 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypical Progressive Alignment and Reweighting for Generalizable Semantic Segmentation
Jul 16, 2025



Generalizable semantic segmentation aims to perform well on unseen target domains, a critical challenge due to real-world applications requiring high generalizability. Class-wise prototypes, representing class centroids, serve as domain-invariant cues that benefit generalization due to their stability and semantic consistency. However, this approach faces three challenges. First, existing methods often adopt coarse prototypical alignment strategies, which may hinder performance. Second, naive prototypes computed by averaging source batch features are prone to overfitting and may be negatively affected by unrelated source data. Third, most methods treat all source samples equally, ignoring the fact that different features have varying adaptation difficulties. To address these limitations, we propose a novel framework for generalizable semantic segmentation: Prototypical Progressive Alignment and Reweighting (PPAR), leveraging the strong generalization ability of the CLIP model. Specifically, we define two prototypes: the Original Text Prototype (OTP) and Visual Text Prototype (VTP), generated via CLIP to serve as a solid base for alignment. We then introduce a progressive alignment strategy that aligns features in an easy-to-difficult manner, reducing domain gaps gradually. Furthermore, we propose a prototypical reweighting mechanism that estimates the reliability of source data and adjusts its contribution, mitigating the effect of irrelevant or harmful features (i.e., reducing negative transfer). We also provide a theoretical analysis showing the alignment between our method and domain generalization theory. Extensive experiments across multiple benchmarks demonstrate that PPAR achieves state-of-the-art performance, validating its effectiveness.
Depth-Sensitive Soft Suppression with RGB-D Inter-Modal Stylization Flow for Domain Generalization Semantic Segmentation
May 11, 2025

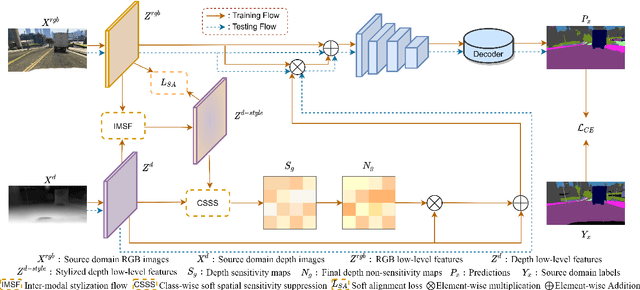
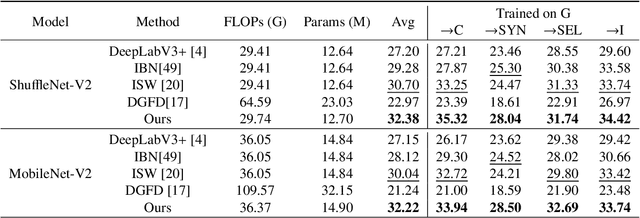
Unsupervised Domain Adaptation (UDA) aims to align source and target domain distributions to close the domain gap, but still struggles with obtaining the target data. Fortunately, Domain Generalization (DG) excels without the need for any target data. Recent works expose that depth maps contribute to improved generalized performance in the UDA tasks, but they ignore the noise and holes in depth maps due to device and environmental factors, failing to sufficiently and effectively learn domain-invariant representation. Although high-sensitivity region suppression has shown promising results in learning domain-invariant features, existing methods cannot be directly applicable to depth maps due to their unique characteristics. Hence, we propose a novel framework, namely Depth-Sensitive Soft Suppression with RGB-D inter-modal stylization flow (DSSS), focusing on learning domain-invariant features from depth maps for the DG semantic segmentation. Specifically, we propose the RGB-D inter-modal stylization flow to generate stylized depth maps for sensitivity detection, cleverly utilizing RGB information as the stylization source. Then, a class-wise soft spatial sensitivity suppression is designed to identify and emphasize non-sensitive depth features that contain more domain-invariant information. Furthermore, an RGB-D soft alignment loss is proposed to ensure that the stylized depth maps only align part of the RGB features while still retaining the unique depth information. To our best knowledge, our DSSS framework is the first work to integrate RGB and Depth information in the multi-class DG semantic segmentation task. Extensive experiments over multiple backbone networks show that our framework achieves remarkable performance improvement.
Evaluating Human Perception of Novel View Synthesis: Subjective Quality Assessment of Gaussian Splatting and NeRF in Dynamic Scenes
Jan 13, 2025Gaussian Splatting (GS) and Neural Radiance Fields (NeRF) are two groundbreaking technologies that have revolutionized the field of Novel View Synthesis (NVS), enabling immersive photorealistic rendering and user experiences by synthesizing multiple viewpoints from a set of images of sparse views. The potential applications of NVS, such as high-quality virtual and augmented reality, detailed 3D modeling, and realistic medical organ imaging, underscore the importance of quality assessment of NVS methods from the perspective of human perception. Although some previous studies have explored subjective quality assessments for NVS technology, they still face several challenges, especially in NVS methods selection, scenario coverage, and evaluation methodology. To address these challenges, we conducted two subjective experiments for the quality assessment of NVS technologies containing both GS-based and NeRF-based methods, focusing on dynamic and real-world scenes. This study covers 360{\deg}, front-facing, and single-viewpoint videos while providing a richer and greater number of real scenes. Meanwhile, it's the first time to explore the impact of NVS methods in dynamic scenes with moving objects. The two types of subjective experiments help to fully comprehend the influences of different viewing paths from a human perception perspective and pave the way for future development of full-reference and no-reference quality metrics. In addition, we established a comprehensive benchmark of various state-of-the-art objective metrics on the proposed database, highlighting that existing methods still struggle to accurately capture subjective quality. The results give us some insights into the limitations of existing NVS methods and may promote the development of new NVS methods.
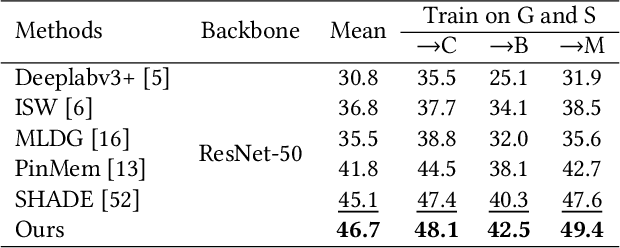
Calibration-based Dual Prototypical Contrastive Learning Approach for Domain Generalization Semantic Segmentation
Sep 25, 2023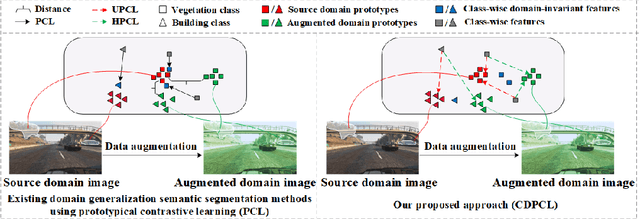
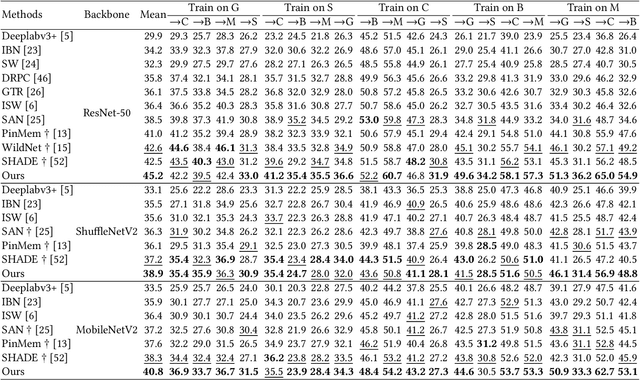
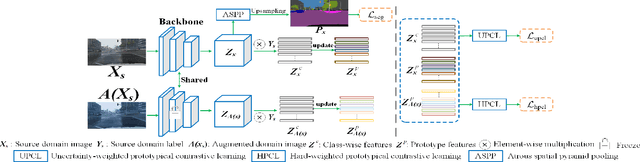
Prototypical contrastive learning (PCL) has been widely used to learn class-wise domain-invariant features recently. These methods are based on the assumption that the prototypes, which are represented as the central value of the same class in a certain domain, are domain-invariant. Since the prototypes of different domains have discrepancies as well, the class-wise domain-invariant features learned from the source domain by PCL need to be aligned with the prototypes of other domains simultaneously. However, the prototypes of the same class in different domains may be different while the prototypes of different classes may be similar, which may affect the learning of class-wise domain-invariant features. Based on these observations, a calibration-based dual prototypical contrastive learning (CDPCL) approach is proposed to reduce the domain discrepancy between the learned class-wise features and the prototypes of different domains for domain generalization semantic segmentation. It contains an uncertainty-guided PCL (UPCL) and a hard-weighted PCL (HPCL). Since the domain discrepancies of the prototypes of different classes may be different, we propose an uncertainty probability matrix to represent the domain discrepancies of the prototypes of all the classes. The UPCL estimates the uncertainty probability matrix to calibrate the weights of the prototypes during the PCL. Moreover, considering that the prototypes of different classes may be similar in some circumstances, which means these prototypes are hard-aligned, the HPCL is proposed to generate a hard-weighted matrix to calibrate the weights of the hard-aligned prototypes during the PCL. Extensive experiments demonstrate that our approach achieves superior performance over current approaches on domain generalization semantic segmentation tasks.
A Class-wise Non-salient Region Generalized Framework for Video Semantic Segmentation
Dec 29, 2022



Video semantic segmentation (VSS) is beneficial for dealing with dynamic scenes due to the continuous property of the real-world environment. On the one hand, some methods alleviate the predicted inconsistent problem between continuous frames. On the other hand, other methods employ the previous frame as the prior information to assist in segmenting the current frame. Although the previous methods achieve superior performances on the independent and identically distributed (i.i.d) data, they can not generalize well on other unseen domains. Thus, we explore a new task, the video generalizable semantic segmentation (VGSS) task that considers both continuous frames and domain generalization. In this paper, we propose a class-wise non-salient region generalized (CNSG) framework for the VGSS task. Concretely, we first define the class-wise non-salient feature, which describes features of the class-wise non-salient region that carry more generalizable information. Then, we propose a class-wise non-salient feature reasoning strategy to select and enhance the most generalized channels adaptively. Finally, we propose an inter-frame non-salient centroid alignment loss to alleviate the predicted inconsistent problem in the VGSS task. We also extend our video-based framework to the image-based generalizable semantic segmentation (IGSS) task. Experiments demonstrate that our CNSG framework yields significant improvement in the VGSS and IGSS tasks.
SAIS: Single-stage Anchor-free Instance Segmentation
Dec 03, 2019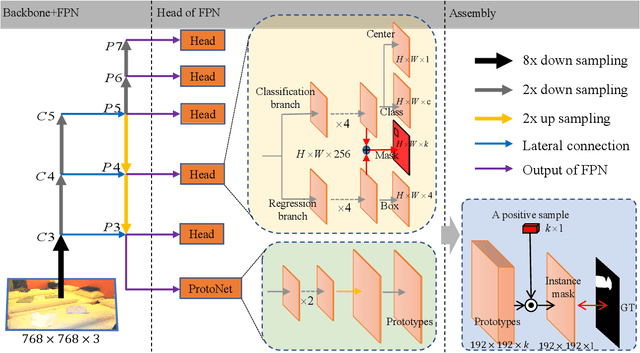
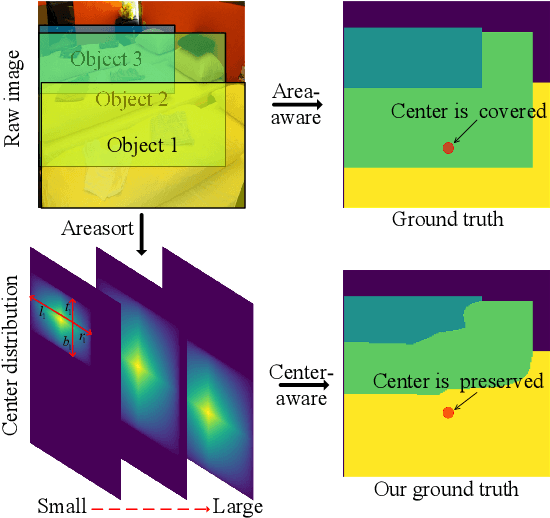

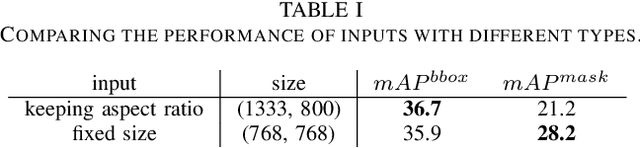
In this paper, we propose a simple yet efficientinstance segmentation approach based on the single-stage anchor-free detector, termed SAIS. In our approach, the instancesegmentation task consists of two parallel subtasks which re-spectively predict the mask coefficients and the mask prototypes.Then, instance masks are generated by linearly combining theprototypes with the mask coefficients. To enhance the quality ofinstance mask, the information from regression and classificationis fused to predict the mask coefficients. In addition, center-aware target is designed to preserve the center coordination ofeach instance, which achieves a stable improvement in instancesegmentation. The experiment on MS COCO shows that SAISachieves the performance of the exiting state-of-the-art single-stage methods with a much less memory footpr
Quality Assessment of DIBR-synthesized views: An Overview
Nov 16, 2019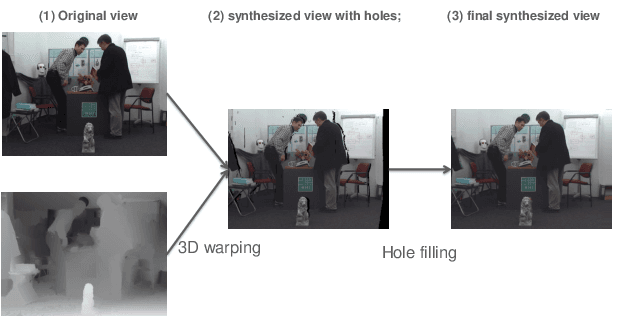
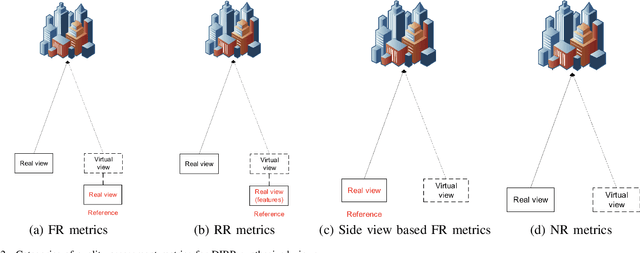
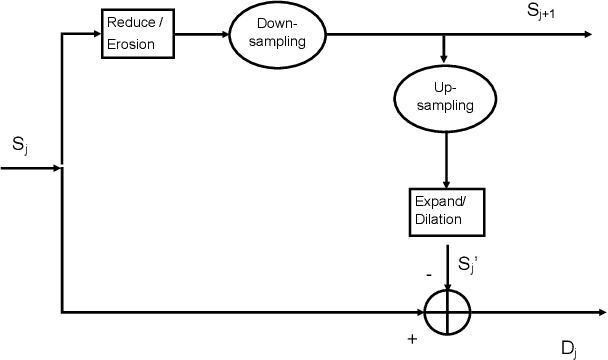
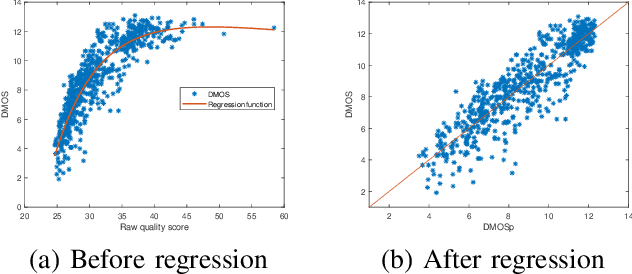
The Depth-Image-Based-Rendering (DIBR) is one of the main fundamental technique to generate new views in 3D video applications, such as Multi-View Videos (MVV), Free-Viewpoint Videos (FVV) and Virtual Reality (VR). However, the quality assessment of DIBR-synthesized views is quite different from the traditional 2D images/videos. In recent years, several efforts have been made towards this topic, but there lacks a detailed survey in literature. In this paper, we provide a comprehensive survey on various current approaches for DIBR-synthesized views. The current accessible datasets of DIBR-synthesized views are firstly reviewed. Followed by a summary and analysis of the representative state-of-the-art objective metrics. Then, the performances of different objective metrics are evaluated and discussed on all available datasets. Finally, we discuss the potential challenges and suggest possible directions for future research.