 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Deep Learning Based Adversarial Defense for Automatic Modulation Classification
Sep 19, 2025Deep learning (DL) has been widely applied to enhance automatic modulation classification (AMC). However, the elaborate AMC neural networks are susceptible to various adversarial attacks, which are challenging to handle due to the generalization capability and computational cost. In this article, an explainable DL based defense scheme, called SHapley Additive exPlanation enhanced Adversarial Fine-Tuning (SHAP-AFT), is developed in the perspective of disclosing the attacking impact on the AMC network. By introducing the concept of cognitive negative information, the motivation of using SHAP for defense is theoretically analyzed first. The proposed scheme includes three stages, i.e., the attack detection, the information importance evaluation, and the AFT. The first stage indicates the existence of the attack. The second stage evaluates contributions of the received data and removes those data positions using negative Shapley values corresponding to the dominating negative information caused by the attack. Then the AMC network is fine-tuned based on adversarial adaptation samples using the refined received data pattern. Simulation results show the effectiveness of the Shapley value as the key indicator as well as the superior defense performance of the proposed SHAP-AFT scheme in face of different attack types and intensities.
Pruned Convolutional Attention Network Based Wideband Spectrum Sensing with Sub-Nyquist Sampling
Nov 30, 2024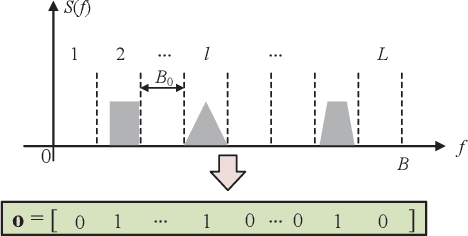
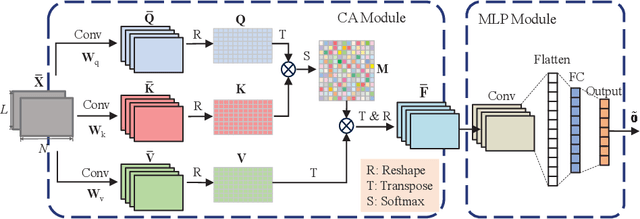
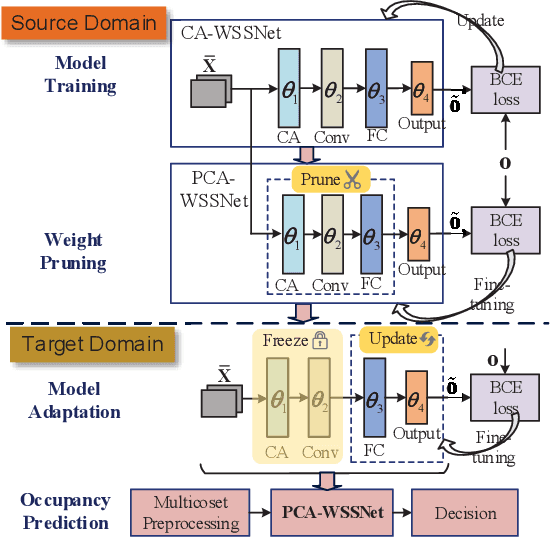
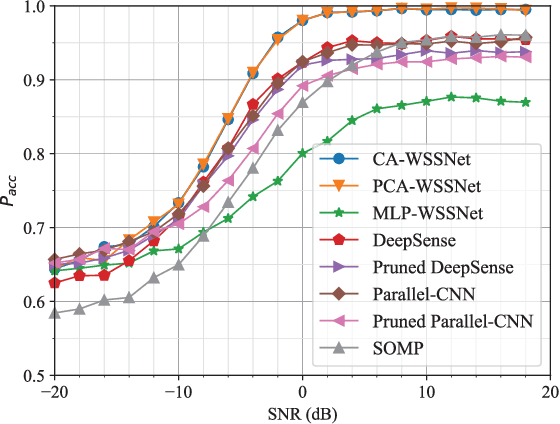
Wideband spectrum sensing (WSS) is critical for orchestrating multitudinous wireless transmissions via spectrum sharing, but may incur excessive costs of hardware, power and computation due to the high sampling rate. In this article, a deep learning based WSS framework embedding the multicoset preprocessing is proposed to enable the low-cost sub-Nyquist sampling. A pruned convolutional attention WSS network (PCA-WSSNet) is designed to organically integrate the multicoset preprocessing and the convolutional attention mechanism as well as to reduce the model complexity remarkably via the selective weight pruning without the performance loss. Furthermore, a transfer learning (TL) strategy benefiting from the model pruning is developed to improve the robustness of PCA-WSSNet with few adaptation samples of new scenarios. Simulation results show the performance superiority of PCA-WSSNet over the state of the art. Compared with direct TL, the pruned TL strategy can simultaneously improve the prediction accuracy in unseen scenarios, reduce the model size, and accelerate the model inference.
Mixed Attention Transformer Enhanced Channel Estimation for Extremely Large-Scale MIMO Systems
Oct 18, 2024Extremely large-scale massive multiple-input multiple-output (XL-MIMO) is one of the key technologies for next-generation wireless communication systems. However, acquiring the accurate high-dimensional channel matrix of XL-MIMO remains a pressing challenge due to the intractable channel property and the high complexity. In this paper, a Mixed Attention Transformer based Channel Estimation Neural Network (MAT-CENet) is developed, which is inspired by the Transformer encoder structure as well as organically integrates the feature map attention and spatial attention mechanisms to better grasp the unique characteristics of the XL-MIMO channel. By incorporating the multi-head attention layer as the core enabler, the insightful feature importance is captured and exploited effectively. A comprehensive complexity analysis for the proposed MAT-CENet is also provided. Simulation results show that MAT-CENet outperforms the state of the art in different propagation scenarios of near-, far- and hybrid-fields.
Information Importance-Aware Defense against Adversarial Attack for Automatic Modulation Classification:An XAI-Based Approach
Oct 15, 2024



Deep learning (DL) has significantly improved automatic modulation classification (AMC) by leveraging neural networks as the feature extractor.However, as the DL-based AMC becomes increasingly widespread, it is faced with the severe secure issue from various adversarial attacks. Existing defense methods often suffer from the high computational cost, intractable parameter tuning, and insufficient robustness.This paper proposes an eXplainable artificial intelligence (XAI) defense approach, which uncovers the negative information caused by the adversarial attack through measuring the importance of input features based on the SHapley Additive exPlanations (SHAP).By properly removing the negative information in adversarial samples and then fine-tuning(FT) the model, the impact of the attacks on the classification result can be mitigated.Experimental results demonstrate that the proposed SHAP-FT improves the classification performance of the model by 15%-20% under different attack levels,which not only enhances model robustness against various attack levels but also reduces the resource consumption, validating its effectiveness in safeguarding communication networks.
Collaborative Automatic Modulation Classification via Deep Edge Inference for Hierarchical Cognitive Radio Networks
Sep 12, 2024



In hierarchical cognitive radio networks, edge or cloud servers utilize the data collected by edge devices for modulation classification, which, however, is faced with problems of the transmission overhead, data privacy, and computation load. In this article, an edge learning (EL) based framework jointly mobilizing the edge device and the edge server for intelligent co-inference is proposed to realize the collaborative automatic modulation classification (C-AMC) between them. A spectrum semantic compression neural network (SSCNet) with the lightweight structure is designed for the edge device to compress the collected raw data into a compact semantic message that is then sent to the edge server via the wireless channel. On the edge server side, a modulation classification neural network (MCNet) combining bidirectional long short-term memory (Bi?LSTM) and multi-head attention layers is elaborated to deter?mine the modulation type from the noisy semantic message. By leveraging the computation resources of both the edge device and the edge server, high transmission overhead and risks of data privacy leakage are avoided. The simulation results verify the effectiveness of the proposed C-AMC framework, significantly reducing the model size and computational complexity.
Federated Transfer Learning Based Cooperative Wideband Spectrum Sensing with Model Pruning
Sep 09, 2024



For ultra-wideband and high-rate wireless communication systems, wideband spectrum sensing (WSS) is critical, since it empowers secondary users (SUs) to capture the spectrum holes for opportunistic transmission. However, WSS encounters challenges such as excessive costs of hardware and computation due to the high sampling rate, as well as robustness issues arising from scenario mismatch. In this paper, a WSS neural network (WSSNet) is proposed by exploiting multicoset preprocessing to enable the sub-Nyquist sampling, with the two dimensional convolution design specifically tailored to work with the preprocessed samples. A federated transfer learning (FTL) based framework mobilizing multiple SUs is further developed to achieve a robust model adaptable to various scenarios, which is paved by the selective weight pruning for the fast model adaptation and inference. Simulation results demonstrate that the proposed FTL-WSSNet achieves the fairly good performance in different target scenarios even without local adaptation samples.
Edge Learning Based Collaborative Automatic Modulation Classification for Hierarchical Cognitive Radio Networks
Jul 30, 2024In hierarchical cognitive radio networks, edge or cloud servers utilize the data collected by edge devices for modulation classification, which, however, is faced with problems of the computation load, transmission overhead, and data privacy. In this article, an edge learning (EL) based framework jointly mobilizing the edge device and the edge server for intelligent co-inference is proposed to realize the collaborative automatic modulation classification (C-AMC) between them. A spectrum semantic compression neural network is designed for the edge device to compress the collected raw data into a compact semantic embedding that is then sent to the edge server via the wireless channel. On the edge server side, a modulation classification neural network combining the bidirectional long-short term memory and attention structures is elaborated to determine the modulation type from the noisy semantic embedding. The C-AMC framework decently balances the computation resources of both sides while avoiding the high transmission overhead and data privacy leakage. Both the offline and online training procedures of the C-AMC framework are elaborated. The compression strategy of the C-AMC framework is also developed to further facilitate the deployment, especially for the resource-constrained edge device. Simulation results show the superiority of the EL-based C-AMC framework in terms of the classification accuracy, computational complexity, and the data compression rate as well as reveal useful insights paving the practical implementation.
Lightweight Deep Learning Based Channel Estimation for Extremely Large-Scale Massive MIMO Systems
Feb 14, 2024



Extremely large-scale massive multiple-input multiple-output (XL-MIMO) systems introduce the much higher channel dimensionality and incur the additional near-field propagation effect, aggravating the computation load and the difficulty to acquire the prior knowledge for channel estimation. In this article, an XL-MIMO channel network (XLCNet) is developed to estimate the high-dimensional channel, which is a universal solution for both the near-field users and far-field users with different channel statistics. Furthermore, a compressed XLCNet (C-XLCNet) is designed via weight pruning and quantization to accelerate the model inference as well as to facilitate the model storage and transmission. Simulation results show the performance superiority and universality of XLCNet. Compared to XLCNet, C-XLCNet incurs the limited performance loss while reducing the computational complexity and model size by about $10 \times$ and $36 \times$, respectively.
Edge Semantic Cognitive Intelligence for 6G Networks: Models, Framework, and Applications
May 24, 2022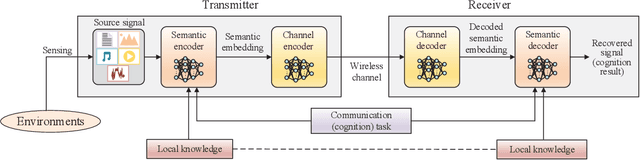
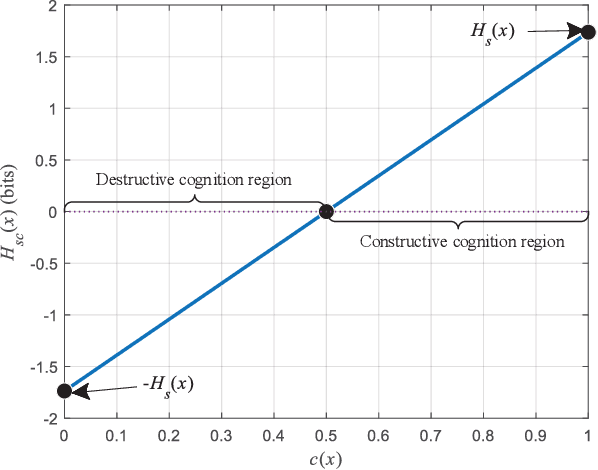
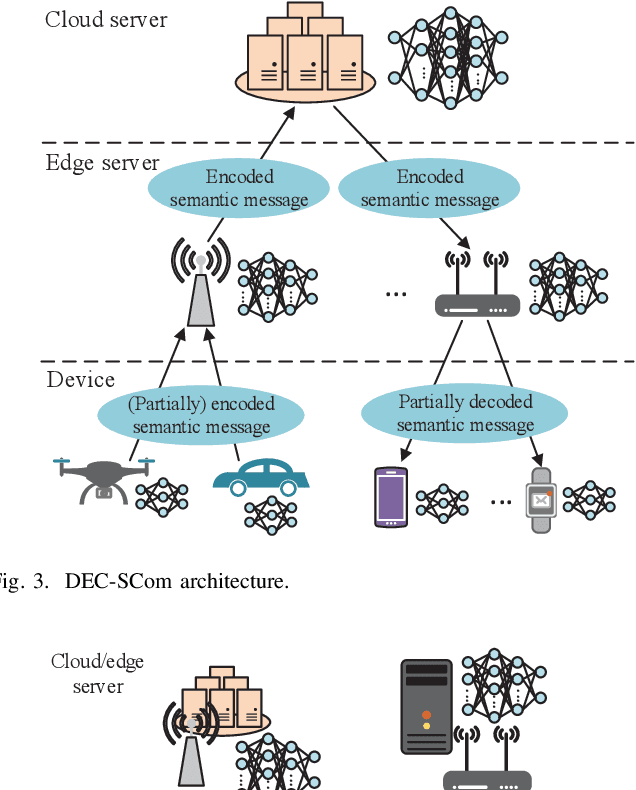
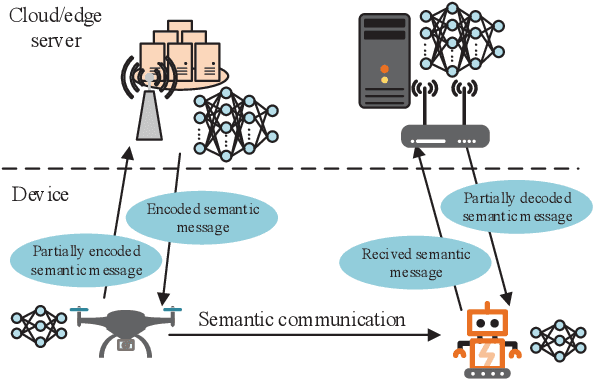
Edge intelligence is anticipated to underlay the pathway to connected intelligence for 6G networks, but the organic confluence of edge computing and artificial intelligence still needs to be carefully treated. To this end, this article discusses the concepts of edge intelligence from the semantic cognitive perspective. Two instructive theoretical models for edge semantic cognitive intelligence (ESCI) are first established. Afterwards, the ESCI framework orchestrating deep learning with semantic communication is discussed. Two representative applications are present to shed light on the prospect of ESCI in 6G networks. Some open problems are finally listed to elicit the future research directions of ESCI.
Deep Multi-Stage CSI Acquisition for Reconfigurable Intelligent Surface Aided MIMO Systems
Apr 23, 2021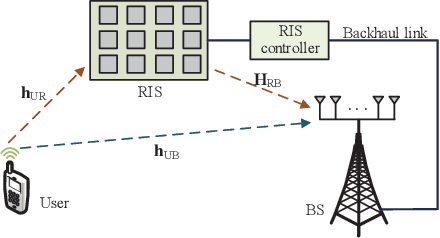
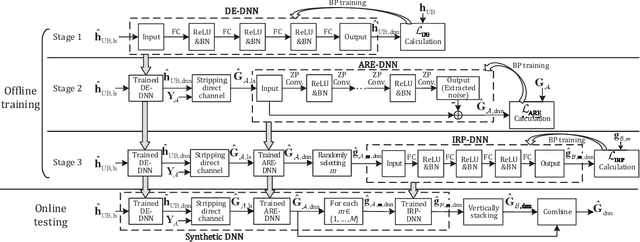
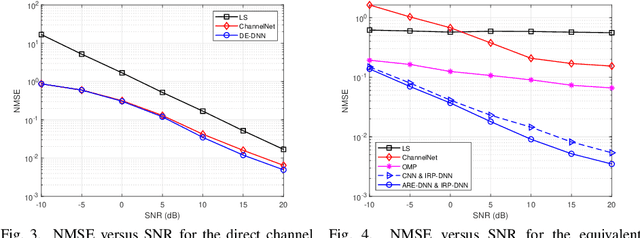
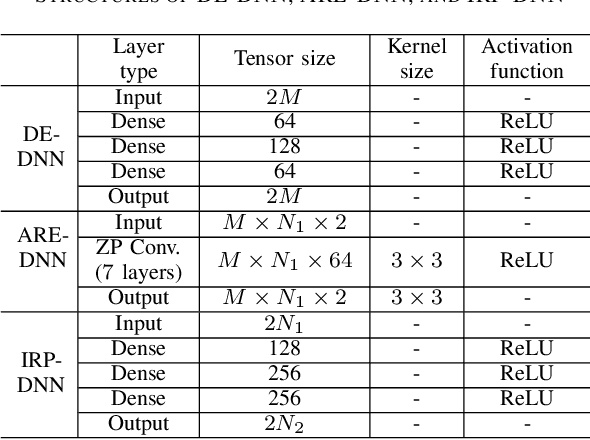
This article aims to reduce huge pilot overhead when estimating the reconfigurable intelligent surface (RIS) relayed wireless channel. Motivated by the compelling grasp of deep learning in tackling nonlinear mapping problems, the proposed approach only activates a part of RIS elements and utilizes the corresponding cascaded channel estimate to predict another part. Through a synthetic deep neural network (DNN), the direct channel and active cascaded channel are first estimated sequentially, followed by the channel prediction for the inactive RIS elements. A three-stage training strategy is developed for this synthetic DNN. From simulation results, the proposed deep learning based approach is effective in reducing the pilot overhead and guaranteeing the reliable estimation accuracy.