 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Segmentation without any Pixel-level Supervision with Application to Large-Scale Sketch Classification
Paper and Code
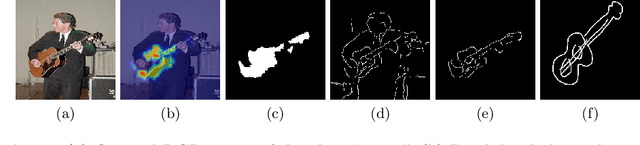
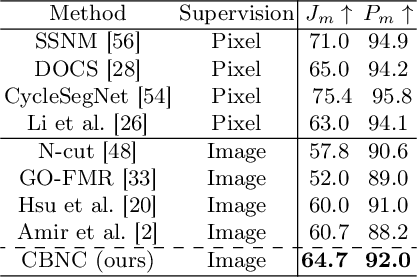
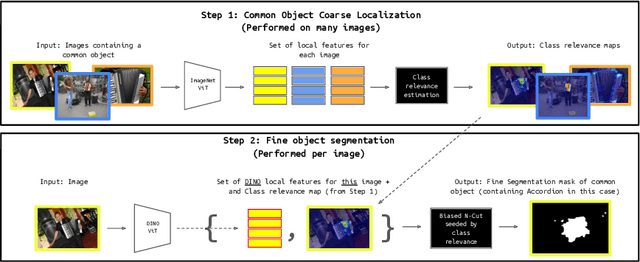
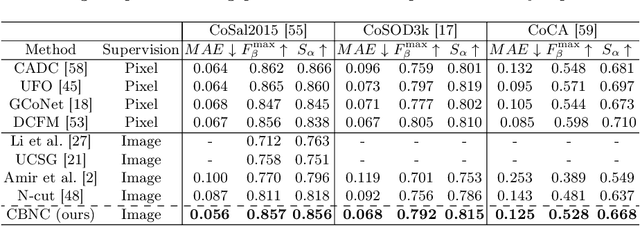
This work proposes a novel method for object co-segmentation, i.e. pixel-level localization of a common object in a set of images, that uses no pixel-level supervision for training. Two pre-trained Vision Transformer (ViT) models are exploited: ImageNet classification-trained ViT, whose features are used to estimate rough object localization through intra-class token relevance, and a self-supervised DINO-ViT for intra-image token relevance. On recent challenging benchmarks, the method achieves state-of-the-art performance among methods trained with the same level of supervision (image labels) while being competitive with methods trained with pixel-level supervision (binary masks). The benefits of the proposed co-segmentation method are further demonstrated in the task of large-scale sketch recognition, that is, the classification of sketches into a wide range of categories. The limited amount of hand-drawn sketch training data is leveraged by exploiting readily available image-level-annotated datasets of natural images containing a large number of classes. To bridge the domain gap, the classifier is trained on a sketch-like proxy domain derived from edges detected on natural images. We show that sketch recognition significantly benefits when the classifier is trained on sketch-like structures extracted from the co-segmented area rather than from the full image. Code: https://github.com/nikosips/CBNC .