 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Unknown: Open Vocabulary Object Detection with Scene Graphs
Jun 04, 2026Open-vocabulary object detection seeks to identify novel object categories that were not part of the training data. Many knowledge distillation-based approaches have shown promising performance by transferring knowledge from pre-trained vision-language models to object detection. However, these methods often overlook structured, image-specific relationships between objects, such as interactions and spatial arrangements. This oversight can significantly restrict the effectiveness of detecting novel categories. To address this issue, we propose a Scene-guided Relational Modeling detection framework. This framework utilizes scene graphs to capture structured semantic and spatial relationships between candidate regions and their contextual objects. It explicitly models interactions among neighboring regions and incorporates a Relation Attention Module to implicitly amplify the key relational cues extracted from the scene graph. Furthermore, we present a scene-based textual alignment branch that distills category knowledge from captions to guide relational alignment. This approach facilitates a seamless integration of visual relations with semantic information for enhanced detection performance. Comprehensive experiments show that our model achieves superior performance compared to other OVOD methods, improving the AP for novel categories on COCO and LVIS datasets.
Breaking the Modality Wall: Time-step Mixup for Efficient Spiking Knowledge Transfer from Static to Event Domain
Nov 15, 2025The integration of event cameras and spiking neural networks (SNNs) promises energy-efficient visual intelligence, yet scarce event data and the sparsity of DVS outputs hinder effective training. Prior knowledge transfers from RGB to DVS often underperform because the distribution gap between modalities is substantial. In this work, we present Time-step Mixup Knowledge Transfer (TMKT), a cross-modal training framework with a probabilistic Time-step Mixup (TSM) strategy. TSM exploits the asynchronous nature of SNNs by interpolating RGB and DVS inputs at various time steps to produce a smooth curriculum within each sequence, which reduces gradient variance and stabilizes optimization with theoretical analysis. To employ auxiliary supervision from TSM, TMKT introduces two lightweight modality-aware objectives, Modality Aware Guidance (MAG) for per-frame source supervision and Mixup Ratio Perception (MRP) for sequence-level mix ratio estimation, which explicitly align temporal features with the mixing schedule. TMKT enables smoother knowledge transfer, helps mitigate modality mismatch during training, and achieves superior performance in spiking image classification tasks. Extensive experiments across diverse benchmarks and multiple SNN backbones, together with ablations, demonstrate the effectiveness of our method.
Time-step Mixup for Efficient Spiking Knowledge Transfer from Appearance to Event Domain
Sep 16, 2025The integration of event cameras and spiking neural networks holds great promise for energy-efficient visual processing. However, the limited availability of event data and the sparse nature of DVS outputs pose challenges for effective training. Although some prior work has attempted to transfer semantic knowledge from RGB datasets to DVS, they often overlook the significant distribution gap between the two modalities. In this paper, we propose Time-step Mixup knowledge transfer (TMKT), a novel fine-grained mixing strategy that exploits the asynchronous nature of SNNs by interpolating RGB and DVS inputs at various time-steps. To enable label mixing in cross-modal scenarios, we further introduce modality-aware auxiliary learning objectives. These objectives support the time-step mixup process and enhance the model's ability to discriminate effectively across different modalities. Our approach enables smoother knowledge transfer, alleviates modality shift during training, and achieves superior performance in spiking image classification tasks. Extensive experiments demonstrate the effectiveness of our method across multiple datasets. The code will be released after the double-blind review process.
DQEN: Dual Query Enhancement Network for DETR-based HOI Detection
Aug 26, 2025Human-Object Interaction (HOI) detection focuses on localizing human-object pairs and recognizing their interactions. Recently, the DETR-based framework has been widely adopted in HOI detection. In DETR-based HOI models, queries with clear meaning are crucial for accurately detecting HOIs. However, prior works have typically relied on randomly initialized queries, leading to vague representations that limit the model's effectiveness. Meanwhile, humans in the HOI categories are fixed, while objects and their interactions are variable. Therefore, we propose a Dual Query Enhancement Network (DQEN) to enhance object and interaction queries. Specifically, object queries are enhanced with object-aware encoder features, enabling the model to focus more effectively on humans interacting with objects in an object-aware way. On the other hand, we design a novel Interaction Semantic Fusion module to exploit the HOI candidates that are promoted by the CLIP model. Semantic features are extracted to enhance the initialization of interaction queries, thereby improving the model's ability to understand interactions. Furthermore, we introduce an Auxiliary Prediction Unit aimed at improving the representation of interaction features. Our proposed method achieves competitive performance on both the HICO-Det and the V-COCO datasets. The source code is available at https://github.com/lzzhhh1019/DQEN.
GV-VAD : Exploring Video Generation for Weakly-Supervised Video Anomaly Detection
Aug 01, 2025Video anomaly detection (VAD) plays a critical role in public safety applications such as intelligent surveillance. However, the rarity, unpredictability, and high annotation cost of real-world anomalies make it difficult to scale VAD datasets, which limits the performance and generalization ability of existing models. To address this challenge, we propose a generative video-enhanced weakly-supervised video anomaly detection (GV-VAD) framework that leverages text-conditioned video generation models to produce semantically controllable and physically plausible synthetic videos. These virtual videos are used to augment training data at low cost. In addition, a synthetic sample loss scaling strategy is utilized to control the influence of generated synthetic samples for efficient training. The experiments show that the proposed framework outperforms state-of-the-art methods on UCF-Crime datasets. The code is available at https://github.com/Sumutan/GV-VAD.git.
UCF-Crime-DVS: A Novel Event-Based Dataset for Video Anomaly Detection with Spiking Neural Networks
Mar 17, 2025Video anomaly detection plays a significant role in intelligent surveillance systems. To enhance model's anomaly recognition ability, previous works have typically involved RGB, optical flow, and text features. Recently, dynamic vision sensors (DVS) have emerged as a promising technology, which capture visual information as discrete events with a very high dynamic range and temporal resolution. It reduces data redundancy and enhances the capture capacity of moving objects compared to conventional camera. To introduce this rich dynamic information into the surveillance field, we created the first DVS video anomaly detection benchmark, namely UCF-Crime-DVS. To fully utilize this new data modality, a multi-scale spiking fusion network (MSF) is designed based on spiking neural networks (SNNs). This work explores the potential application of dynamic information from event data in video anomaly detection. Our experiments demonstrate the effectiveness of our framework on UCF-Crime-DVS and its superior performance compared to other models, establishing a new baseline for SNN-based weakly supervised video anomaly detection.
Zero-Shot Hashing Based on Reconstruction With Part Alignment
Mar 10, 2025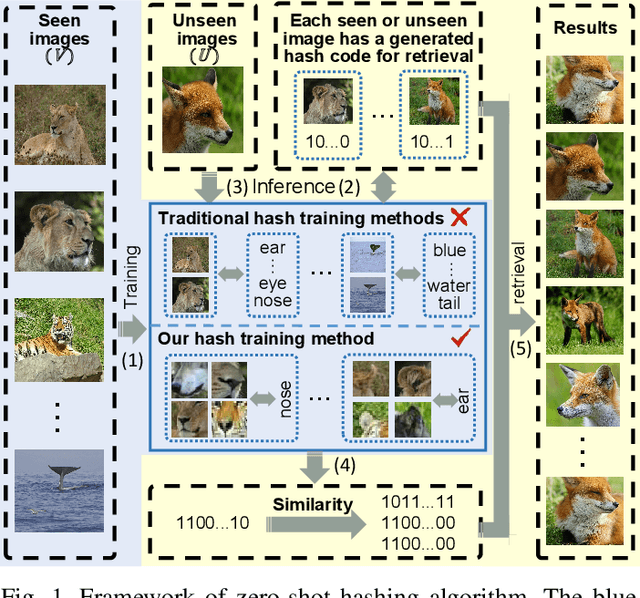
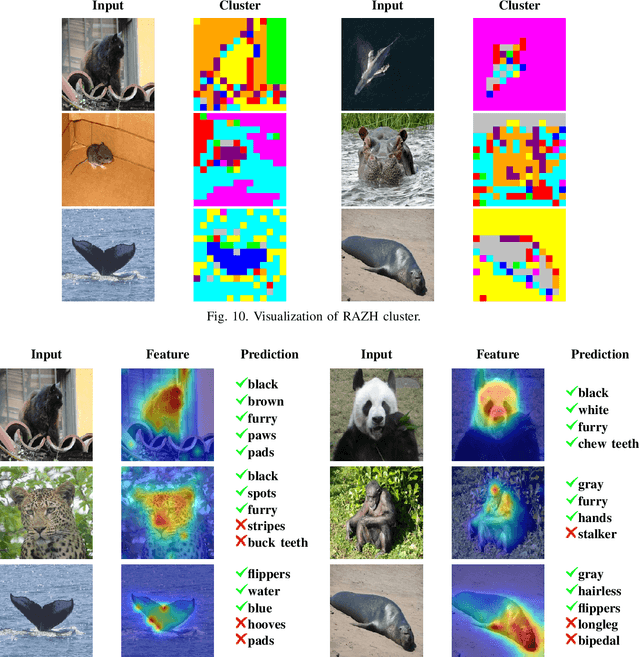
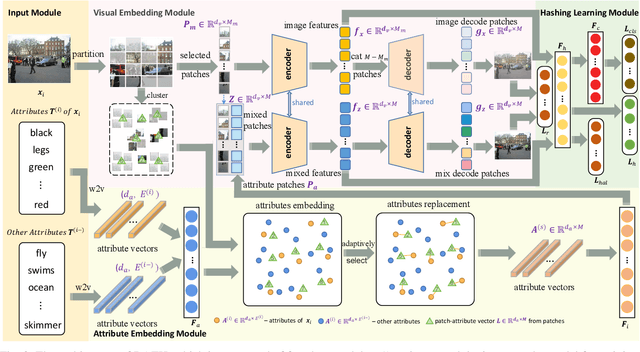
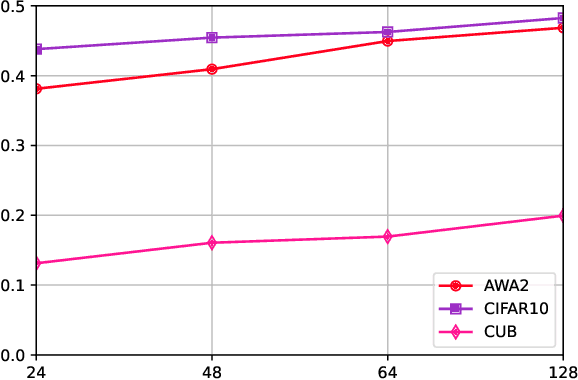
Hashing algorithms have been widely used in large-scale image retrieval tasks, especially for seen class data. Zero-shot hashing algorithms have been proposed to handle unseen class data. The key technique in these algorithms involves learning features from seen classes and transferring them to unseen classes, that is, aligning the feature embeddings between the seen and unseen classes. Most existing zero-shot hashing algorithms use the shared attributes between the two classes of interest to complete alignment tasks. However, the attributes are always described for a whole image, even though they represent specific parts of the image. Hence, these methods ignore the importance of aligning attributes with the corresponding image parts, which explicitly introduces noise and reduces the accuracy achieved when aligning the features of seen and unseen classes. To address this problem, we propose a new zero-shot hashing method called RAZH. We first use a clustering algorithm to group similar patches to image parts for attribute matching and then replace the image parts with the corresponding attribute vectors, gradually aligning each part with its nearest attribute. Extensive evaluation results demonstrate the superiority of the RAZH method over several state-of-the-art methods.
Temporal-Aware Spiking Transformer Hashing Based on 3D-DWT
Jan 12, 2025With the rapid growth of dynamic vision sensor (DVS) data, constructing a low-energy, efficient data retrieval system has become an urgent task. Hash learning is one of the most important retrieval technologies which can keep the distance between hash codes consistent with the distance between DVS data. As spiking neural networks (SNNs) can encode information through spikes, they demonstrate great potential in promoting energy efficiency. Based on the binary characteristics of SNNs, we first propose a novel supervised hashing method named Spikinghash with a hierarchical lightweight structure. Spiking WaveMixer (SWM) is deployed in shallow layers, utilizing a multilevel 3D discrete wavelet transform (3D-DWT) to decouple spatiotemporal features into various low-frequency and high frequency components, and then employing efficient spectral feature fusion. SWM can effectively capture the temporal dependencies and local spatial features. Spiking Self-Attention (SSA) is deployed in deeper layers to further extract global spatiotemporal information. We also design a hash layer utilizing binary characteristic of SNNs, which integrates information over multiple time steps to generate final hash codes. Furthermore, we propose a new dynamic soft similarity loss for SNNs, which utilizes membrane potentials to construct a learnable similarity matrix as soft labels to fully capture the similarity differences between classes and compensate information loss in SNNs, thereby improving retrieval performance. Experiments on multiple datasets demonstrate that Spikinghash can achieve state-of-the-art results with low energy consumption and fewer parameters.
Learn Suspected Anomalies from Event Prompts for Video Anomaly Detection
Mar 02, 2024Most models for weakly supervised video anomaly detection (WS-VAD) rely on multiple instance learning, aiming to distinguish normal and abnormal snippets without specifying the type of anomaly. The ambiguous nature of anomaly definitions across contexts introduces bias in detecting abnormal and normal snippets within the abnormal bag. Taking the first step to show the model why it is anomalous, a novel framework is proposed to guide the learning of suspected anomalies from event prompts. Given a textual prompt dictionary of potential anomaly events and the captions generated from anomaly videos, the semantic anomaly similarity between them could be calculated to identify the suspected anomalous events for each video snippet. It enables a new multi-prompt learning process to constrain the visual-semantic features across all videos, as well as provides a new way to label pseudo anomalies for self-training. To demonstrate effectiveness, comprehensive experiments and detailed ablation studies are conducted on four datasets, namely XD-Violence, UCF-Crime, TAD, and ShanghaiTech. Our proposed model outperforms most state-of-the-art methods in terms of AP or AUC (82.6\%, 87.7\%, 93.1\%, and 97.4\%). Furthermore, it shows promising performance in open-set and cross-dataset cases.
Split Two-Tower Model for Efficient and Privacy-Preserving Cross-device Federated Recommendation
Jun 28, 2022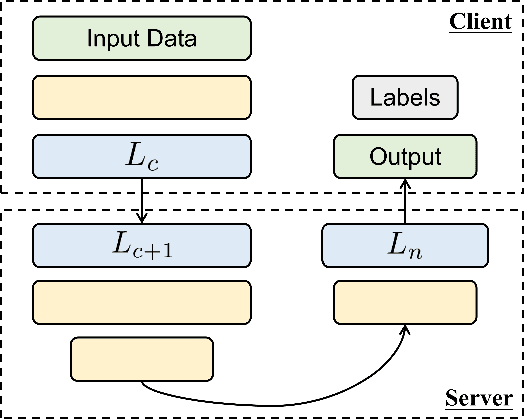

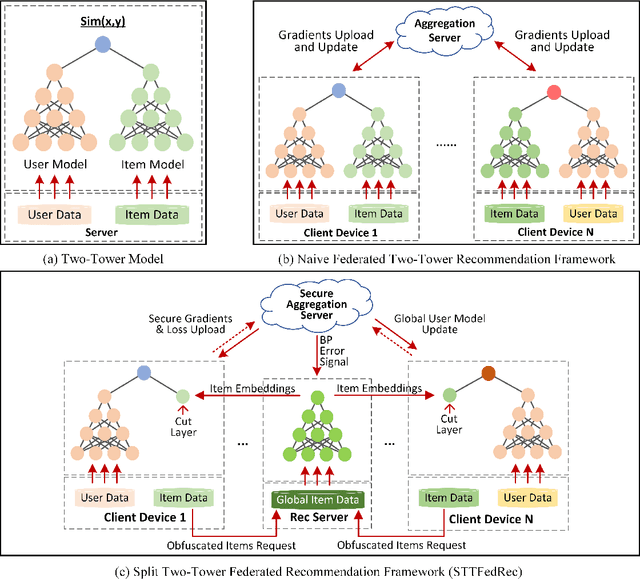
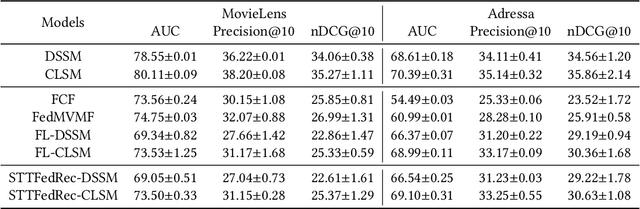
Federated Recommendation can mitigate the systematical privacy risks of traditional recommendation since it allows the model training and online inferring without centralized user data collection. Most existing works assume that all user devices are available and adequate to participate in the Federated Learning. However, in practice, the complex recommendation models designed for accurate prediction and massive item data cause a high computation and communication cost to the resource-constrained user device, resulting in poor performance or training failure. Therefore, how to effectively compress the computation and communication overhead to achieve efficient federated recommendations across ubiquitous mobile devices remains a significant challenge. This paper introduces split learning into the two-tower recommendation models and proposes STTFedRec, a privacy-preserving and efficient cross-device federated recommendation framework. STTFedRec achieves local computation reduction by splitting the training and computation of the item model from user devices to a performance-powered server. The server with the item model provides low-dimensional item embeddings instead of raw item data to the user devices for local training and online inferring, achieving server broadcast compression. The user devices only need to perform similarity calculations with cached user embeddings to achieve efficient online inferring. We also propose an obfuscated item request strategy and multi-party circular secret sharing chain to enhance the privacy protection of model training. The experiments conducted on two public datasets demonstrate that STTFedRec improves the average computation time and communication size of the baseline models by about 40 times and 42 times in the best-case scenario with balanced recommendation accuracy.