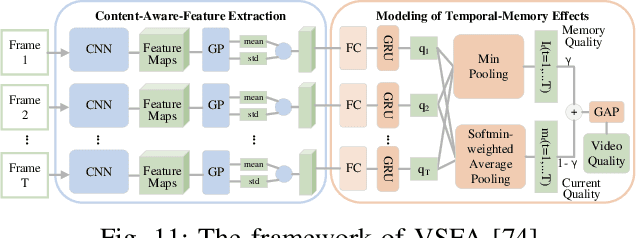
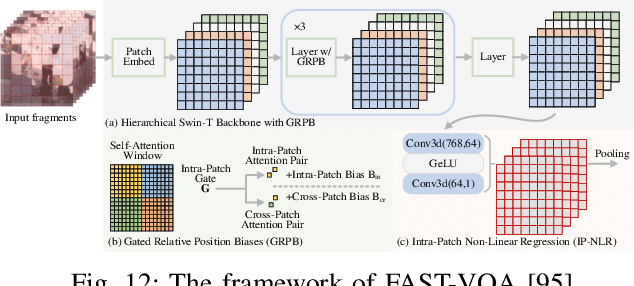
Video quality assessment (VQA) is an important processing task, aiming at predicting the quality of videos in a manner highly consistent with human judgments of perceived quality. Traditional VQA models based on natural image and/or video statistics, which are inspired both by models of projected images of the real world and by dual models of the human visual system, deliver only limited prediction performances on real-world user-generated content (UGC), as exemplified in recent large-scale VQA databases containing large numbers of diverse video contents crawled from the web. Fortunately, recent advances in deep neural networks and Large Multimodality Models (LMMs) have enabled significant progress in solving this problem, yielding better results than prior handcrafted models. Numerous deep learning-based VQA models have been developed, with progress in this direction driven by the creation of content-diverse, large-scale human-labeled databases that supply ground truth psychometric video quality data. Here, we present a comprehensive survey of recent progress in the development of VQA algorithms and the benchmarking studies and databases that make them possible. We also analyze open research directions on study design and VQA algorithm architectures.