 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Unlearning: Efficient Node Removal in Graph Neural Networks
Sep 05, 2025With increasing concerns about privacy attacks and potential sensitive information leakage, researchers have actively explored methods to efficiently remove sensitive training data and reduce privacy risks in graph neural network (GNN) models. Node unlearning has emerged as a promising technique for protecting the privacy of sensitive nodes by efficiently removing specific training node information from GNN models. However, existing node unlearning methods either impose restrictions on the GNN structure or do not effectively utilize the graph topology for node unlearning. Some methods even compromise the graph's topology, making it challenging to achieve a satisfactory performance-complexity trade-off. To address these issues and achieve efficient unlearning for training node removal in GNNs, we propose three novel node unlearning methods: Class-based Label Replacement, Topology-guided Neighbor Mean Posterior Probability, and Class-consistent Neighbor Node Filtering. Among these methods, Topology-guided Neighbor Mean Posterior Probability and Class-consistent Neighbor Node Filtering effectively leverage the topological features of the graph, resulting in more effective node unlearning. To validate the superiority of our proposed methods in node unlearning, we conducted experiments on three benchmark datasets. The evaluation criteria included model utility, unlearning utility, and unlearning efficiency. The experimental results demonstrate the utility and efficiency of the proposed methods and illustrate their superiority compared to state-of-the-art node unlearning methods. Overall, the proposed methods efficiently remove sensitive training nodes and protect the privacy information of sensitive nodes in GNNs. The findings contribute to enhancing the privacy and security of GNN models and provide valuable insights into the field of node unlearning.
Large Language Models Merging for Enhancing the Link Stealing Attack on Graph Neural Networks
Dec 08, 2024



Graph Neural Networks (GNNs), specifically designed to process the graph data, have achieved remarkable success in various applications. Link stealing attacks on graph data pose a significant privacy threat, as attackers aim to extract sensitive relationships between nodes (entities), potentially leading to academic misconduct, fraudulent transactions, or other malicious activities. Previous studies have primarily focused on single datasets and did not explore cross-dataset attacks, let alone attacks that leverage the combined knowledge of multiple attackers. However, we find that an attacker can combine the data knowledge of multiple attackers to create a more effective attack model, which can be referred to cross-dataset attacks. Moreover, if knowledge can be extracted with the help of Large Language Models (LLMs), the attack capability will be more significant. In this paper, we propose a novel link stealing attack method that takes advantage of cross-dataset and Large Language Models (LLMs). The LLM is applied to process datasets with different data structures in cross-dataset attacks. Each attacker fine-tunes the LLM on their specific dataset to generate a tailored attack model. We then introduce a novel model merging method to integrate the parameters of these attacker-specific models effectively. The result is a merged attack model with superior generalization capabilities, enabling effective attacks not only on the attackers' datasets but also on previously unseen (out-of-domain) datasets. We conducted extensive experiments in four datasets to demonstrate the effectiveness of our method. Additional experiments with three different GNN and LLM architectures further illustrate the generality of our approach.
Large Language Models for Link Stealing Attacks Against Graph Neural Networks
Jun 22, 2024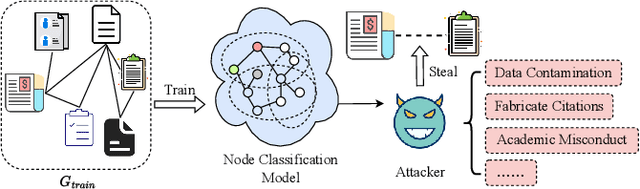



Graph data contains rich node features and unique edge information, which have been applied across various domains, such as citation networks or recommendation systems. Graph Neural Networks (GNNs) are specialized for handling such data and have shown impressive performance in many applications. However, GNNs may contain of sensitive information and susceptible to privacy attacks. For example, link stealing is a type of attack in which attackers infer whether two nodes are linked or not. Previous link stealing attacks primarily relied on posterior probabilities from the target GNN model, neglecting the significance of node features. Additionally, variations in node classes across different datasets lead to different dimensions of posterior probabilities. The handling of these varying data dimensions posed a challenge in using a single model to effectively conduct link stealing attacks on different datasets. To address these challenges, we introduce Large Language Models (LLMs) to perform link stealing attacks on GNNs. LLMs can effectively integrate textual features and exhibit strong generalizability, enabling attacks to handle diverse data dimensions across various datasets. We design two distinct LLM prompts to effectively combine textual features and posterior probabilities of graph nodes. Through these designed prompts, we fine-tune the LLM to adapt to the link stealing attack task. Furthermore, we fine-tune the LLM using multiple datasets and enable the LLM to learn features from different datasets simultaneously. Experimental results show that our approach significantly enhances the performance of existing link stealing attack tasks in both white-box and black-box scenarios. Our method can execute link stealing attacks across different datasets using only a single model, making link stealing attacks more applicable to real-world scenarios.