 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP/D-Serve: Serving Disaggregated Large Language Model at Scale
Aug 15, 2024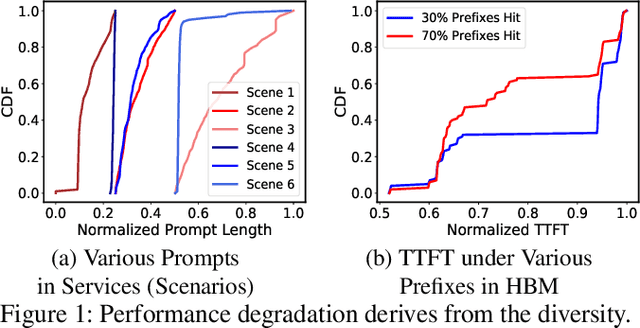
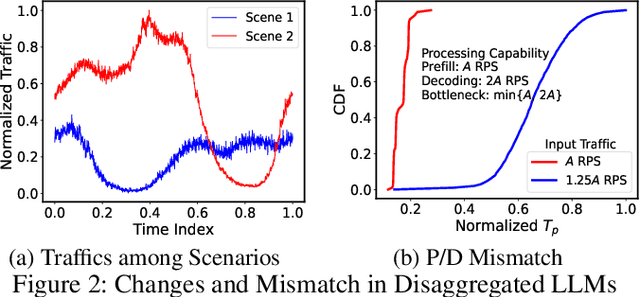
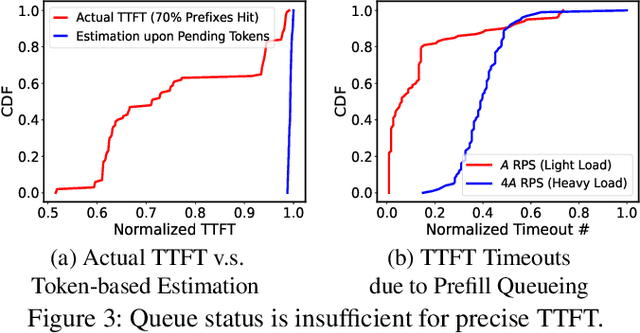
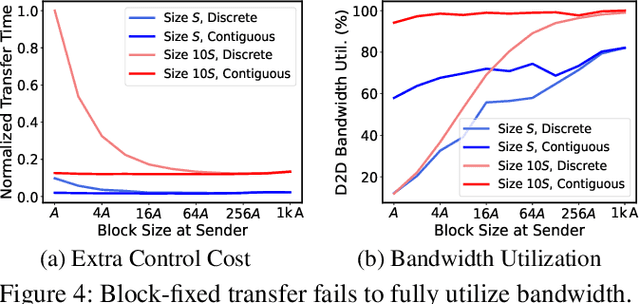
Serving disaggregated large language models (LLMs) over tens of thousands of xPU devices (GPUs or NPUs) with reliable performance faces multiple challenges. 1) Ignoring the diversity (various prefixes and tidal requests), treating all the prompts in a mixed pool is inadequate. To facilitate the similarity per scenario and minimize the inner mismatch on P/D (prefill and decoding) processing, fine-grained organization is required, dynamically adjusting P/D ratios for better performance. 2) Due to inaccurate estimation on workload (queue status or maintained connections), the global scheduler easily incurs unnecessary timeouts in prefill. 3) Block-fixed device-to-device (D2D) KVCache transfer over cluster-level RDMA (remote direct memory access) fails to achieve desired D2D utilization as expected. To overcome previous problems, this paper proposes an end-to-end system P/D-Serve, complying with the paradigm of MLOps (machine learning operations), which models end-to-end (E2E) P/D performance and enables: 1) fine-grained P/D organization, mapping the service with RoCE (RDMA over converged ethernet) as needed, to facilitate similar processing and dynamic adjustments on P/D ratios; 2) on-demand forwarding upon rejections for idle prefill, decoupling the scheduler from regular inaccurate reports and local queues, to avoid timeouts in prefill; and 3) efficient KVCache transfer via optimized D2D access. P/D-Serve is implemented upon Ascend and MindSpore, has been deployed over tens of thousands of NPUs for more than eight months in commercial use, and further achieves 60\%, 42\% and 46\% improvements on E2E throughput, time-to-first-token (TTFT) SLO (service level objective) and D2D transfer time. As the E2E system with optimizations, P/D-Serve achieves 6.7x increase on throughput, compared with aggregated LLMs.
Continual Graph Convolutional Network for Text Classification
Apr 09, 2023Graph convolutional network (GCN) has been successfully applied to capture global non-consecutive and long-distance semantic information for text classification. However, while GCN-based methods have shown promising results in offline evaluations, they commonly follow a seen-token-seen-document paradigm by constructing a fixed document-token graph and cannot make inferences on new documents. It is a challenge to deploy them in online systems to infer steaming text data. In this work, we present a continual GCN model (ContGCN) to generalize inferences from observed documents to unobserved documents. Concretely, we propose a new all-token-any-document paradigm to dynamically update the document-token graph in every batch during both the training and testing phases of an online system. Moreover, we design an occurrence memory module and a self-supervised contrastive learning objective to update ContGCN in a label-free manner. A 3-month A/B test on Huawei public opinion analysis system shows ContGCN achieves 8.86% performance gain compared with state-of-the-art methods. Offline experiments on five public datasets also show ContGCN can improve inference quality. The source code will be released at https://github.com/Jyonn/ContGCN.
FANS: Fast Non-Autoregressive Sequence Generation for Item List Continuation
Apr 02, 2023User-curated item lists, such as video-based playlists on Youtube and book-based lists on Goodreads, have become prevalent for content sharing on online platforms. Item list continuation is proposed to model the overall trend of a list and predict subsequent items. Recently, Transformer-based models have shown promise in comprehending contextual information and capturing item relationships in a list. However, deploying them in real-time industrial applications is challenging, mainly because the autoregressive generation mechanism used in them is time-consuming. In this paper, we propose a novel fast non-autoregressive sequence generation model, namely FANS, to enhance inference efficiency and quality for item list continuation. First, we use a non-autoregressive generation mechanism to decode next $K$ items simultaneously instead of one by one in existing models. Then, we design a two-stage classifier to replace the vanilla classifier used in current transformer-based models to further reduce the decoding time. Moreover, to improve the quality of non-autoregressive generation, we employ a curriculum learning strategy to optimize training. Experimental results on four real-world item list continuation datasets including Zhihu, Spotify, AotM, and Goodreads show that our FANS model can significantly improve inference efficiency (up to 8.7x) while achieving competitive or better generation quality for item list continuation compared with the state-of-the-art autoregressive models. We also validate the efficiency of FANS in an industrial setting. Our source code and data will be available at MindSpore/models and Github.