 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Neural Deformation for Multi-View Face Reconstruction
Paper and Code
Dec 05, 2021


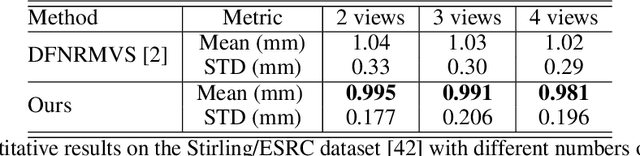
In this work, we present a new method for 3D face reconstruction from multi-view RGB images. Unlike previous methods which are built upon 3D morphable models (3DMMs) with limited details, our method leverages an implicit representation to encode rich geometric features. Our overall pipeline consists of two major components, including a geometry network, which learns a deformable neural signed distance function (SDF) as the 3D face representation, and a rendering network, which learns to render on-surface points of the neural SDF to match the input images via self-supervised optimization. To handle in-the-wild sparse-view input of the same target with different expressions at test time, we further propose residual latent code to effectively expand the shape space of the learned implicit face representation, as well as a novel view-switch loss to enforce consistency among different views. Our experimental results on several benchmark datasets demonstrate that our approach outperforms alternative baselines and achieves superior face reconstruction results compared to state-of-the-art methods.