 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Elicitation: Provision-based Prompt Optimization for Knowledge-Intensive Tasks
Nov 13, 2025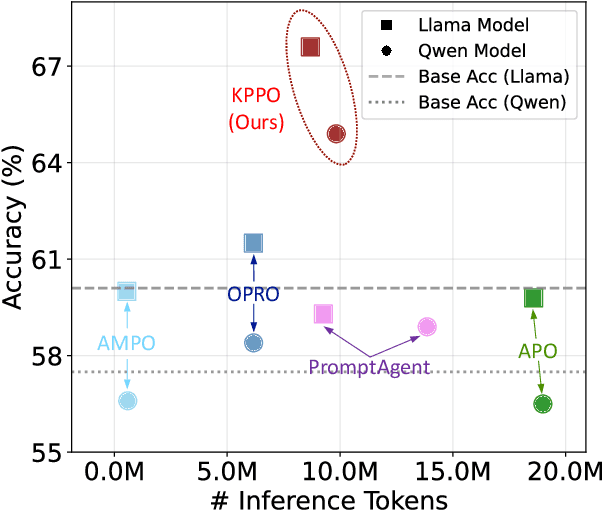



While prompt optimization has emerged as a critical technique for enhancing language model performance, existing approaches primarily focus on elicitation-based strategies that search for optimal prompts to activate models' capabilities. These methods exhibit fundamental limitations when addressing knowledge-intensive tasks, as they operate within fixed parametric boundaries rather than providing the factual knowledge, terminology precision, and reasoning patterns required in specialized domains. To address these limitations, we propose Knowledge-Provision-based Prompt Optimization (KPPO), a framework that reformulates prompt optimization as systematic knowledge integration rather than potential elicitation. KPPO introduces three key innovations: 1) a knowledge gap filling mechanism for knowledge gap identification and targeted remediation; 2) a batch-wise candidate evaluation approach that considers both performance improvement and distributional stability; 3) an adaptive knowledge pruning strategy that balances performance and token efficiency, reducing up to 29% token usage. Extensive evaluation on 15 knowledge-intensive benchmarks from various domains demonstrates KPPO's superiority over elicitation-based methods, with an average performance improvement of ~6% over the strongest baseline while achieving comparable or lower token consumption. Code at: https://github.com/xyz9911/KPPO.
UltraHR-100K: Enhancing UHR Image Synthesis with A Large-Scale High-Quality Dataset
Oct 23, 2025

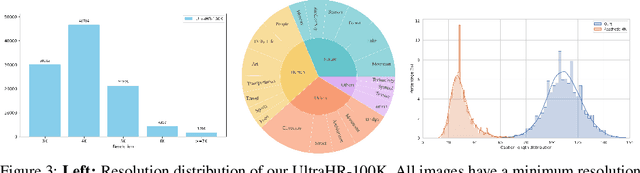
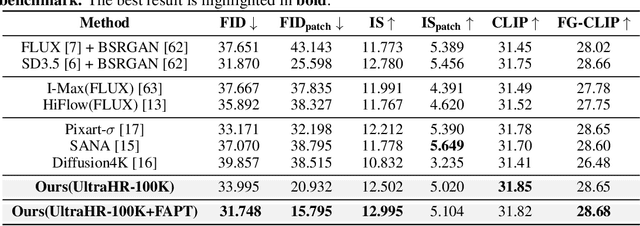
Ultra-high-resolution (UHR) text-to-image (T2I) generation has seen notable progress. However, two key challenges remain : 1) the absence of a large-scale high-quality UHR T2I dataset, and (2) the neglect of tailored training strategies for fine-grained detail synthesis in UHR scenarios. To tackle the first challenge, we introduce \textbf{UltraHR-100K}, a high-quality dataset of 100K UHR images with rich captions, offering diverse content and strong visual fidelity. Each image exceeds 3K resolution and is rigorously curated based on detail richness, content complexity, and aesthetic quality. To tackle the second challenge, we propose a frequency-aware post-training method that enhances fine-detail generation in T2I diffusion models. Specifically, we design (i) \textit{Detail-Oriented Timestep Sampling (DOTS)} to focus learning on detail-critical denoising steps, and (ii) \textit{Soft-Weighting Frequency Regularization (SWFR)}, which leverages Discrete Fourier Transform (DFT) to softly constrain frequency components, encouraging high-frequency detail preservation. Extensive experiments on our proposed UltraHR-eval4K benchmarks demonstrate that our approach significantly improves the fine-grained detail quality and overall fidelity of UHR image generation. The code is available at \href{https://github.com/NJU-PCALab/UltraHR-100k}{here}.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
From Zero to Detail: Deconstructing Ultra-High-Definition Image Restoration from Progressive Spectral Perspective
Mar 17, 2025Ultra-high-definition (UHD) image restoration faces significant challenges due to its high resolution, complex content, and intricate details. To cope with these challenges, we analyze the restoration process in depth through a progressive spectral perspective, and deconstruct the complex UHD restoration problem into three progressive stages: zero-frequency enhancement, low-frequency restoration, and high-frequency refinement. Building on this insight, we propose a novel framework, ERR, which comprises three collaborative sub-networks: the zero-frequency enhancer (ZFE), the low-frequency restorer (LFR), and the high-frequency refiner (HFR). Specifically, the ZFE integrates global priors to learn global mapping, while the LFR restores low-frequency information, emphasizing reconstruction of coarse-grained content. Finally, the HFR employs our designed frequency-windowed kolmogorov-arnold networks (FW-KAN) to refine textures and details, producing high-quality image restoration. Our approach significantly outperforms previous UHD methods across various tasks, with extensive ablation studies validating the effectiveness of each component. The code is available at \href{https://github.com/NJU-PCALab/ERR}{here}.
Planning from Imagination: Episodic Simulation and Episodic Memory for Vision-and-Language Navigation
Nov 30, 2024Humans navigate unfamiliar environments using the capabilities of episodic simulation and episodic memory. Developing imagination-based memory, analogous to episodic simulation and episodic memory, can enhance embodied agents' comprehension of the complex relationship between environments and objects. However, existing Vision-and-Language Navigation (VLN) agents fail to perform the aforementioned mechanism. We propose a novel architecture to help agents build a recurrent imaginative memory system. Specifically, the agent can maintain a reality-imagination hybrid global memory during navigation and expand the memory map through imaginative mechanisms and navigation actions. Correspondingly, we design a series of pre-training tasks to help the agent acquire fine-grained imaginative abilities. Our agents improve the state-of-the-art (SoTA) success rate (SR) by 7% while simultaneously imagining high-fidelity RGB representations for future scenes.
FLAME: Learning to Navigate with Multimodal LLM in Urban Environments
Aug 20, 2024Large Language Models (LLMs) have demonstrated potential in Vision-and-Language Navigation (VLN) tasks, yet current applications face challenges. While LLMs excel in general conversation scenarios, they struggle with specialized navigation tasks, yielding suboptimal performance compared to specialized VLN models. We introduce FLAME (FLAMingo-Architected Embodied Agent), a novel Multimodal LLM-based agent and architecture designed for urban VLN tasks that efficiently handles multiple observations. Our approach implements a three-phase tuning technique for effective adaptation to navigation tasks, including single perception tuning for street view description, multiple perception tuning for trajectory summarization, and end-to-end training on VLN datasets. The augmented datasets are synthesized automatically. Experimental results demonstrate FLAME's superiority over existing methods, surpassing state-of-the-art methods by a 7.3% increase in task completion rate on Touchdown dataset. This work showcases the potential of Multimodal LLMs (MLLMs) in complex navigation tasks, representing an advancement towards practical applications of MLLMs in embodied AI. Project page: https://flame-sjtu.github.io
HeroNet: A Hybrid Retrieval-Generation Network for Conversational Bots
Feb 08, 2023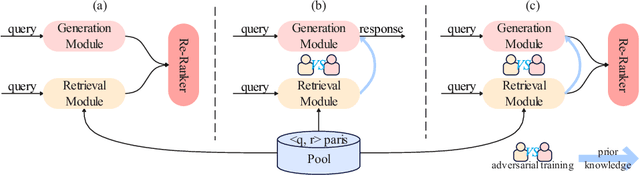

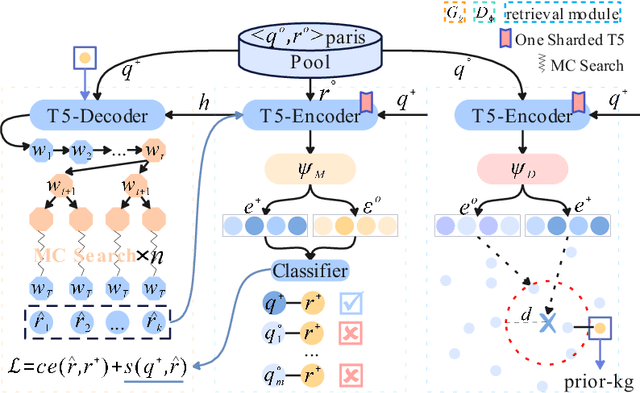
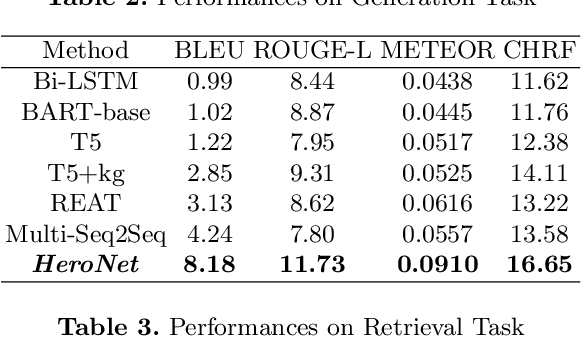
Using natural language, Conversational Bot offers unprecedented ways to many challenges in areas such as information searching, item recommendation, and question answering. Existing bots are usually developed through retrieval-based or generative-based approaches, yet both of them have their own advantages and disadvantages. To assemble this two approaches, we propose a hybrid retrieval-generation network (HeroNet) with the three-fold ideas: 1). To produce high-quality sentence representations, HeroNet performs multi-task learning on two subtasks: Similar Queries Discovery and Query-Response Matching. Specifically, the retrieval performance is improved while the model size is reduced by training two lightweight, task-specific adapter modules that share only one underlying T5-Encoder model. 2). By introducing adversarial training, HeroNet is able to solve both retrieval\&generation tasks simultaneously while maximizing performance of each other. 3). The retrieval results are used as prior knowledge to improve the generation performance while the generative result are scored by the discriminator and their scores are integrated into the generator's cross-entropy loss function. The experimental results on a open dataset demonstrate the effectiveness of the HeroNet and our code is available at https://github.com/TempHero/HeroNet.git
Requirements Elicitation in Cognitive Service for Recommendation
Mar 29, 2022

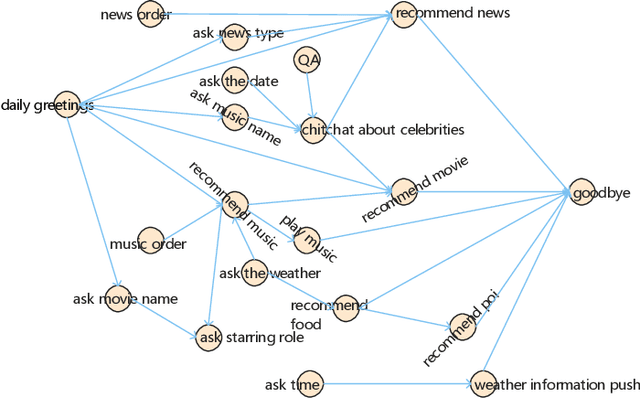
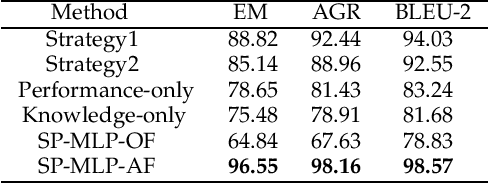
Nowadays, cognitive service provides more interactive way to understand users' requirements via human-machine conversation. In other words, it has to capture users' requirements from their utterance and respond them with the relevant and suitable service resources. To this end, two phases must be applied: I.Sequence planning and Real-time detection of user requirement, II.Service resource selection and Response generation. The existing works ignore the potential connection between these two phases. To model their connection, Two-Phase Requirement Elicitation Method is proposed. For the phase I, this paper proposes a user requirement elicitation framework (URef) to plan a potential requirement sequence grounded on user profile and personal knowledge base before the conversation. In addition, it can also predict user's true requirement and judge whether the requirement is completed based on the user's utterance during the conversation. For the phase II, this paper proposes a response generation model based on attention, SaRSNet. It can select the appropriate resource (i.e. knowledge triple) in line with the requirement predicted by URef, and then generates a suitable response for recommendation. The experimental results on the open dataset \emph{DuRecDial} have been significantly improved compared to the baseline, which proves the effectiveness of the proposed methods.