 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASAP: Accurate semantic segmentation for real time performance
Paper and Code
Oct 04, 2022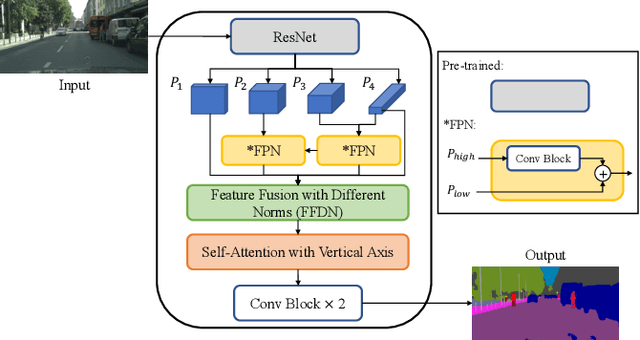
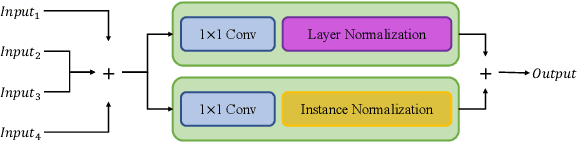
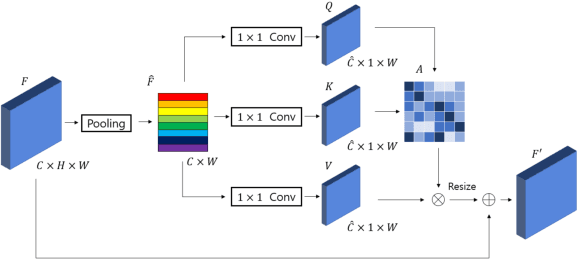

Feature fusion modules from encoder and self-attention module have been adopted in semantic segmentation. However, the computation of these modules is costly and has operational limitations in real-time environments. In addition, segmentation performance is limited in autonomous driving environments with a lot of contextual information perpendicular to the road surface, such as people, buildings, and general objects. In this paper, we propose an efficient feature fusion method, Feature Fusion with Different Norms (FFDN) that utilizes rich global context of multi-level scale and vertical pooling module before self-attention that preserves most contextual information while reducing the complexity of global context encoding in the vertical direction. By doing this, we could handle the properties of representation in global space and reduce additional computational cost. In addition, we analyze low performance in challenging cases including small and vertically featured objects. We achieve the mean Interaction of-union(mIoU) of 73.1 and the Frame Per Second(FPS) of 191, which are comparable results with state-of-the-arts on Cityscapes test datasets.