 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSKDCGN: Source-free Knowledge Distillation of Counterfactual Generative Networks using cGANs
Aug 10, 2022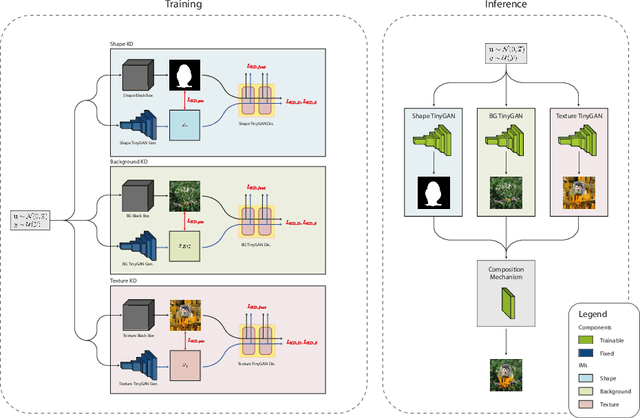


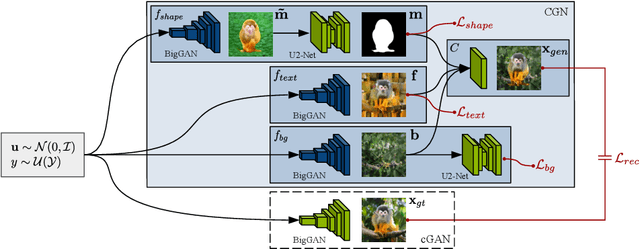
With the usage of appropriate inductive biases, Counterfactual Generative Networks (CGNs) can generate novel images from random combinations of shape, texture, and background manifolds. These images can be utilized to train an invariant classifier, avoiding the wide spread problem of deep architectures learning spurious correlations rather than meaningful ones. As a consequence, out-of-domain robustness is improved. However, the CGN architecture comprises multiple over parameterized networks, namely BigGAN and U2-Net. Training these networks requires appropriate background knowledge and extensive computation. Since one does not always have access to the precise training details, nor do they always possess the necessary knowledge of counterfactuals, our work addresses the following question: Can we use the knowledge embedded in pre-trained CGNs to train a lower-capacity model, assuming black-box access (i.e., only access to the pretrained CGN model) to the components of the architecture? In this direction, we propose a novel work named SKDCGN that attempts knowledge transfer using Knowledge Distillation (KD). In our proposed architecture, each independent mechanism (shape, texture, background) is represented by a student 'TinyGAN' that learns from the pretrained teacher 'BigGAN'. We demonstrate the efficacy of the proposed method using state-of-the-art datasets such as ImageNet, and MNIST by using KD and appropriate loss functions. Moreover, as an additional contribution, our paper conducts a thorough study on the composition mechanism of the CGNs, to gain a better understanding of how each mechanism influences the classification accuracy of an invariant classifier. Code available at: https://github.com/ambekarsameer96/SKDCGN