 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCC-MLLM-CoT-Alpha: Towards Multi-stage Occlusion Recognition Based on Large Language Models via 3D-Aware Supervision and Chain-of-Thoughts Guidance
Apr 07, 2025


Comprehending occluded objects are not well studied in existing large-scale visual-language multi-modal models. Current state-of-the-art multi-modal large models struggles to provide satisfactory results in understanding occluded objects through universal visual encoders and supervised learning strategies. Therefore, we propose OCC-MLLM-CoT-Alpha, a multi-modal large vision language framework that integrates 3D-aware supervision and Chain-of-Thoughts guidance. Particularly, (1) we build a multi-modal large vision-language model framework which is consisted of a large multi-modal vision-language model and a 3D reconstruction expert model. (2) the corresponding multi-modal Chain-of-Thoughts is learned through a combination of supervised and reinforcement training strategies, allowing the multi-modal vision-language model to enhance the recognition ability with learned multi-modal chain-of-thoughts guidance. (3) A large-scale multi-modal chain-of-thoughts reasoning dataset, consisting of $110k$ samples of occluded objects held in hand, is built. In the evaluation, the proposed methods demonstrate decision score improvement of 15.75%,15.30%,16.98%,14.62%, and 4.42%,3.63%,6.94%,10.70% for two settings of a variety of state-of-the-art models.
Training Deep Neural Networks for Wireless Sensor Networks Using Loosely and Weakly Labeled Images
Oct 06, 2020
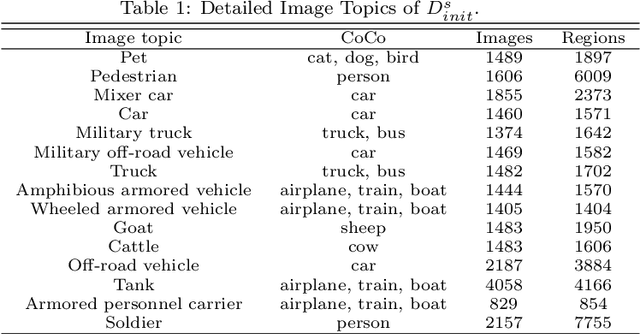
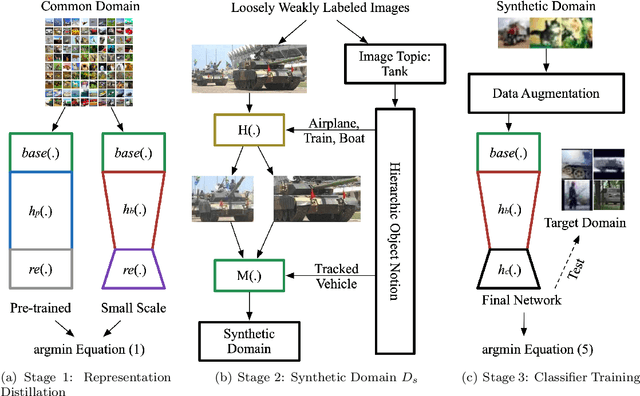

Although deep learning has achieved remarkable successes over the past years, few reports have been published about applying deep neural networks to Wireless Sensor Networks (WSNs) for image targets recognition where data, energy, computation resources are limited. In this work, a Cost-Effective Domain Generalization (CEDG) algorithm has been proposed to train an efficient network with minimum labor requirements. CEDG transfers networks from a publicly available source domain to an application-specific target domain through an automatically allocated synthetic domain. The target domain is isolated from parameters tuning and used for model selection and testing only. The target domain is significantly different from the source domain because it has new target categories and is consisted of low-quality images that are out of focus, low in resolution, low in illumination, low in photographing angle. The trained network has about 7M (ResNet-20 is about 41M) multiplications per prediction that is small enough to allow a digital signal processor chip to do real-time recognitions in our WSN. The category-level averaged error on the unseen and unbalanced target domain has been decreased by 41.12%.