 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Flat Sequence: Hierarchical and Preference-Aware Generative Recommendations
Mar 01, 2026Generative Recommenders (GRs), exemplified by the Hierarchical Sequential Transduction Unit (HSTU), have emerged as a powerful paradigm for modeling long user interaction sequences. However, we observe that their "flat-sequence" assumption overlooks the rich, intrinsic structure of user behavior. This leads to two key limitations: a failure to capture the temporal hierarchy of session-based engagement, and computational inefficiency, as dense attention introduces significant noise that obscures true preference signals within semantically sparse histories, which deteriorates the quality of the learned representations. To this end, we propose a novel framework named HPGR (Hierarchical and Preference-aware Generative Recommender), built upon a two-stage paradigm that injects these crucial structural priors into the model to handle the drawback. Specifically, HPGR comprises two synergistic stages. First, a structure-aware pre-training stage employs a session-based Masked Item Modeling (MIM) objective to learn a hierarchically-informed and semantically rich item representation space. Second, a preference-aware fine-tuning stage leverages these powerful representations to implement a Preference-Guided Sparse Attention mechanism, which dynamically constrains computation to only the most relevant historical items, enhancing both efficiency and signal-to-noise ratio. Empirical experiments on a large-scale proprietary industrial dataset from APPGallery and an online A/B test verify that HPGR achieves state-of-the-art performance over multiple strong baselines, including HSTU and MTGR.
* Accepted to the ACM Web Conference 2026 (WWW '26). 9 pages, 9 figures. Zerui Chen and Heng Chang contributed equally to this work
Towards Practical Large-scale Dynamical Heterogeneous Graph Embedding: Cold-start Resilient Recommendation
Dec 15, 2025Deploying dynamic heterogeneous graph embeddings in production faces key challenges of scalability, data freshness, and cold-start. This paper introduces a practical, two-stage solution that balances deep graph representation with low-latency incremental updates. Our framework combines HetSGFormer, a scalable graph transformer for static learning, with Incremental Locally Linear Embedding (ILLE), a lightweight, CPU-based algorithm for real-time updates. HetSGFormer captures global structure with linear scalability, while ILLE provides rapid, targeted updates to incorporate new data, thus avoiding costly full retraining. This dual approach is cold-start resilient, leveraging the graph to create meaningful embeddings from sparse data. On billion-scale graphs, A/B tests show HetSGFormer achieved up to a 6.11% lift in Advertiser Value over previous methods, while the ILLE module added another 3.22% lift and improved embedding refresh timeliness by 83.2%. Our work provides a validated framework for deploying dynamic graph learning in production environments.
BIS: NL2SQL Service Evaluation Benchmark for Business Intelligence Scenarios
Oct 30, 2024



NL2SQL (Natural Language to Structured Query Language) transformation has seen wide adoption in Business Intelligence (BI) applications in recent years. However, existing NL2SQL benchmarks are not suitable for production BI scenarios, as they are not designed for common business intelligence questions. To address this gap, we have developed a new benchmark focused on typical NL questions in industrial BI scenarios. We discuss the challenges of constructing a BI-focused benchmark and the shortcomings of existing benchmarks. Additionally, we introduce question categories in our benchmark that reflect common BI inquiries. Lastly, we propose two novel semantic similarity evaluation metrics for assessing NL2SQL capabilities in BI applications and services.
P/D-Serve: Serving Disaggregated Large Language Model at Scale
Aug 15, 2024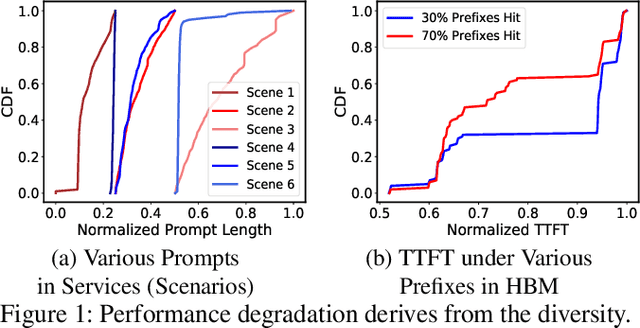
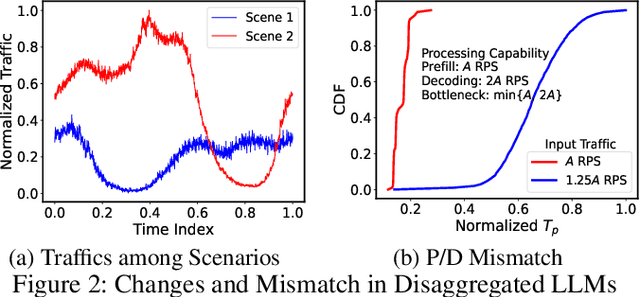
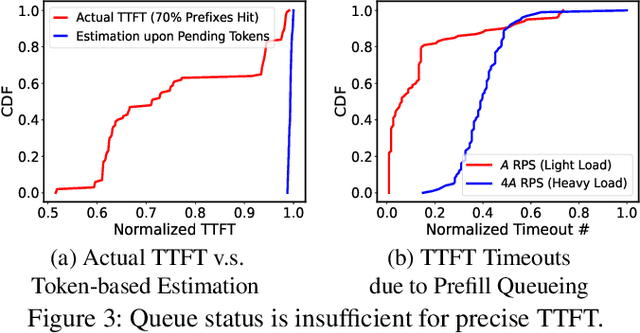
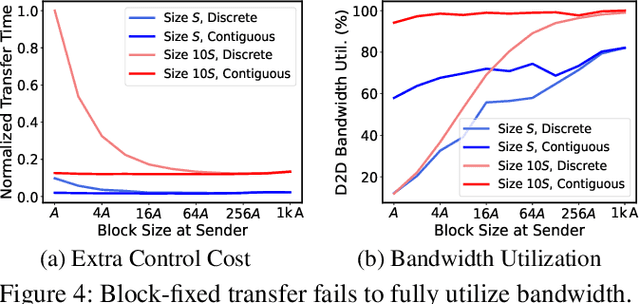
Serving disaggregated large language models (LLMs) over tens of thousands of xPU devices (GPUs or NPUs) with reliable performance faces multiple challenges. 1) Ignoring the diversity (various prefixes and tidal requests), treating all the prompts in a mixed pool is inadequate. To facilitate the similarity per scenario and minimize the inner mismatch on P/D (prefill and decoding) processing, fine-grained organization is required, dynamically adjusting P/D ratios for better performance. 2) Due to inaccurate estimation on workload (queue status or maintained connections), the global scheduler easily incurs unnecessary timeouts in prefill. 3) Block-fixed device-to-device (D2D) KVCache transfer over cluster-level RDMA (remote direct memory access) fails to achieve desired D2D utilization as expected. To overcome previous problems, this paper proposes an end-to-end system P/D-Serve, complying with the paradigm of MLOps (machine learning operations), which models end-to-end (E2E) P/D performance and enables: 1) fine-grained P/D organization, mapping the service with RoCE (RDMA over converged ethernet) as needed, to facilitate similar processing and dynamic adjustments on P/D ratios; 2) on-demand forwarding upon rejections for idle prefill, decoupling the scheduler from regular inaccurate reports and local queues, to avoid timeouts in prefill; and 3) efficient KVCache transfer via optimized D2D access. P/D-Serve is implemented upon Ascend and MindSpore, has been deployed over tens of thousands of NPUs for more than eight months in commercial use, and further achieves 60\%, 42\% and 46\% improvements on E2E throughput, time-to-first-token (TTFT) SLO (service level objective) and D2D transfer time. As the E2E system with optimizations, P/D-Serve achieves 6.7x increase on throughput, compared with aggregated LLMs.
Unified Low-rank Compression Framework for Click-through Rate Prediction
May 28, 2024



Deep Click-Through Rate (CTR) prediction models play an important role in modern industrial recommendation scenarios. However, high memory overhead and computational costs limit their deployment in resource-constrained environments. Low-rank approximation is an effective method for computer vision and natural language processing models, but its application in compressing CTR prediction models has been less explored. Due to the limited memory and computing resources, compression of CTR prediction models often confronts three fundamental challenges, i.e., (1). How to reduce the model sizes to adapt to edge devices? (2). How to speed up CTR prediction model inference? (3). How to retain the capabilities of original models after compression? Previous low-rank compression research mostly uses tensor decomposition, which can achieve a high parameter compression ratio, but brings in AUC degradation and additional computing overhead. To address these challenges, we propose a unified low-rank decomposition framework for compressing CTR prediction models. We find that even with the most classic matrix decomposition SVD method, our framework can achieve better performance than the original model. To further improve the effectiveness of our framework, we locally compress the output features instead of compressing the model weights. Our unified low-rank compression framework can be applied to embedding tables and MLP layers in various CTR prediction models. Extensive experiments on two academic datasets and one real industrial benchmark demonstrate that, with 3-5x model size reduction, our compressed models can achieve both faster inference and higher AUC than the uncompressed original models. Our code is at https://github.com/yuhao318/Atomic_Feature_Mimicking.
Continual Graph Convolutional Network for Text Classification
Apr 09, 2023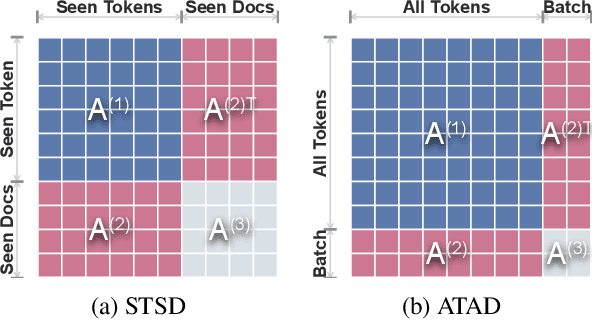
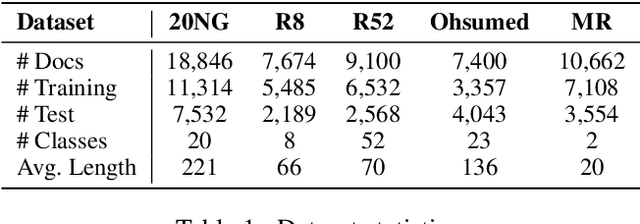
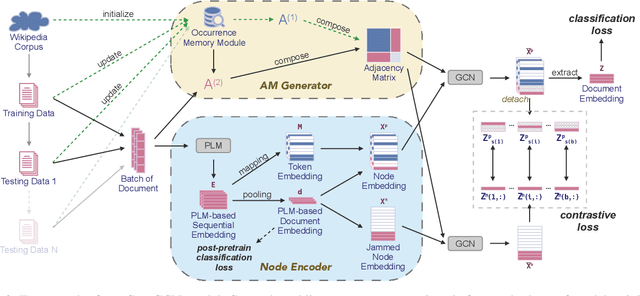
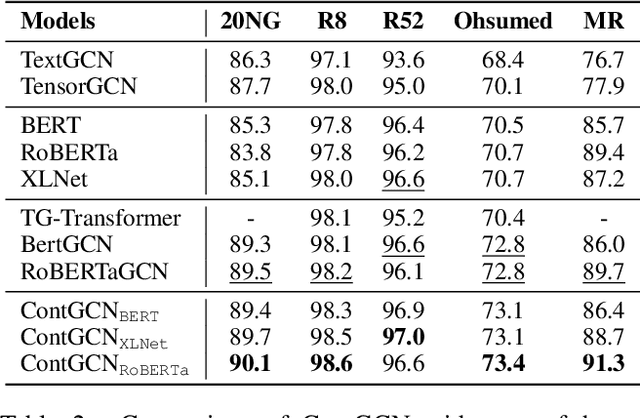
Graph convolutional network (GCN) has been successfully applied to capture global non-consecutive and long-distance semantic information for text classification. However, while GCN-based methods have shown promising results in offline evaluations, they commonly follow a seen-token-seen-document paradigm by constructing a fixed document-token graph and cannot make inferences on new documents. It is a challenge to deploy them in online systems to infer steaming text data. In this work, we present a continual GCN model (ContGCN) to generalize inferences from observed documents to unobserved documents. Concretely, we propose a new all-token-any-document paradigm to dynamically update the document-token graph in every batch during both the training and testing phases of an online system. Moreover, we design an occurrence memory module and a self-supervised contrastive learning objective to update ContGCN in a label-free manner. A 3-month A/B test on Huawei public opinion analysis system shows ContGCN achieves 8.86% performance gain compared with state-of-the-art methods. Offline experiments on five public datasets also show ContGCN can improve inference quality. The source code will be released at https://github.com/Jyonn/ContGCN.
EPiDA: An Easy Plug-in Data Augmentation Framework for High Performance Text Classification
Apr 24, 2022
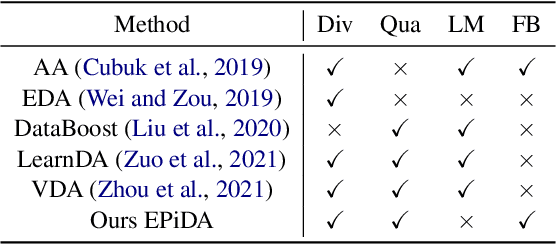

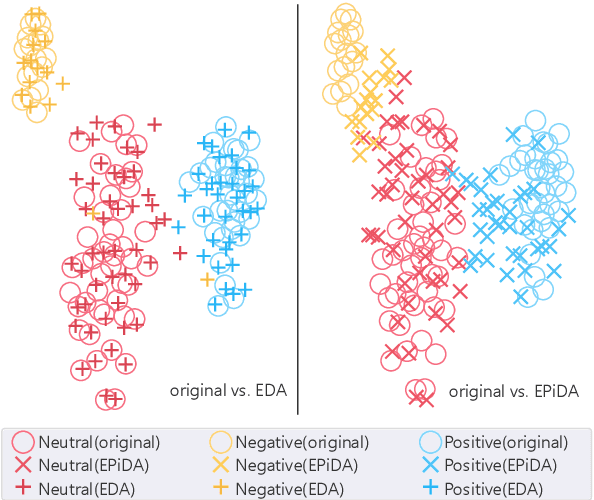
Recent works have empirically shown the effectiveness of data augmentation (DA) in NLP tasks, especially for those suffering from data scarcity. Intuitively, given the size of generated data, their diversity and quality are crucial to the performance of targeted tasks. However, to the best of our knowledge, most existing methods consider only either the diversity or the quality of augmented data, thus cannot fully mine the potential of DA for NLP. In this paper, we present an easy and plug-in data augmentation framework EPiDA to support effective text classification. EPiDA employs two mechanisms: relative entropy maximization (REM) and conditional entropy minimization (CEM) to control data generation, where REM is designed to enhance the diversity of augmented data while CEM is exploited to ensure their semantic consistency. EPiDA can support efficient and continuous data generation for effective classifier training. Extensive experiments show that EPiDA outperforms existing SOTA methods in most cases, though not using any agent networks or pre-trained generation networks, and it works well with various DA algorithms and classification models. Code is available at https://github.com/zhaominyiz/EPiDA.
DP-SSL: Towards Robust Semi-supervised Learning with A Few Labeled Samples
Oct 26, 2021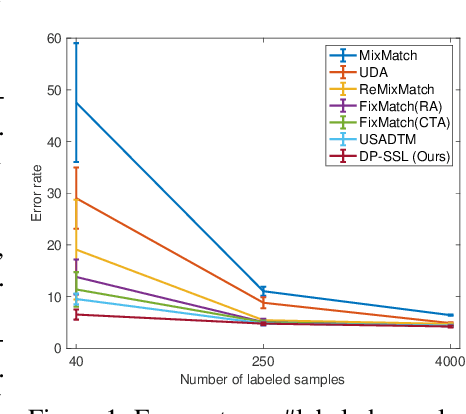
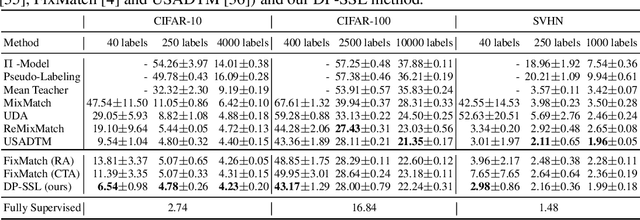
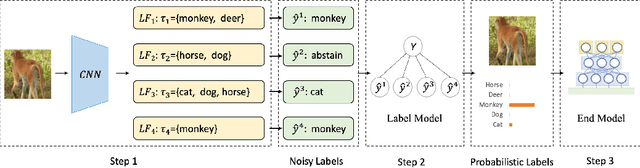

The scarcity of labeled data is a critical obstacle to deep learning. Semi-supervised learning (SSL) provides a promising way to leverage unlabeled data by pseudo labels. However, when the size of labeled data is very small (say a few labeled samples per class), SSL performs poorly and unstably, possibly due to the low quality of learned pseudo labels. In this paper, we propose a new SSL method called DP-SSL that adopts an innovative data programming (DP) scheme to generate probabilistic labels for unlabeled data. Different from existing DP methods that rely on human experts to provide initial labeling functions (LFs), we develop a multiple-choice learning~(MCL) based approach to automatically generate LFs from scratch in SSL style. With the noisy labels produced by the LFs, we design a label model to resolve the conflict and overlap among the noisy labels, and finally infer probabilistic labels for unlabeled samples. Extensive experiments on four standard SSL benchmarks show that DP-SSL can provide reliable labels for unlabeled data and achieve better classification performance on test sets than existing SSL methods, especially when only a small number of labeled samples are available. Concretely, for CIFAR-10 with only 40 labeled samples, DP-SSL achieves 93.82% annotation accuracy on unlabeled data and 93.46% classification accuracy on test data, which are higher than the SOTA results.
Weakly-supervised Text Classification Based on Keyword Graph
Oct 06, 2021

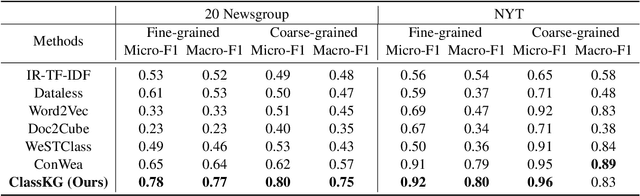
Weakly-supervised text classification has received much attention in recent years for it can alleviate the heavy burden of annotating massive data. Among them, keyword-driven methods are the mainstream where user-provided keywords are exploited to generate pseudo-labels for unlabeled texts. However, existing methods treat keywords independently, thus ignore the correlation among them, which should be useful if properly exploited. In this paper, we propose a novel framework called ClassKG to explore keyword-keyword correlation on keyword graph by GNN. Our framework is an iterative process. In each iteration, we first construct a keyword graph, so the task of assigning pseudo labels is transformed to annotating keyword subgraphs. To improve the annotation quality, we introduce a self-supervised task to pretrain a subgraph annotator, and then finetune it. With the pseudo labels generated by the subgraph annotator, we then train a text classifier to classify the unlabeled texts. Finally, we re-extract keywords from the classified texts. Extensive experiments on both long-text and short-text datasets show that our method substantially outperforms the existing ones