 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Adapter for Vision-Language Models
Sep 03, 2024



Large pre-trained vision-language models, such as CLIP, have demonstrated state-of-the-art performance across a wide range of image classification tasks, without requiring retraining. Few-shot CLIP is competitive with existing specialized architectures that were trained on the downstream tasks. Recent research demonstrates that the performance of CLIP can be further improved using lightweight adaptation approaches. However, previous methods adapt different modalities of the CLIP model individually, ignoring the interactions and relationships between visual and textual representations. In this work, we propose Multi-Modal Adapter, an approach for Multi-Modal adaptation of CLIP. Specifically, we add a trainable Multi-Head Attention layer that combines text and image features to produce an additive adaptation of both. Multi-Modal Adapter demonstrates improved generalizability, based on its performance on unseen classes compared to existing adaptation methods. We perform additional ablations and investigations to validate and interpret the proposed approach.
HyNNA: Improved Performance for Neuromorphic Vision Sensor based Surveillance using Hybrid Neural Network Architecture
Mar 19, 2020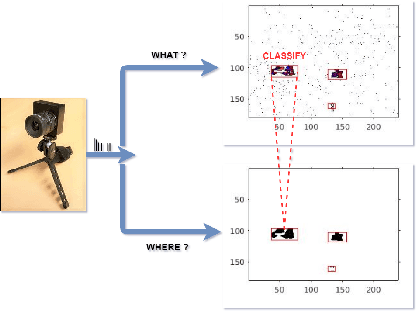
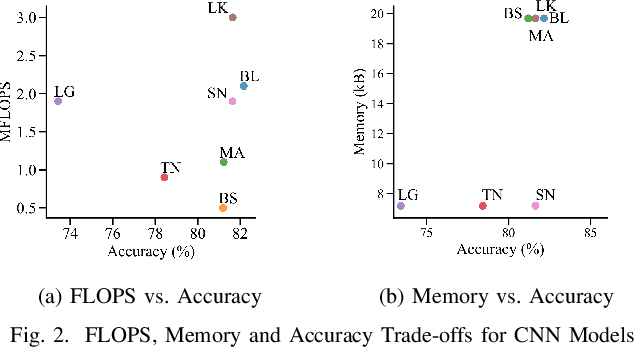
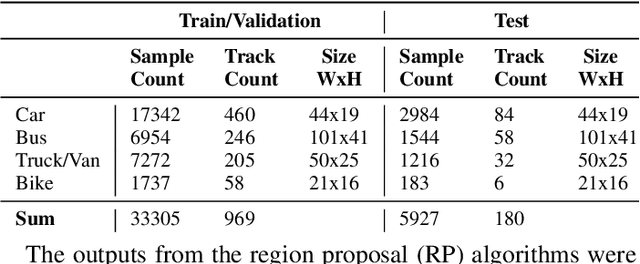

Applications in the Internet of Video Things (IoVT) domain have very tight constraints with respect to power and area. While neuromorphic vision sensors (NVS) may offer advantages over traditional imagers in this domain, the existing NVS systems either do not meet the power constraints or have not demonstrated end-to-end system performance. To address this, we improve on a recently proposed hybrid event-frame approach by using morphological image processing algorithms for region proposal and address the low-power requirement for object detection and classification by exploring various convolutional neural network (CNN) architectures. Specifically, we compare the results obtained from our object detection framework against the state-of-the-art low-power NVS surveillance system and show an improved accuracy of 82.16% from 63.1%. Moreover, we show that using multiple bits does not improve accuracy, and thus, system designers can save power and area by using only single bit event polarity information. In addition, we explore the CNN architecture space for object classification and show useful insights to trade-off accuracy for lower power using lesser memory and arithmetic operations.
Convolutional Neural Networks In Classifying Cancer Through DNA Methylation
Jul 24, 2018



DNA Methylation has been the most extensively studied epigenetic mark. Usually a change in the genotype, DNA sequence, leads to a change in the phenotype, observable characteristics of the individual. But DNA methylation, which happens in the context of CpG (cytosine and guanine bases linked by phosphate backbone) dinucleotides, does not lead to a change in the original DNA sequence but has the potential to change the phenotype. DNA methylation is implicated in various biological processes and diseases including cancer. Hence there is a strong interest in understanding the DNA methylation patterns across various epigenetic related ailments in order to distinguish and diagnose the type of disease in its early stages. In this work, the relationship between methylated versus unmethylated CpG regions and cancer types is explored using Convolutional Neural Networks (CNNs). A CNN based Deep Learning model that can classify the cancer of a new DNA methylation profile based on the learning from publicly available DNA methylation datasets is then proposed.